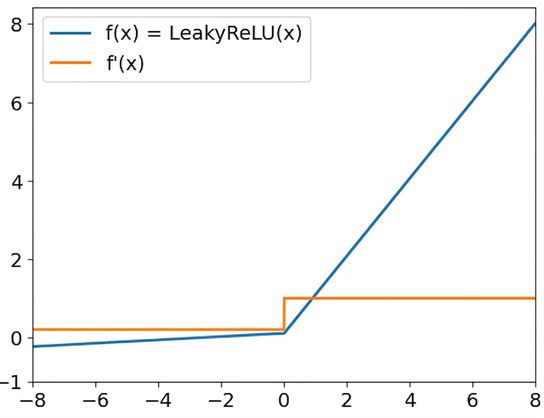
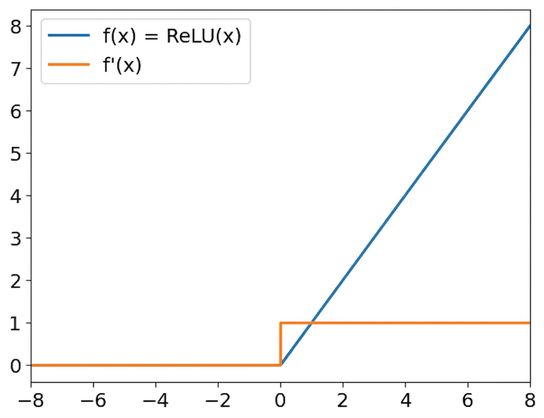
Fonctions d’activation ReLU
Introduction au Deep Learning avec PyTorch

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
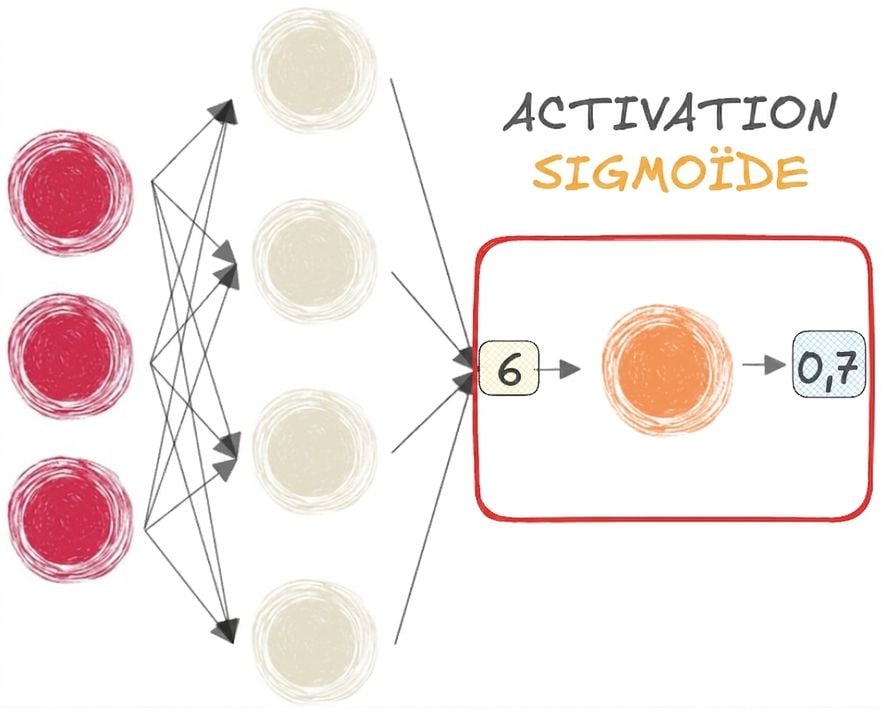
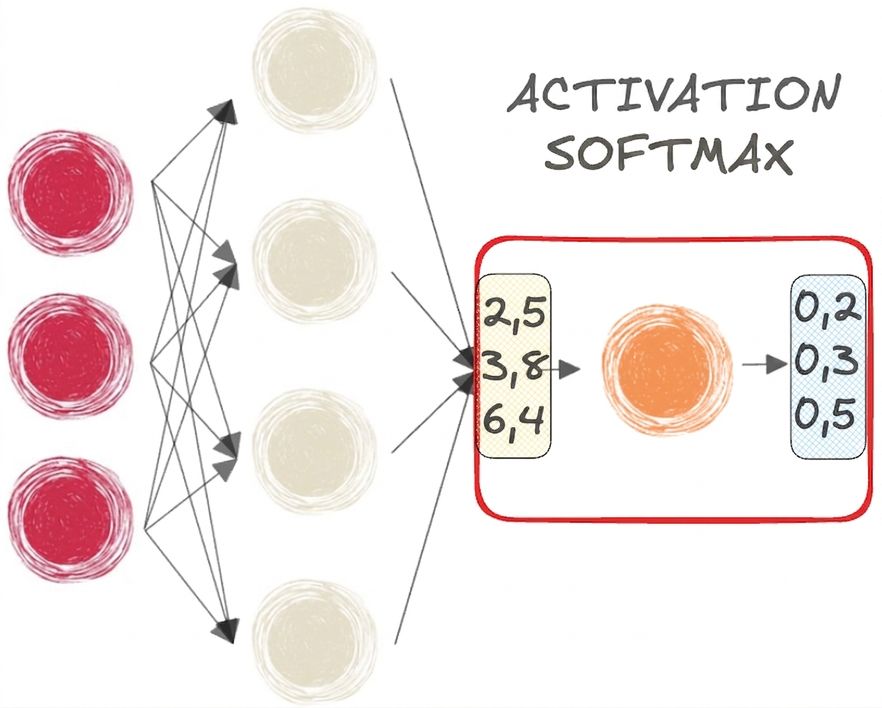
Fonctions sigmoïde et softmax
$$
- SIGMOÏDE pour la classification BINAIRE
$$
- SOFTMAX pour la classification MULTI-CLASSE
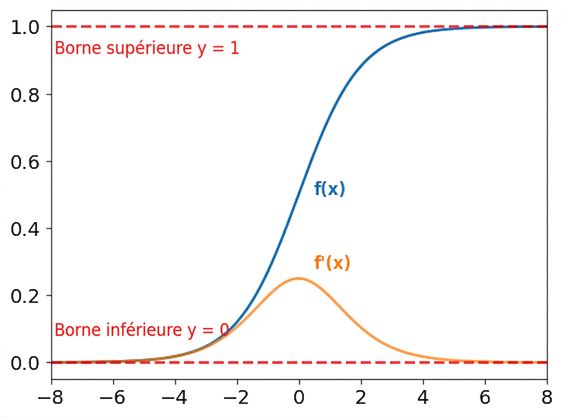
Limites des fonctions sigmoïde et softmax
ReLU
Leaky ReLU