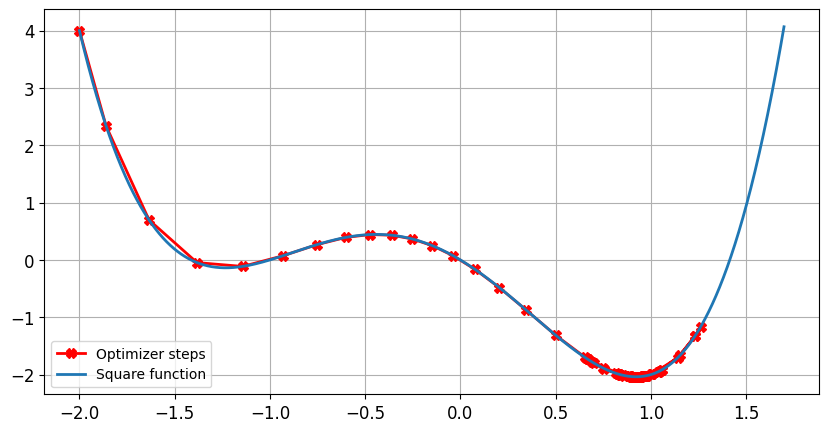
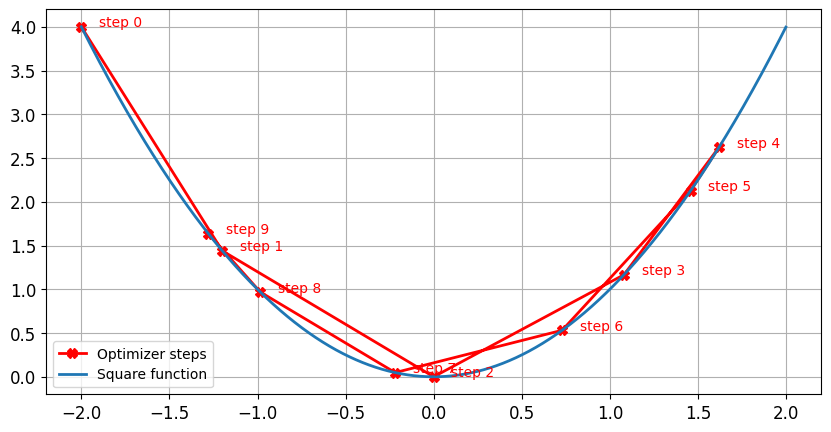
Taux d’apprentissage et dynamique
Introduction au deep learning avec PyTorch

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
Impact du taux d’apprentissage : taux d’apprentissage optimal

- La taille du pas diminue près de zéro à mesure que le gradient devient plus petit
Impact du taux d’apprentissage : taux d’apprentissage faible

Impact du taux d’apprentissage : taux d’apprentissage élevé
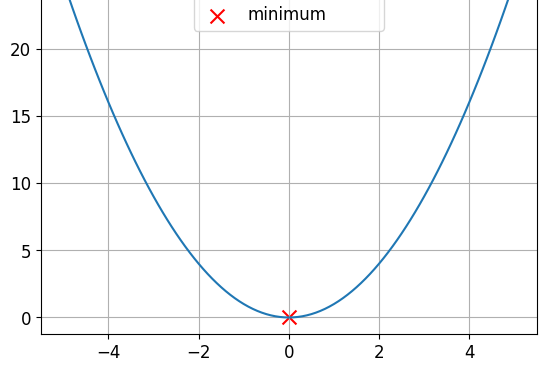
Fonctions convexes et non convexes
Il s’agit d’une fonction convexe.
Il s’agit d’une fonction non convexe.
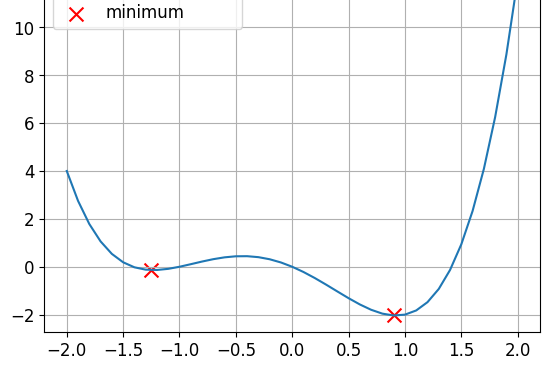
- Les fonctions de perte ne sont pas convexes
Sans momentum
lr = 0.01momentum = 0Après 100 étapes, le minimum est trouvé pourx = -1.23ety = -0.14
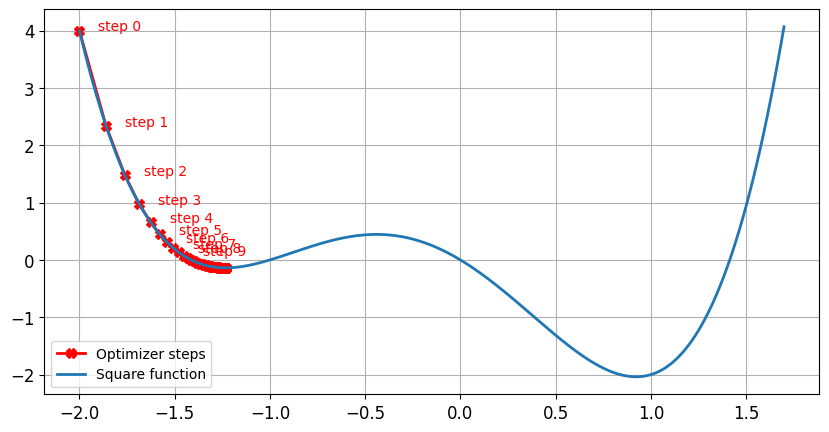
Avec momentum
lr = 0.01momentum = 0.9Après 100 étapes, le minimum est trouvé pourx = 0.92ety = -2.04