Mise à jour des paramètres à l’aide des dérivées
Introduction au deep learning avec PyTorch

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
Une analogie pour les dérivées
$$

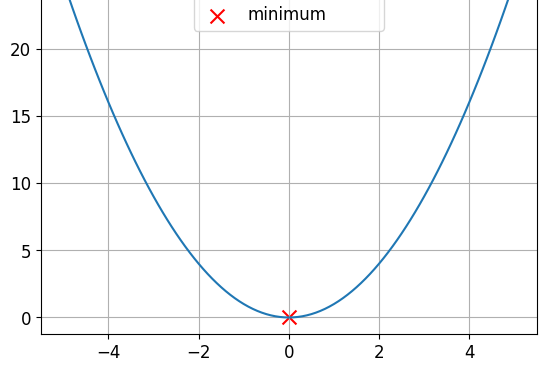
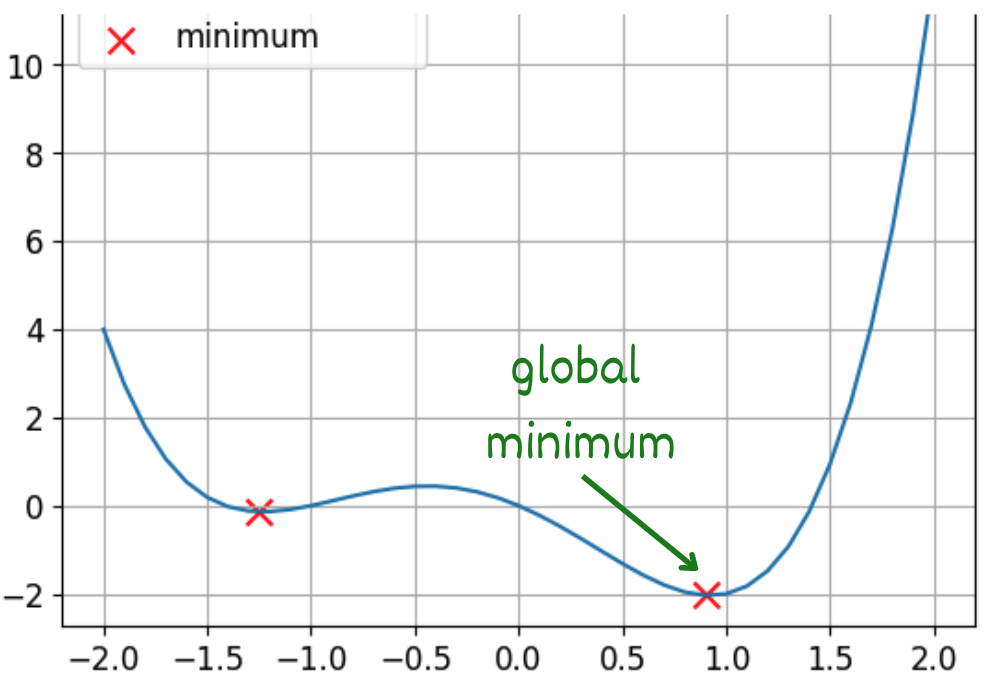
Fonctions convexes et non convexes
Il s’agit d’une fonction convexe
Il s’agit d’une fonction non convexe
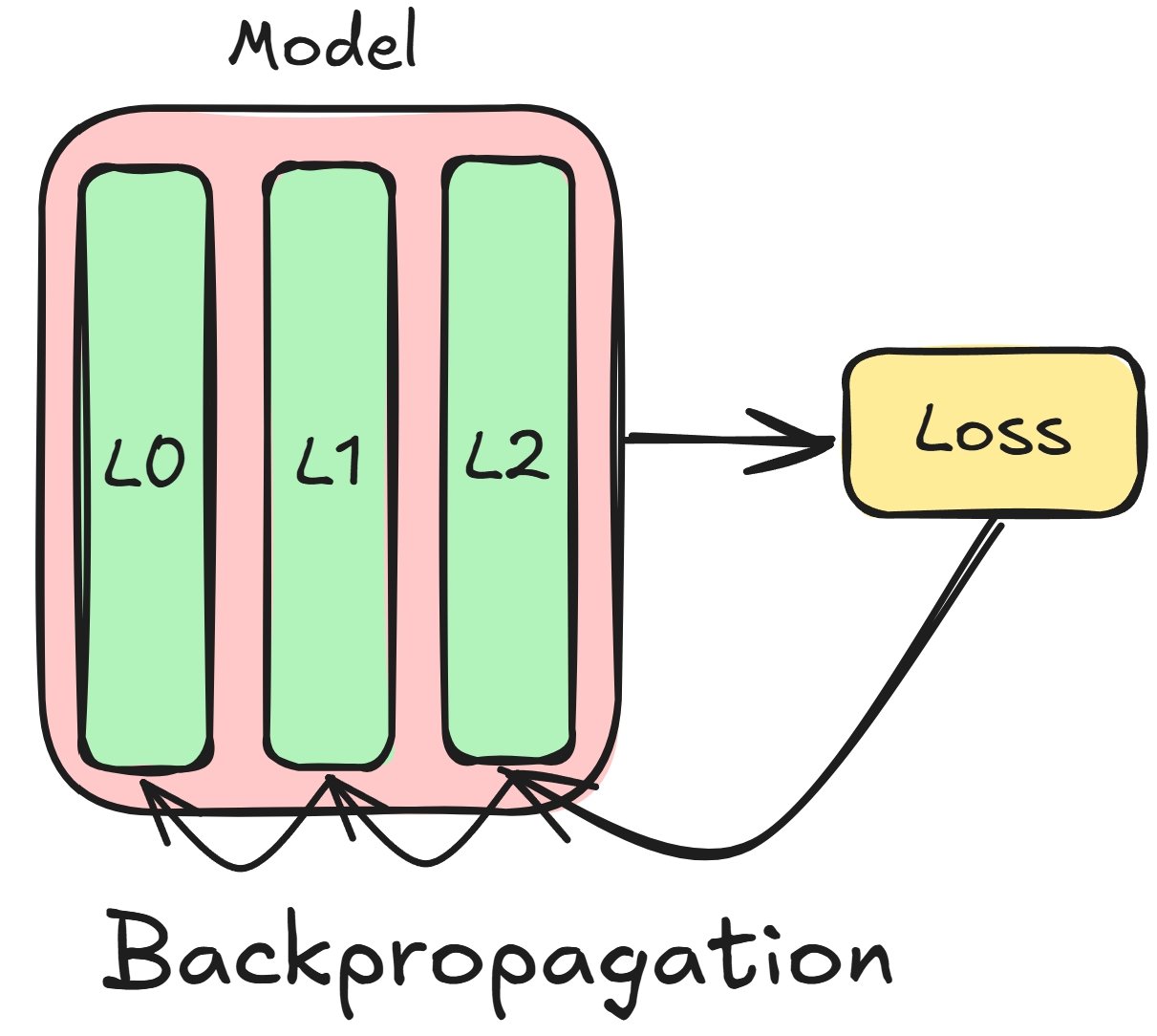
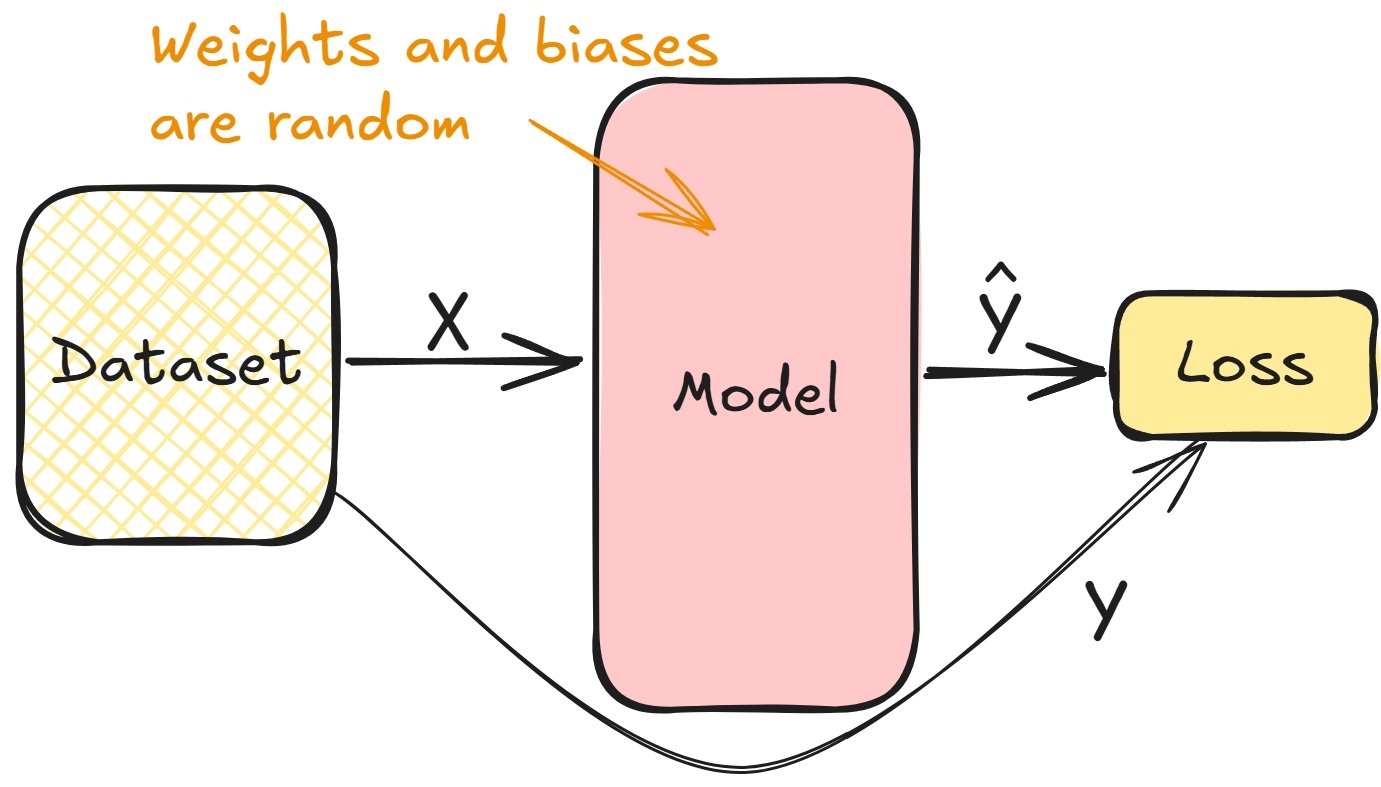
Relier les dérivées et l’entraînement du modèle
- Calculer la perte lors du passage avant pendant l’entraînement
$$
Relier les dérivées et l’entraînement du modèle
- Les gradients permettent de minimiser la perte, d’ajuster les poids des couches et les biais
- Répétez l’opération jusqu’à ce que les couches soient ajustées
$$
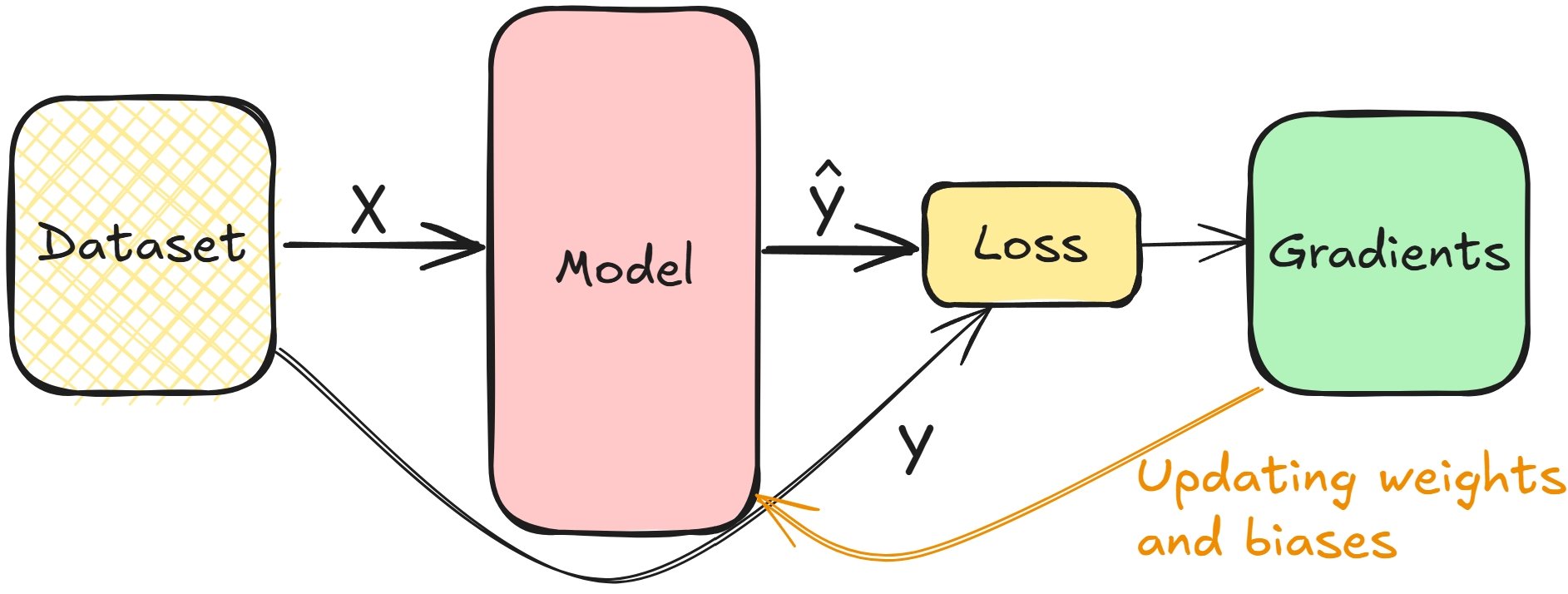
Concepts de rétropropagation