Carga
Introducción a la ingeniería de datos

Vincent Vankrunkelsven
Data Engineer @ DataCamp
Bases de datos para analítica o aplicaciones
Analítica

- Consultas agregadas
- Procesamiento analítico en línea (OLAP)
Aplicaciones

- Muchas transacciones
- Procesamiento de transacciones en línea (OLTP)
Orientación por columnas y por filas
Analítica
- Orientada a columnas
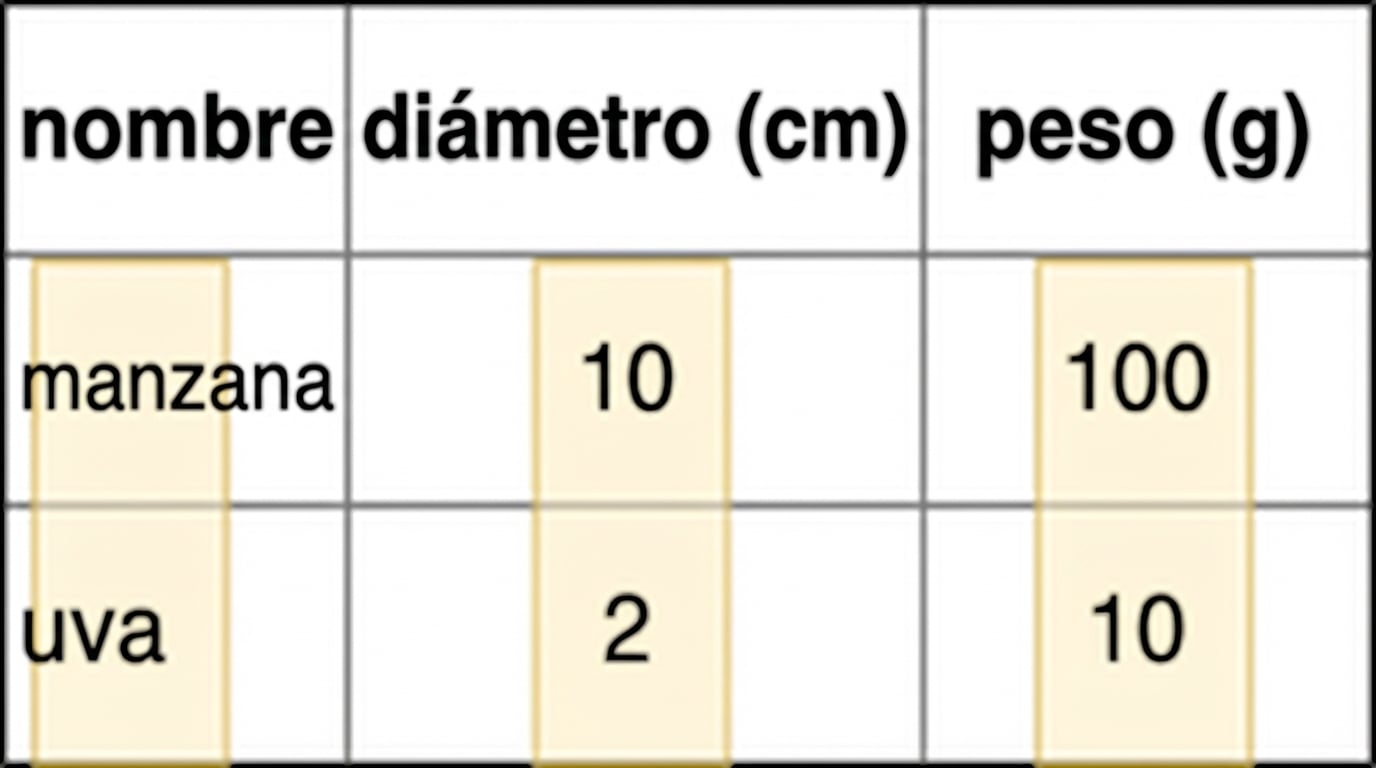
- Consultas sobre subconjunto de columnas
- Paralelización
Aplicaciones
- Orientada a filas
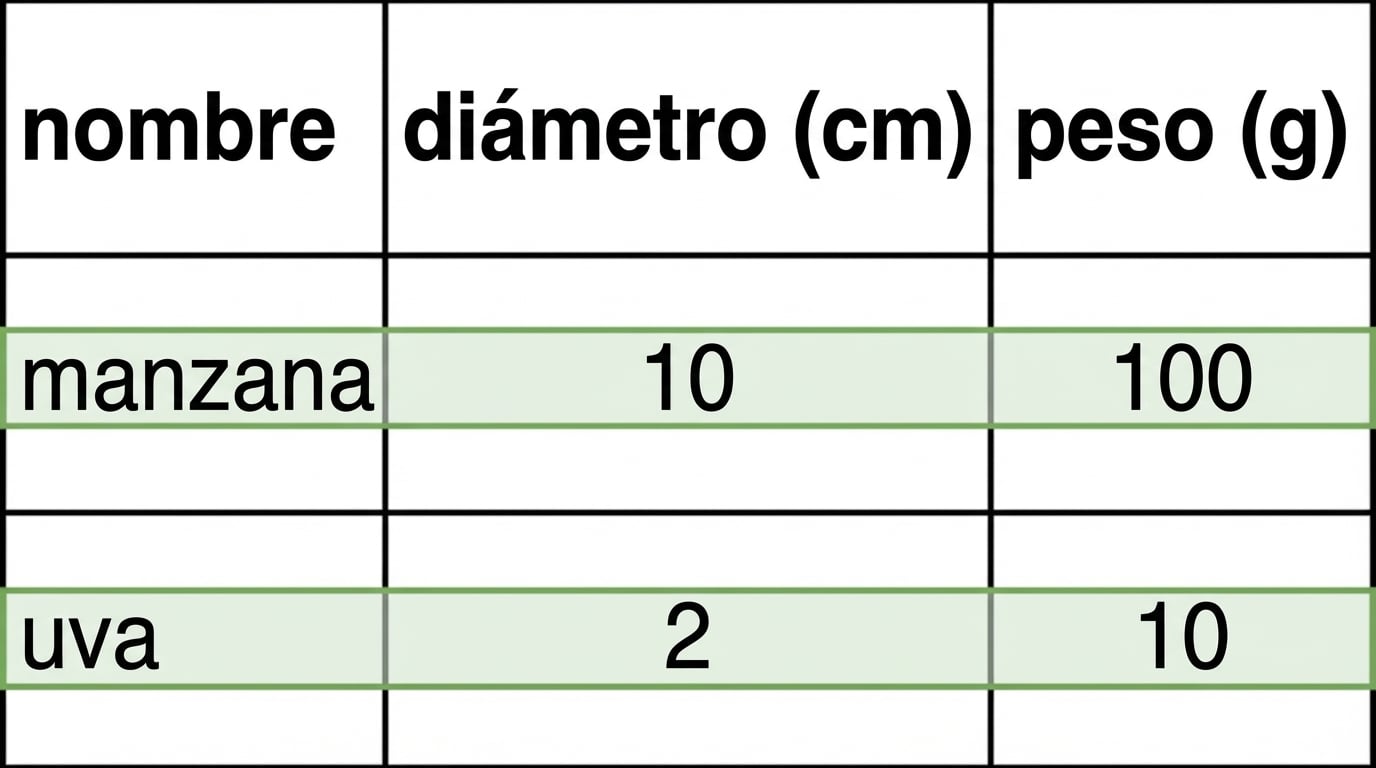
- Almacenada por registro
- Añadida por transacción
- P. ej., añadir un cliente es rápido
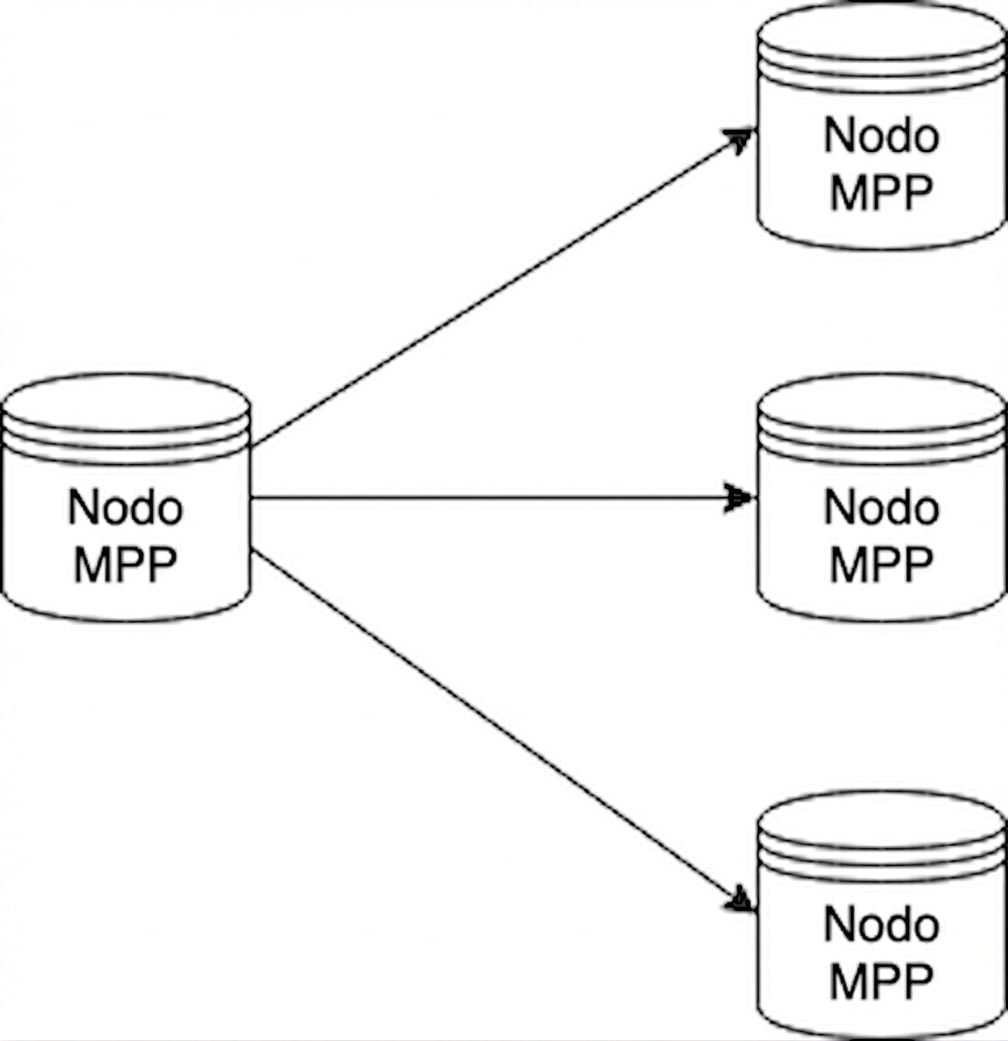
Bases de datos MPP
Bases de datos de procesamiento masivo en paralelo