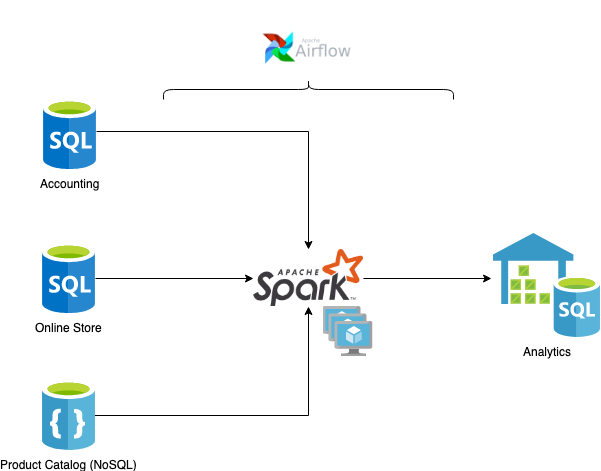
Tools of the data engineer
Introduction to Data Engineering

Vincent Vankrunkelsven
Data Engineer @ DataCamp
Databases


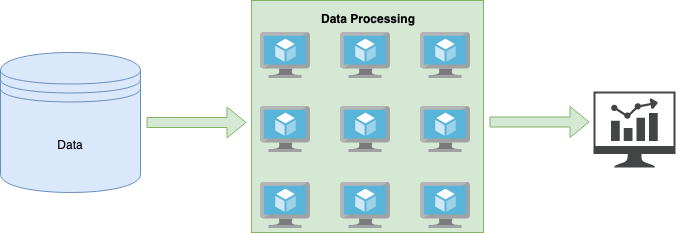
Processing
Scheduling
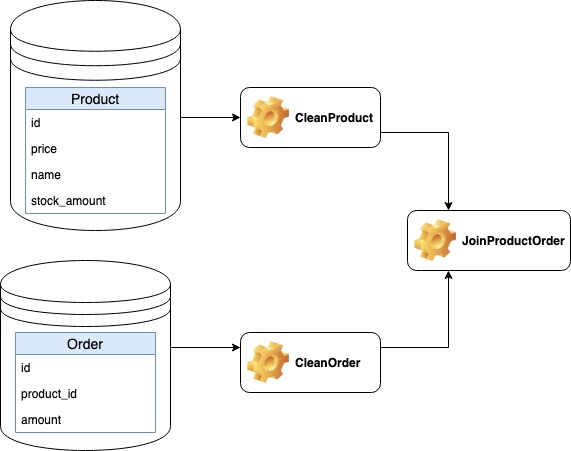
JoinProductOrder needs to run after CleanProduct and CleanOrder
Existing tools
Databases


Processing
![]()
![]()
Scheduling
![]()
![]()

A data pipeline