Marcos de computación en paralelo
Introducción a la ingeniería de datos

Vincent Vankrunkelsven
Data Engineer @ DataCamp
![]()
HDFS
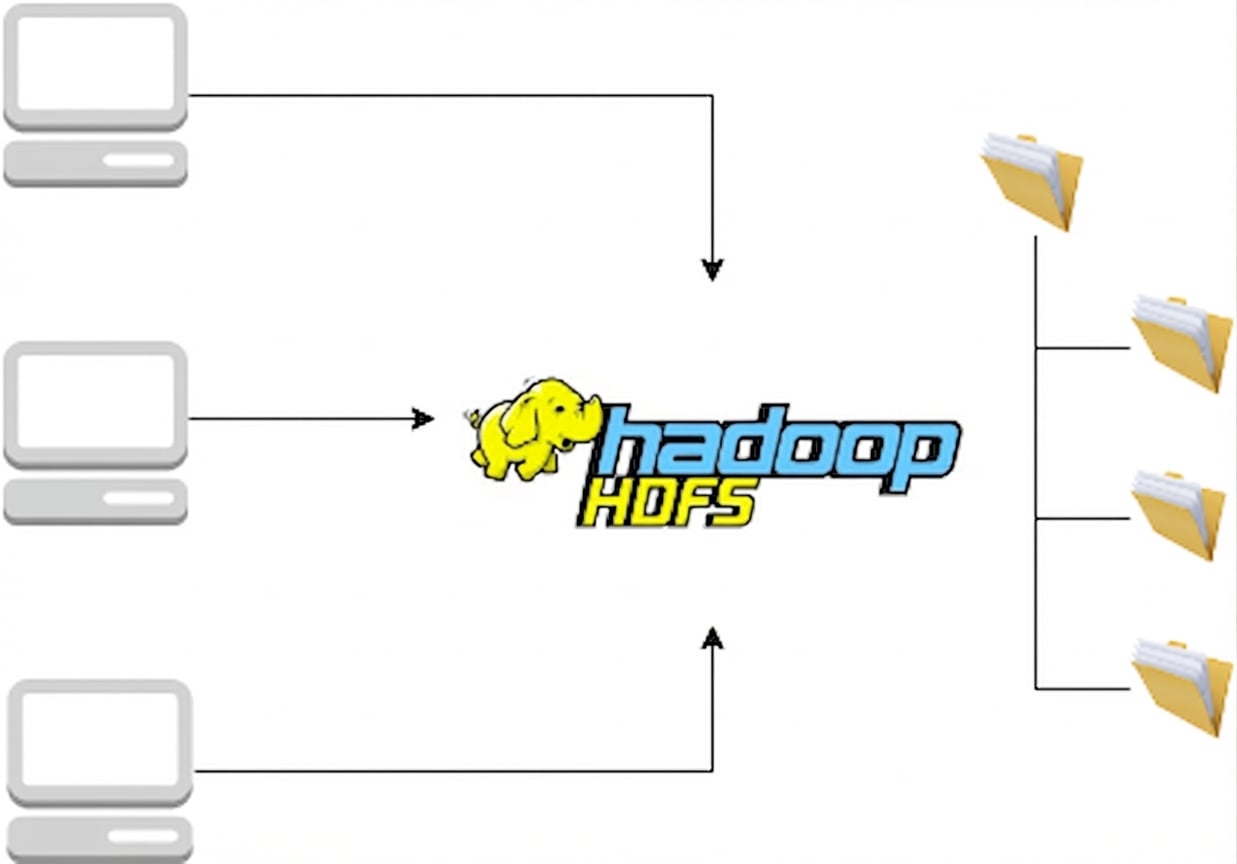
MapReduce
![]()
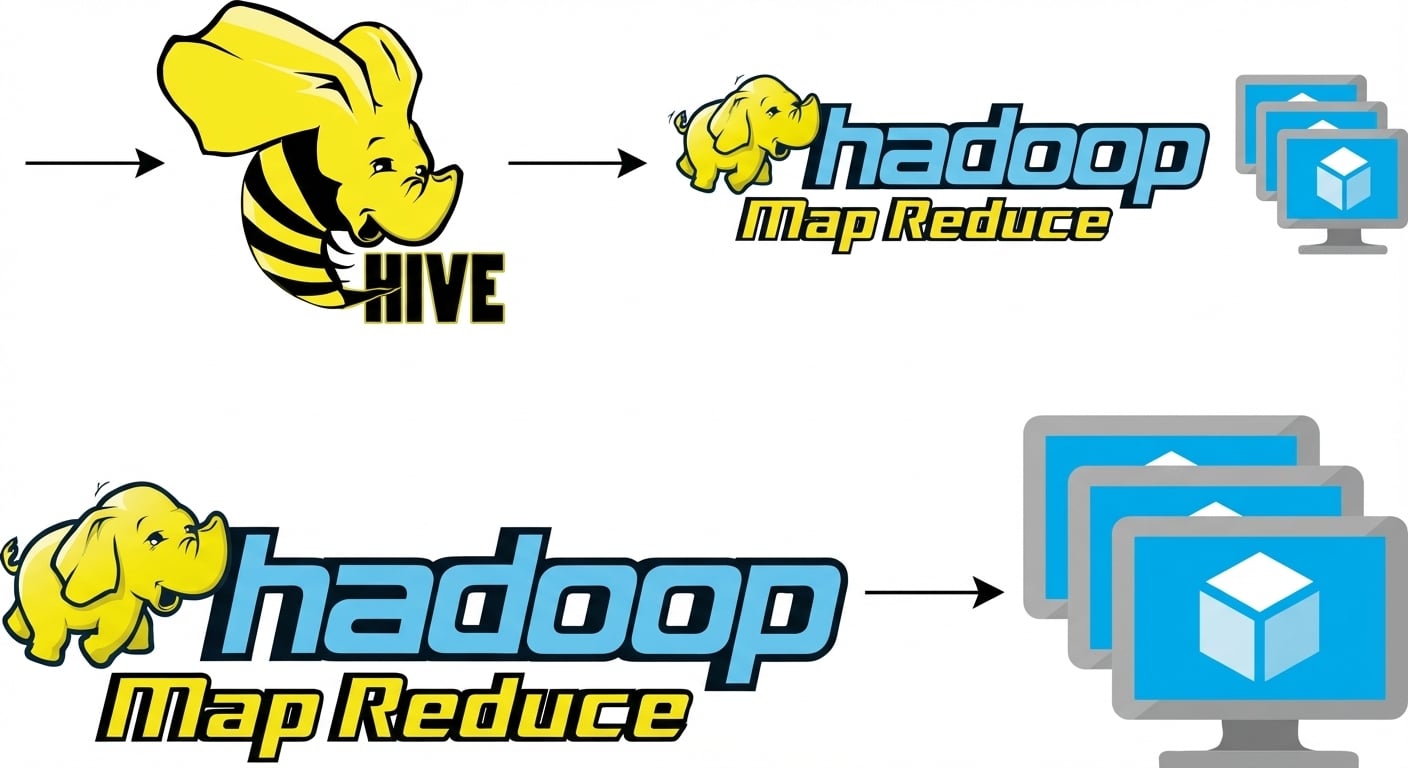
Hive
- Se ejecuta en Hadoop
- Lenguaje SQL: Hive SQL
- Antes MapReduce; ahora también otras herramientas
![]()
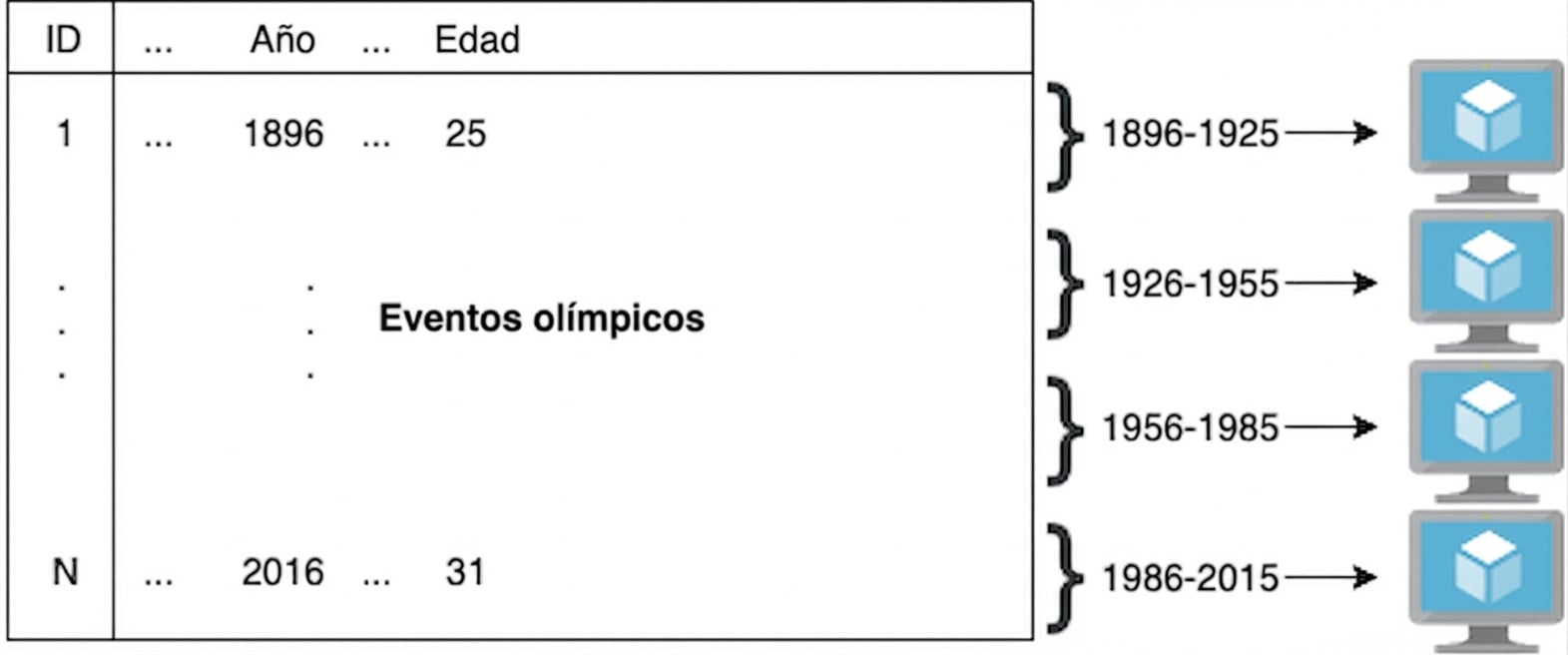
Hive: un ejemplo
![]()
- Evita escrituras en disco
- Mantenido por la Apache Software Foundation

