Qué es la computación paralela
Introducción a la ingeniería de datos

Vincent Vankrunkelsven
Data Engineer @ DataCamp
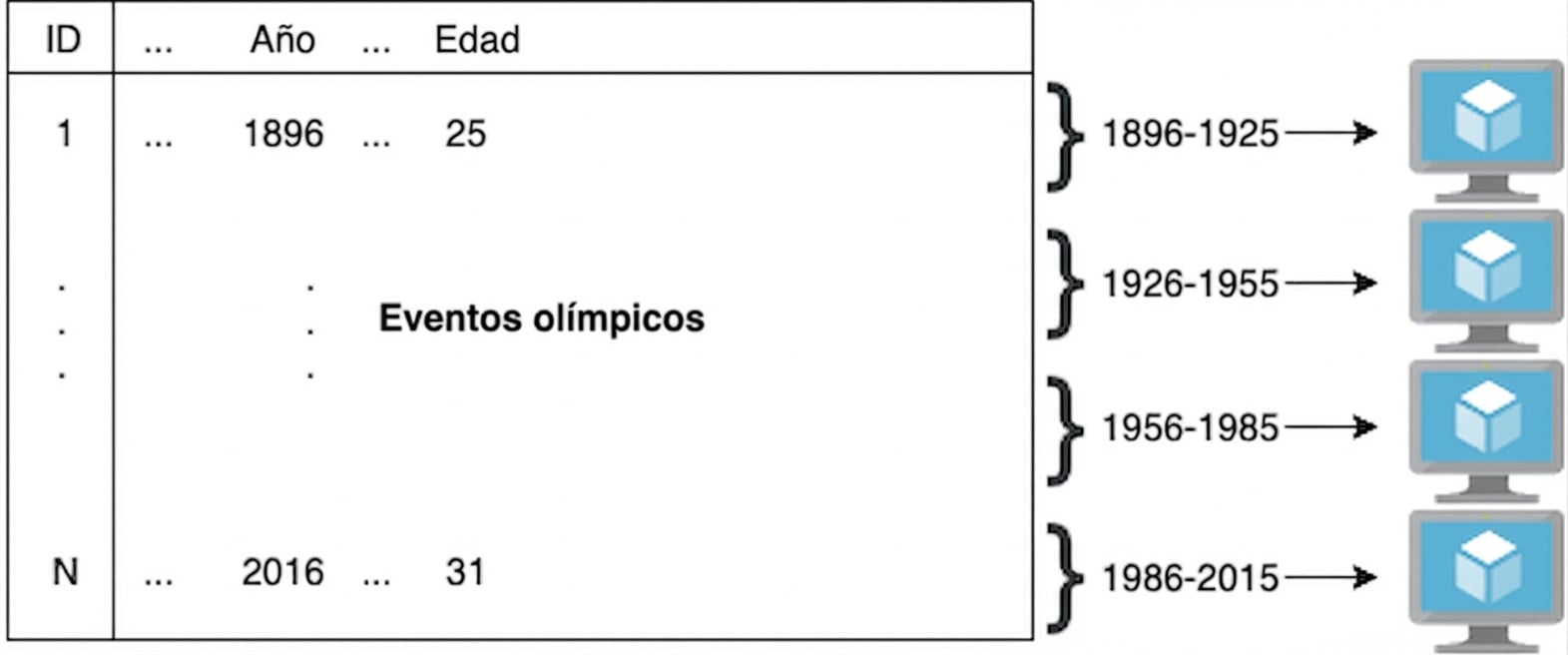
Idea de la computación paralela
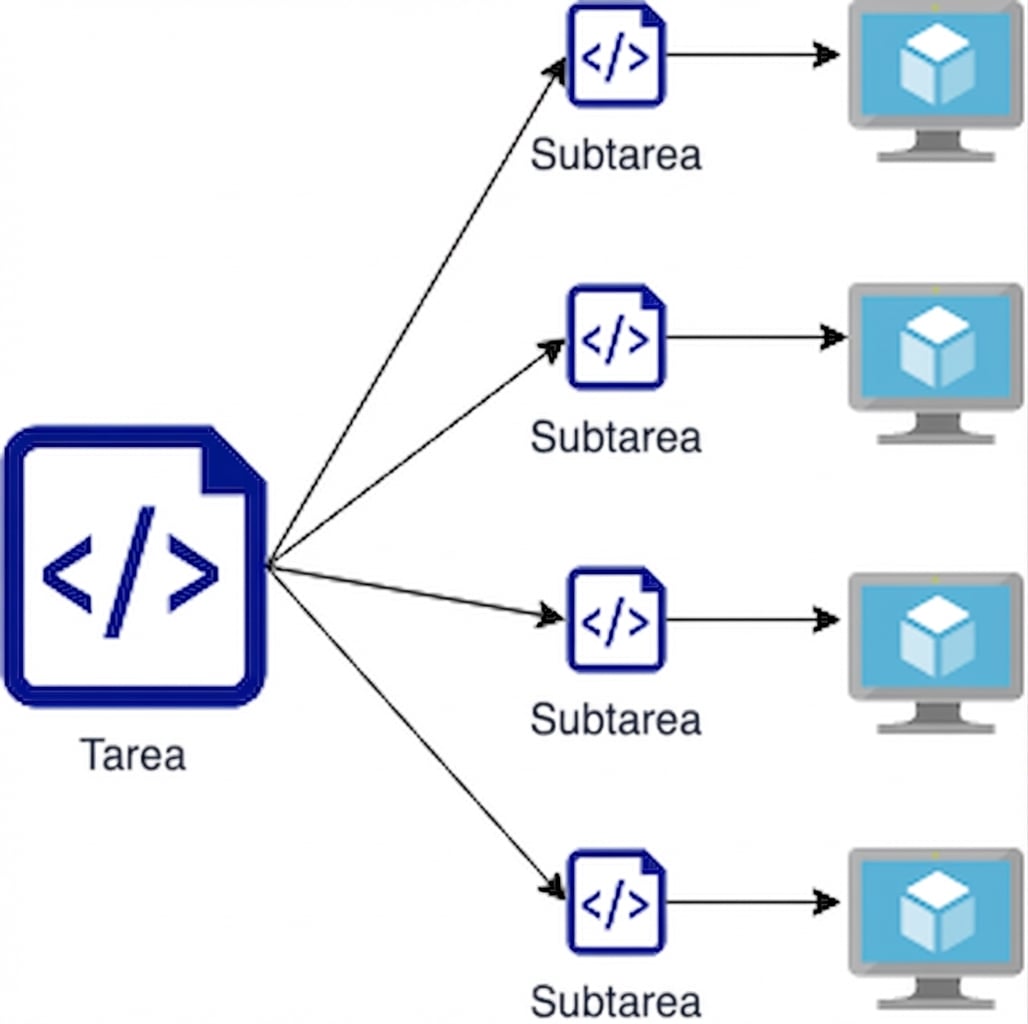
La sastrería
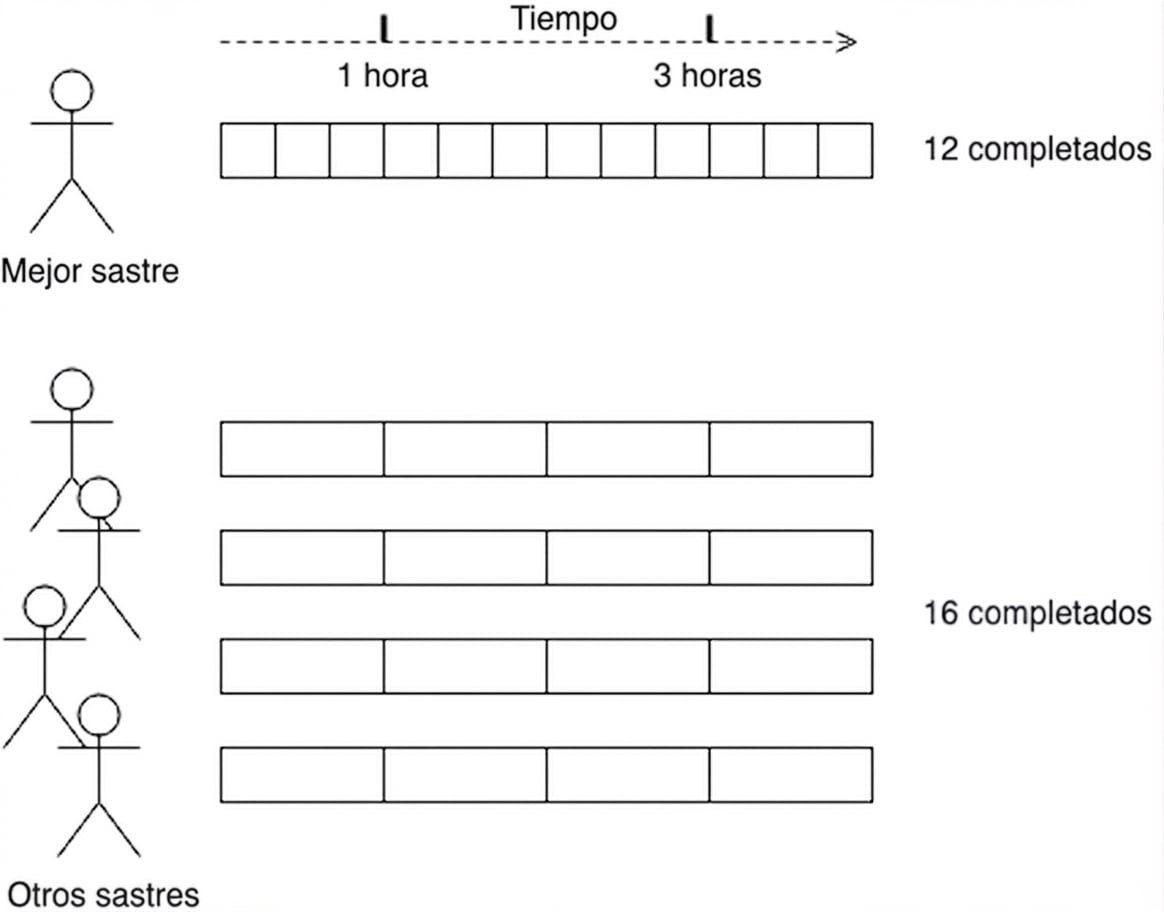
Ventajas de la computación paralela
Memoria RAM:

Riesgos de la computación paralela
Ralentización en paralelo:
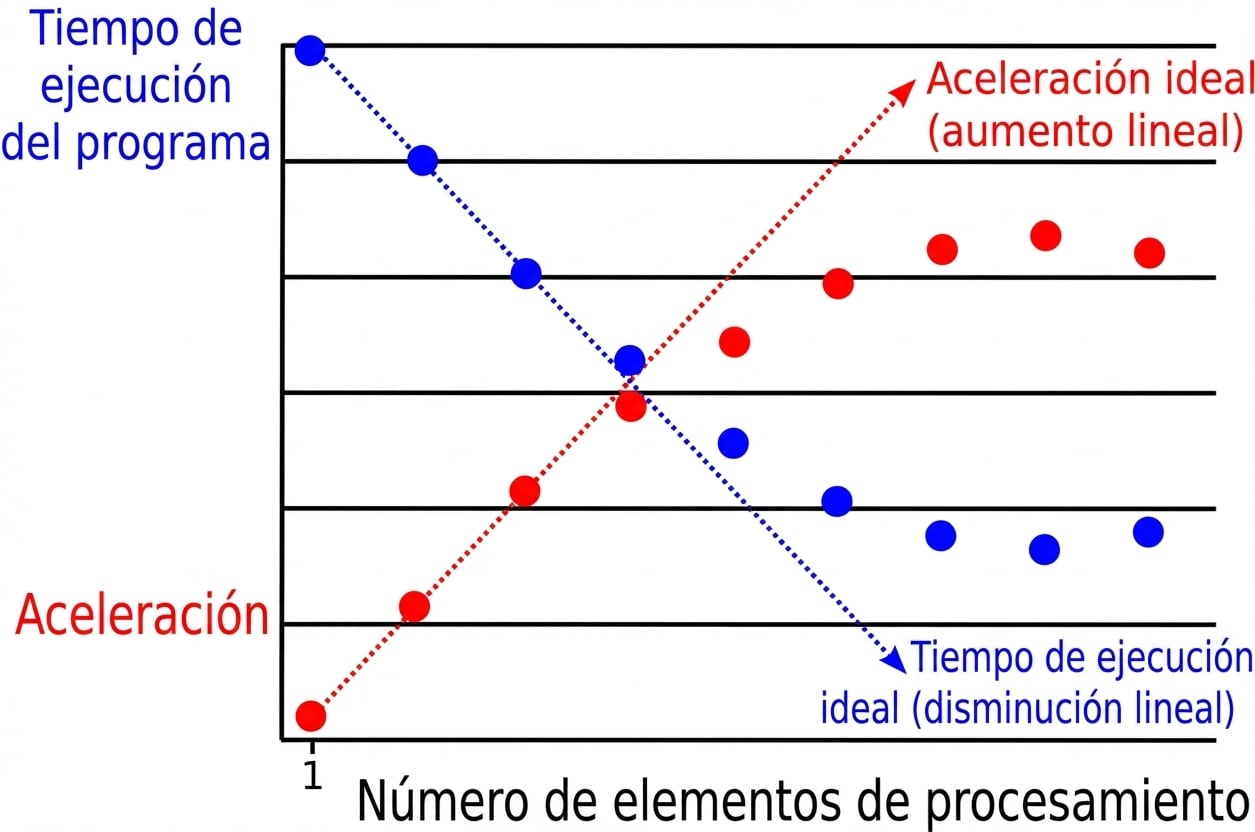
Un ejemplo