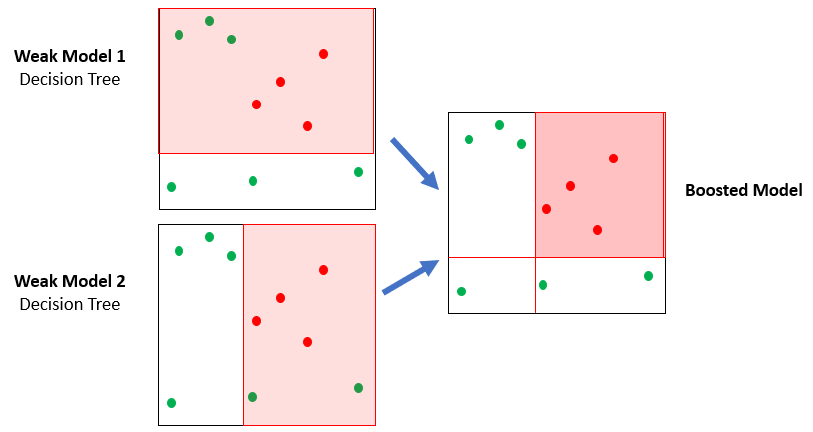
Árboles potenciados (XGBoost)
Modelado del riesgo crediticio en Python

Michael Crabtree
Data Scientist, Ford Motor Company
Árboles de decisión
- Crea predicciones similares a la regresión logística
- No está estructurado como una regresión
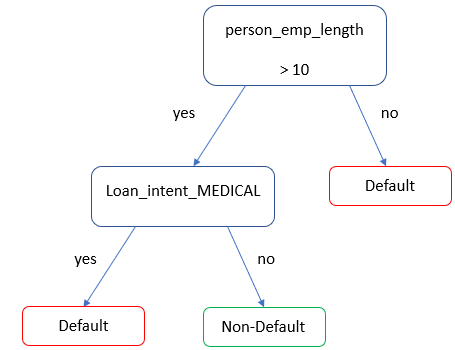
Árboles para el estado del préstamo
- Árbol de decisión simple para predecir la prob. de impago (
loan_status)
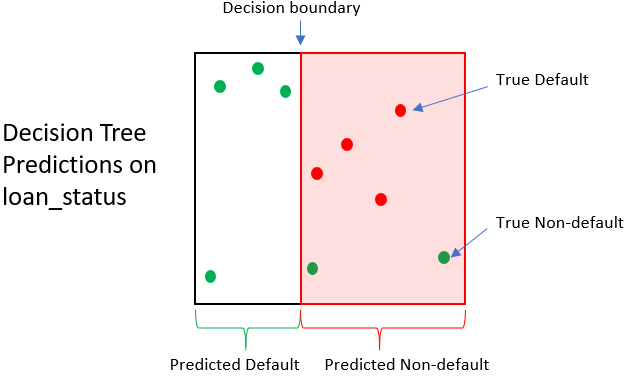
Impacto del árbol de decisión
| Préstamo | Estado real | Estado pred. | Valor al cobrar | Valor de venta | Gan./Pérd. |
|---|---|---|---|---|---|
| 1 | 0 | 1 | $1,500 | $250 | -$1,250 |
| 2 | 0 | 1 | $1,200 | $250 | -$950 |
Un bosque de árboles
- XGBoost usa muchos árboles simples (ensamble)
- Cada árbol rinde apenas mejor que lanzar una moneda