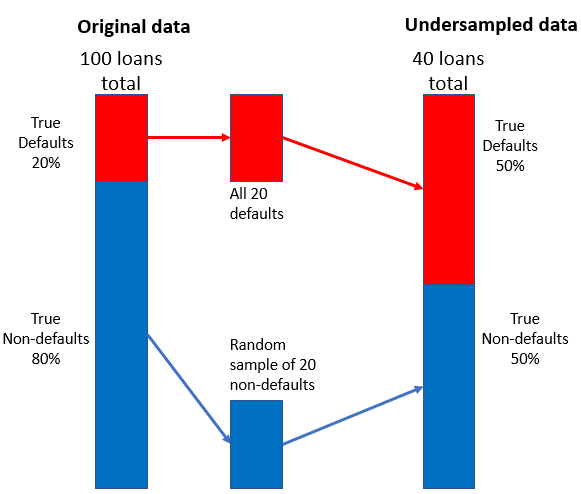
Desbalance de clases en datos de préstamos
Modelado del riesgo crediticio en Python

Michael Crabtree
Data Scientist, Ford Motor Company
Función de pérdida del modelo
- Los Gradient Boosted Trees en
xgboostusan log-loss como función de pérdida- El objetivo es minimizarla
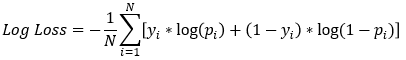
| Estado real del préstamo | Probabilidad predicha | Log-loss |
|---|---|---|
| 1 | 0.1 | 2.3 |
| 0 | 0.9 | 2.3 |
- Un impago mal predicho tiene mayor impacto financiero negativo
Estrategia de submuestreo
- Combina una muestra aleatoria pequeña de no impagos con los impagos