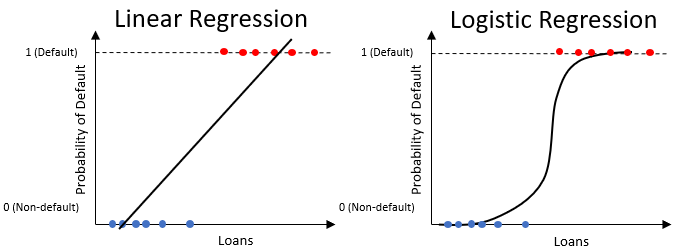
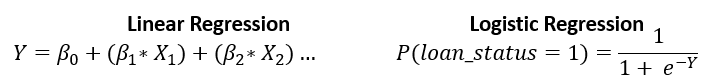Regresión logística para la probabilidad de impago
Modelado del riesgo crediticio en Python

Michael Crabtree
Data Scientist, Ford Motor Company
Predecir probabilidades
- Probabilidades de impago como resultado de machine learning
- Aprende de las columnas (features)
- Modelos de clasificación (impago, no impago)
- Dos modelos más comunes:
- Regresión logística
- Árbol de decisión
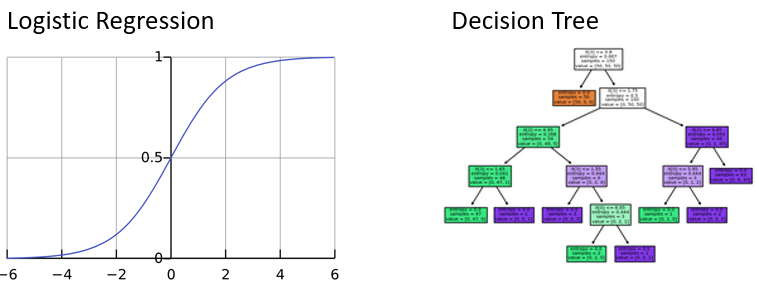
Regresión logística
- Similar a la regresión lineal, pero solo produce valores entre
0y1