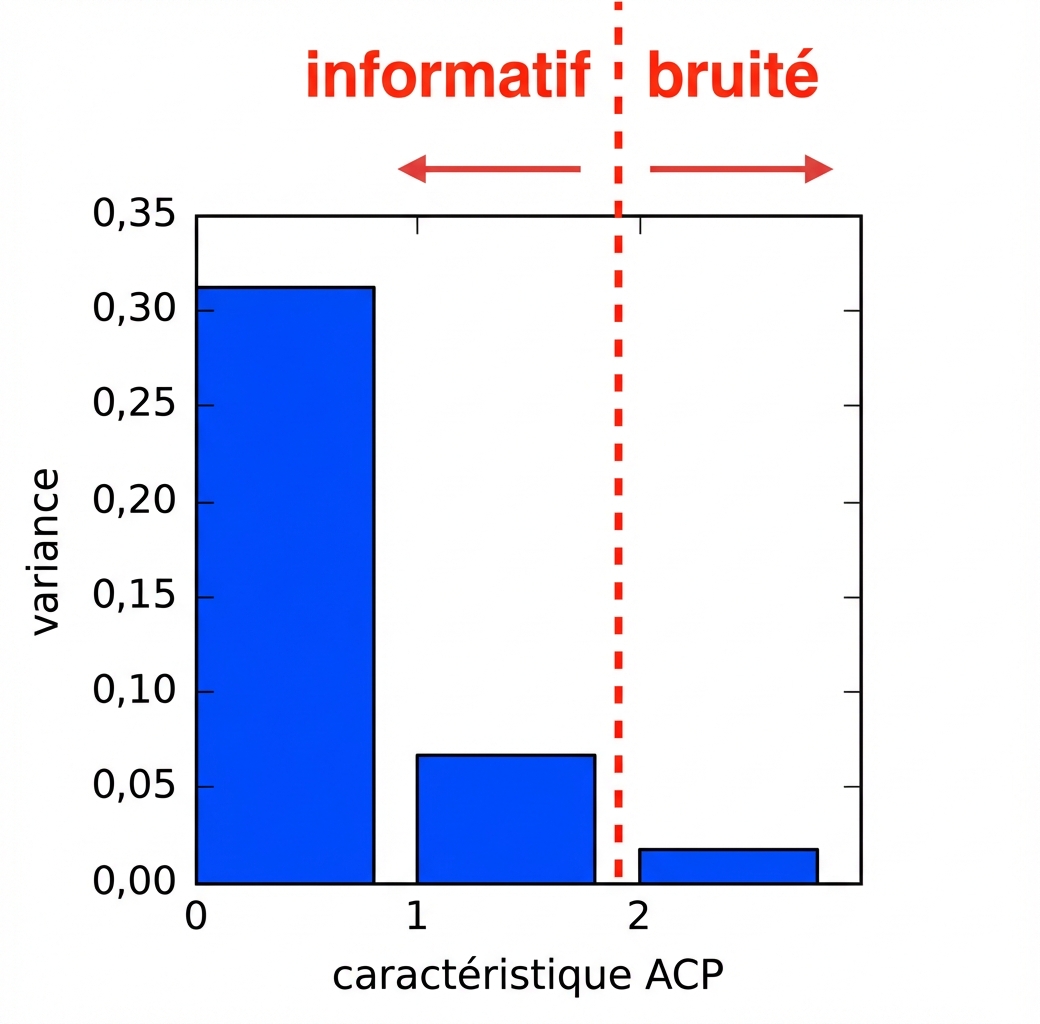
Réduction de dimension avec PCA
Apprentissage non supervisé en Python

Benjamin Wilson
Director of Research at lateral.io
Réduction de dimension avec PCA
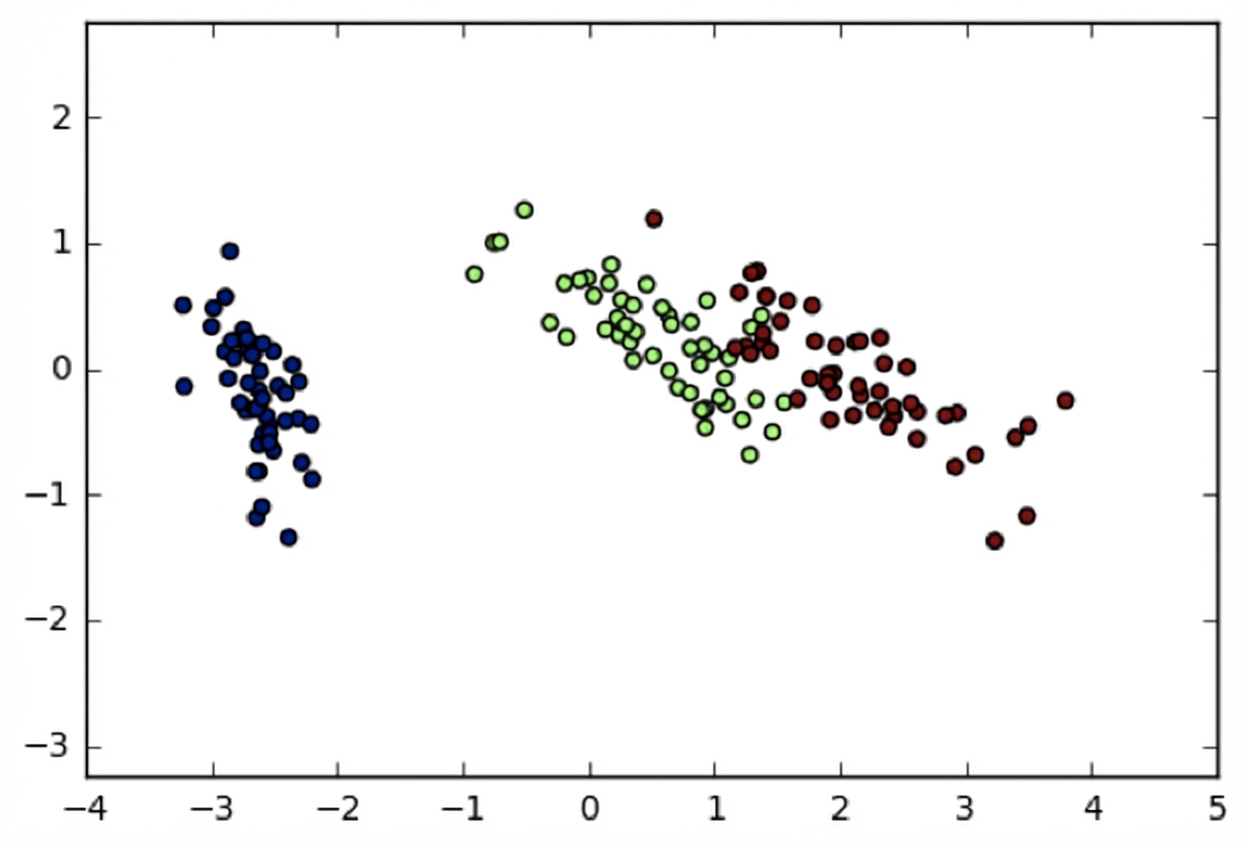
Ensemble de données Iris en deux dimensions
import matplotlib.pyplot as plt
xs = transformed[:,0]
ys = transformed[:,1]
plt.scatter(xs, ys, c=species)
plt.show()
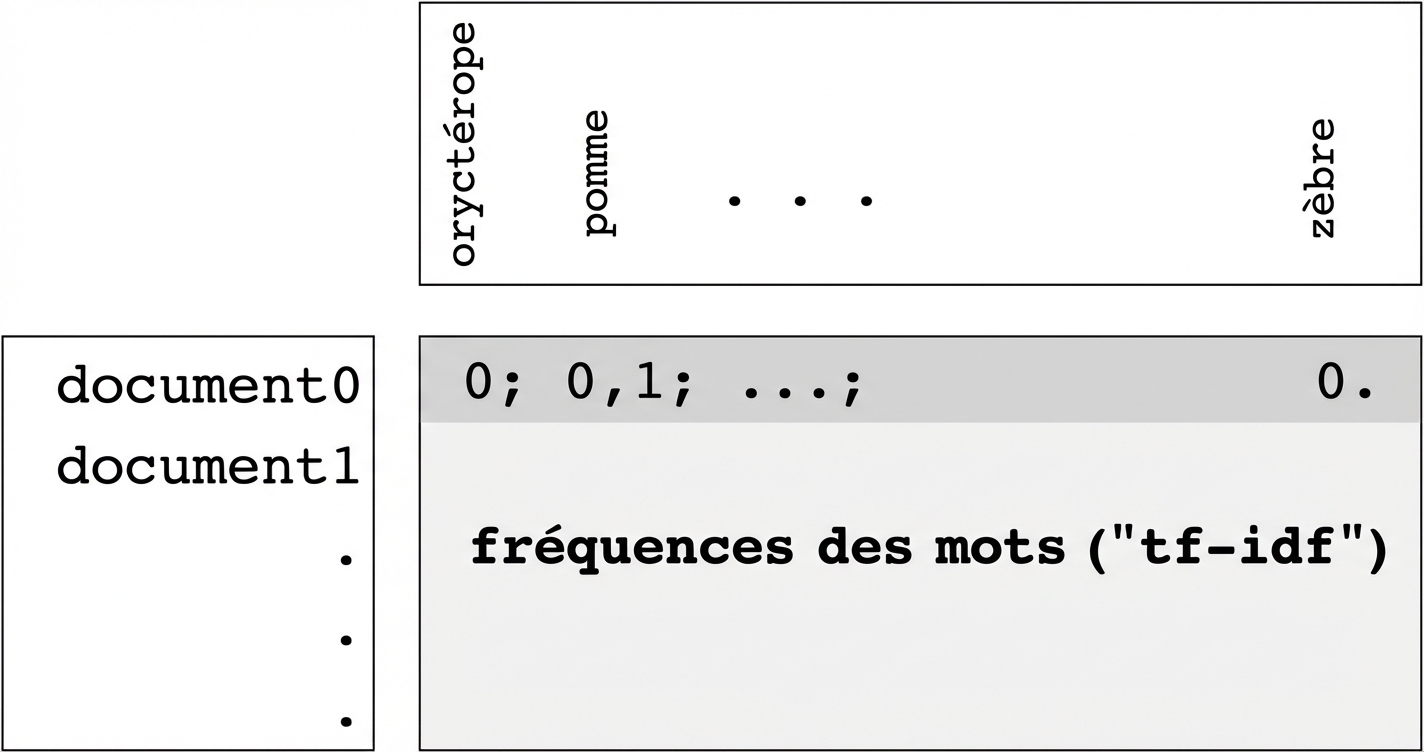
Tableaux de fréquence des mots
- Les lignes représentent les documents, les colonnes représentent les mots
- Les entrées mesurent la présence de chaque mot dans chaque document
- … mesurer à l'aide de "tf-idf" (plus d'informations à ce sujet ultérieurement)
Matrice creuse et csr_matrix
- "Creuse" : la plupart des entrées sont nulles
- Il est possible d'utiliser
scipy.sparse.csr_matrixà la place du tableau NumPy csr_matrixn'enregistre que les entrées non nulles (gain d'espace !)

