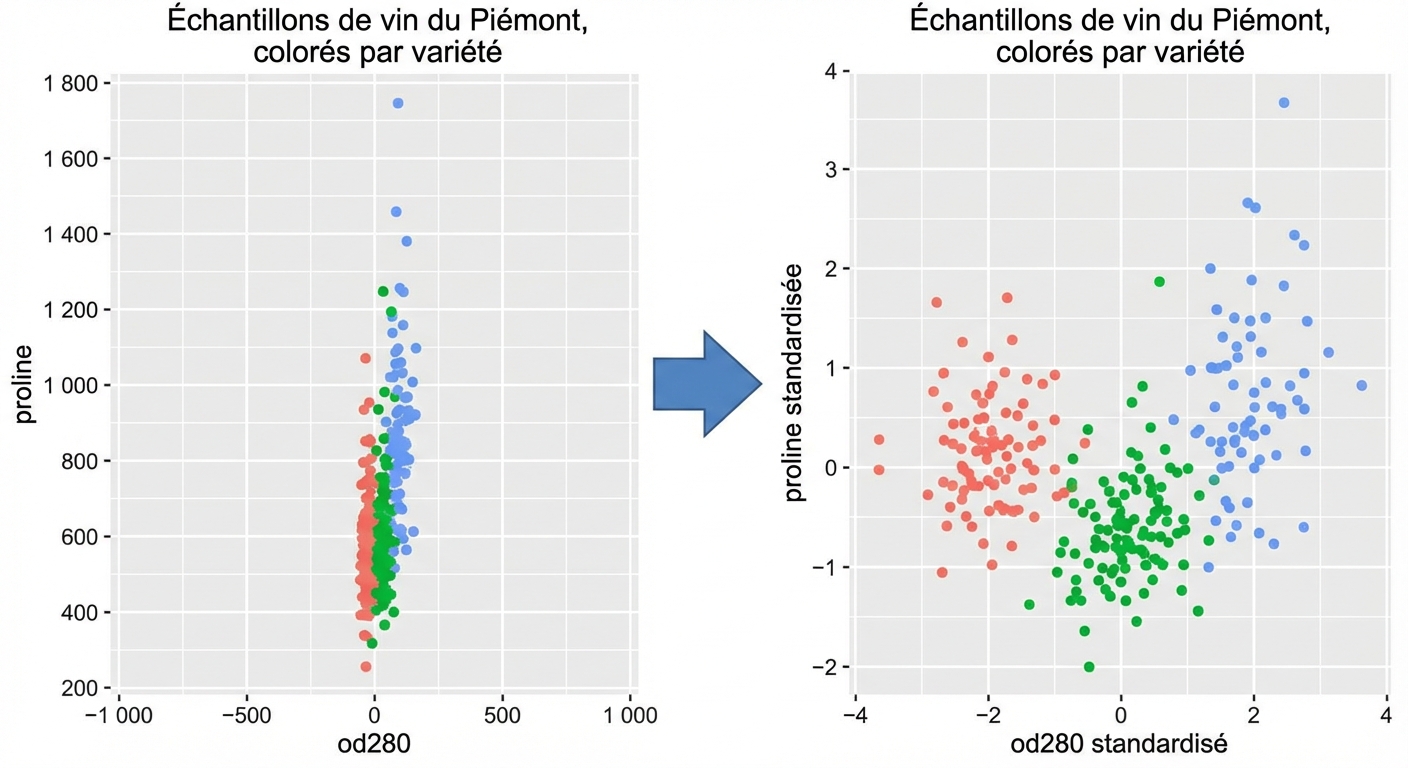
Transformation des caractéristiques pour améliorer les regroupements
Apprentissage non supervisé en Python

Benjamin Wilson
Director of Research at lateral.io
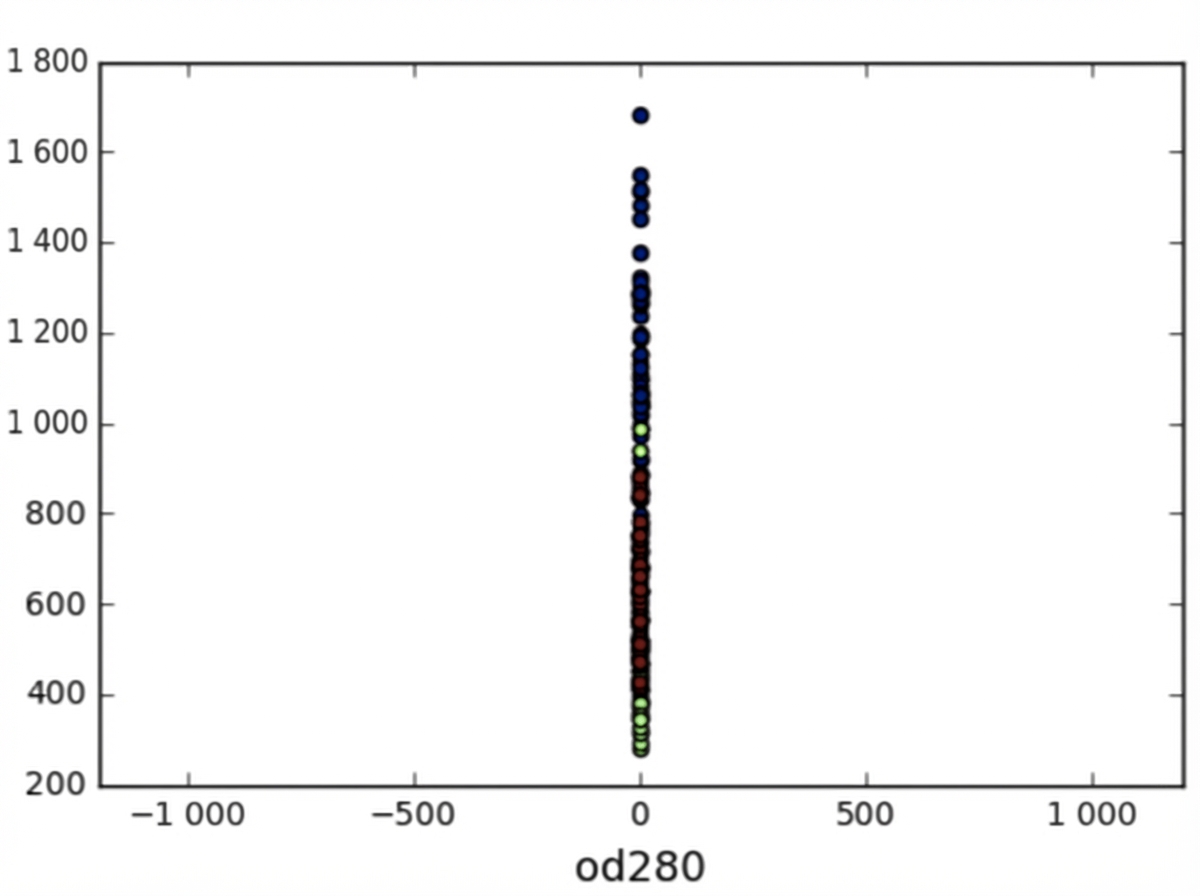
Variations des fonctionnalités
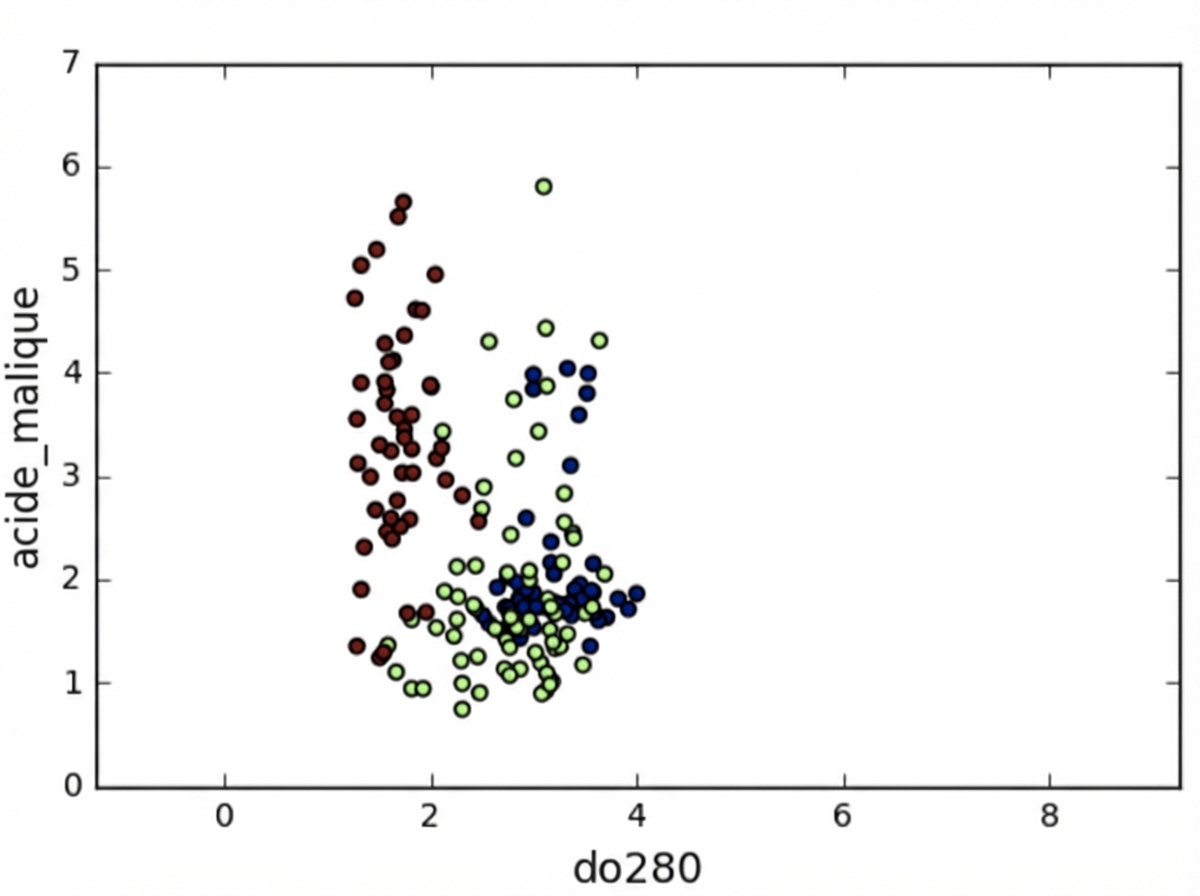
Variations des fonctionnalités
StandardScaler
Dans kmeans : variance des caractéristiques = influence des caractéristiques
StandardScalertransforme chaque caractéristique pour qu'elle ait une moyenne de 0 et une variance de 1Les fonctionnalités sont considérées comme « standardisées »