Tests d’hypothèse et scores z
Tests d'hypothèses en Python

James Chapman
Curriculum Manager, DataCamp
Test A/B

1 Crédit image : « Electronic Arts » par majaX1 CC BY-NC-SA 2.0
Test A/B sur une page e-commerce
Contrôle :

Traitement :
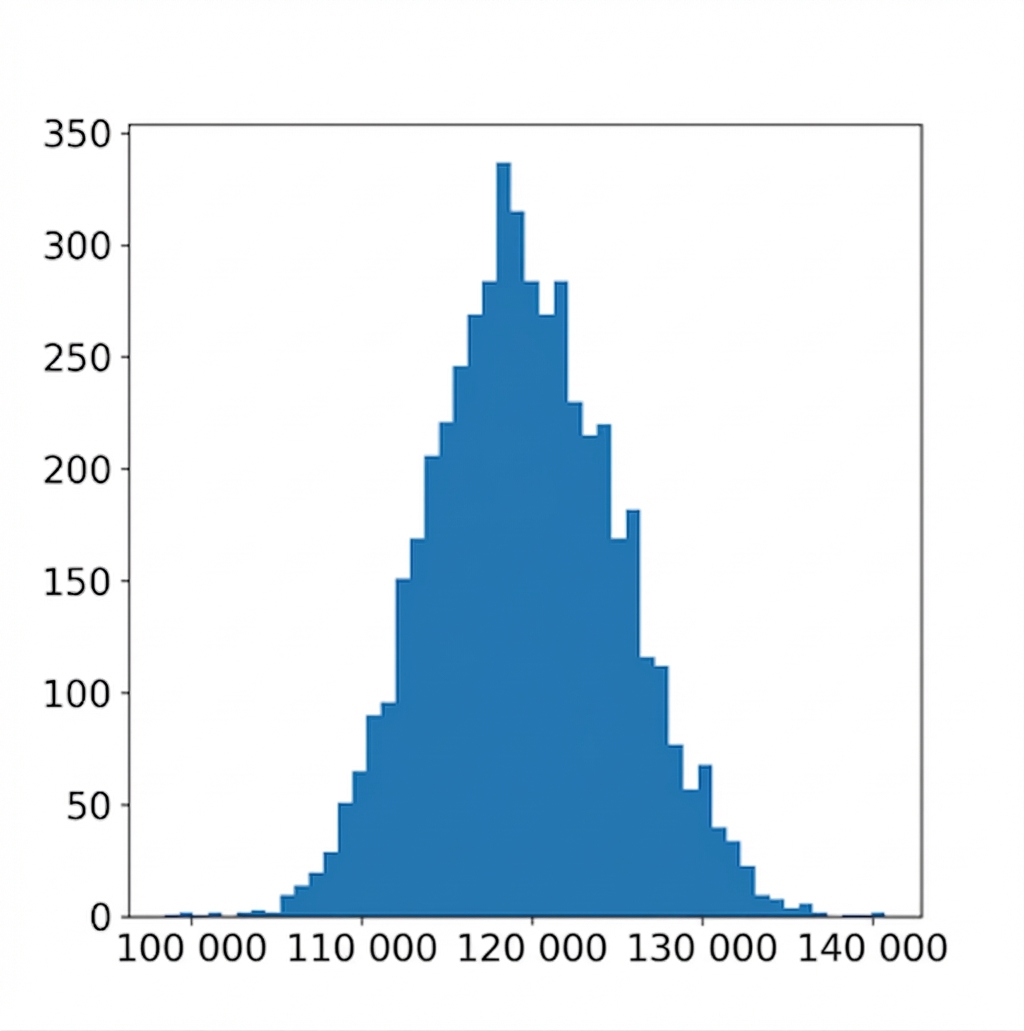
Visualiser la distribution bootstrap
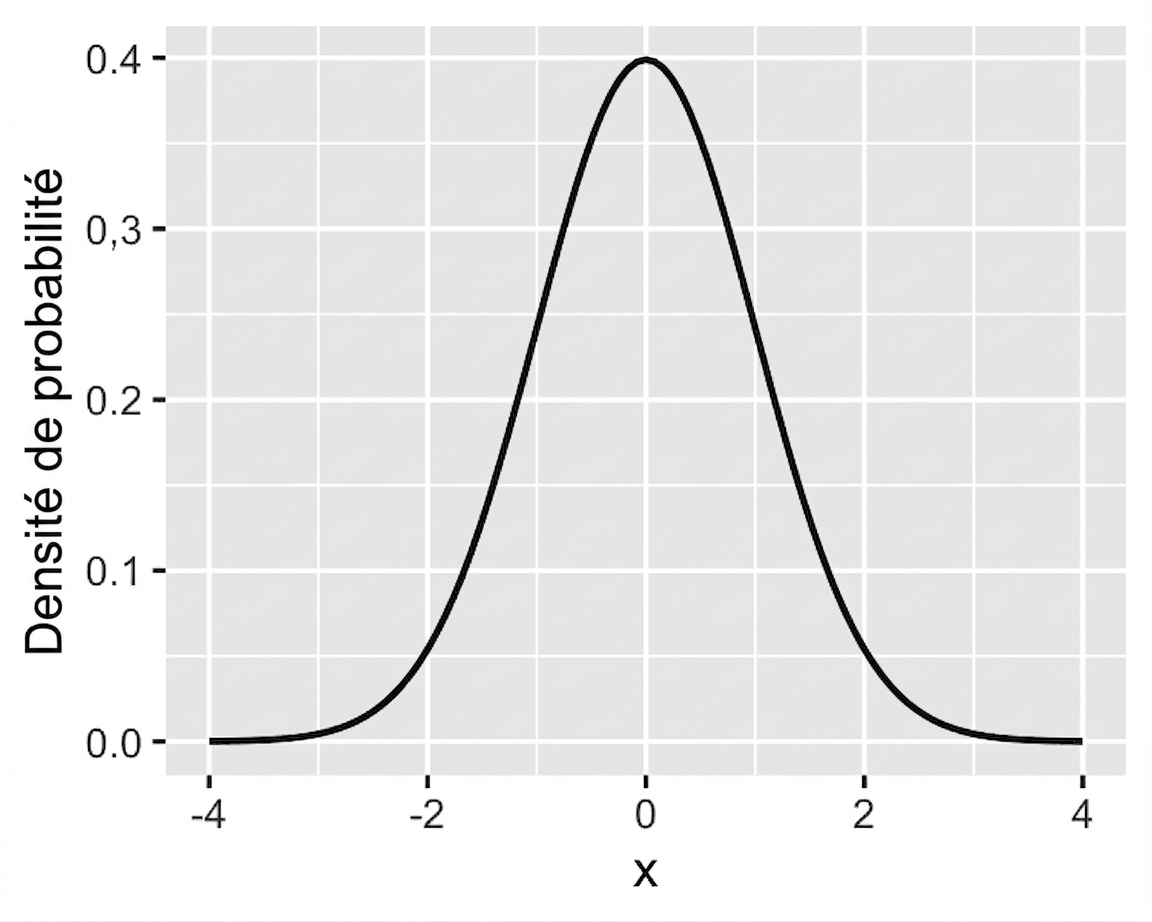
Loi normale (z) standard
Distribution normale standard : normale avec moyenne = 0 et écart-type = 1