Erreurs standard et théorème central limite
L’échantillonnage en Python

James Chapman
Curriculum Manager, DataCamp
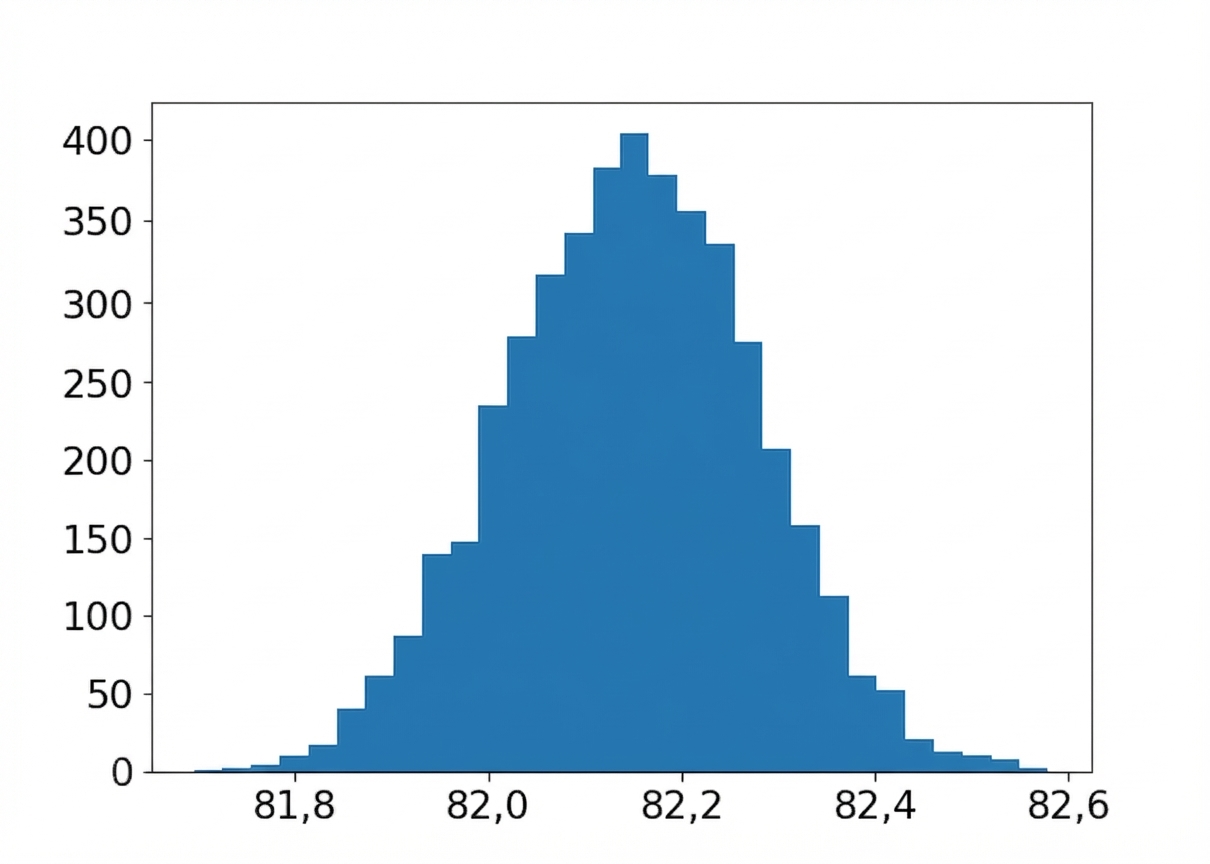
Distribution d’échantillonnage des points de tasse moyens
Taille d’échantillon : 5
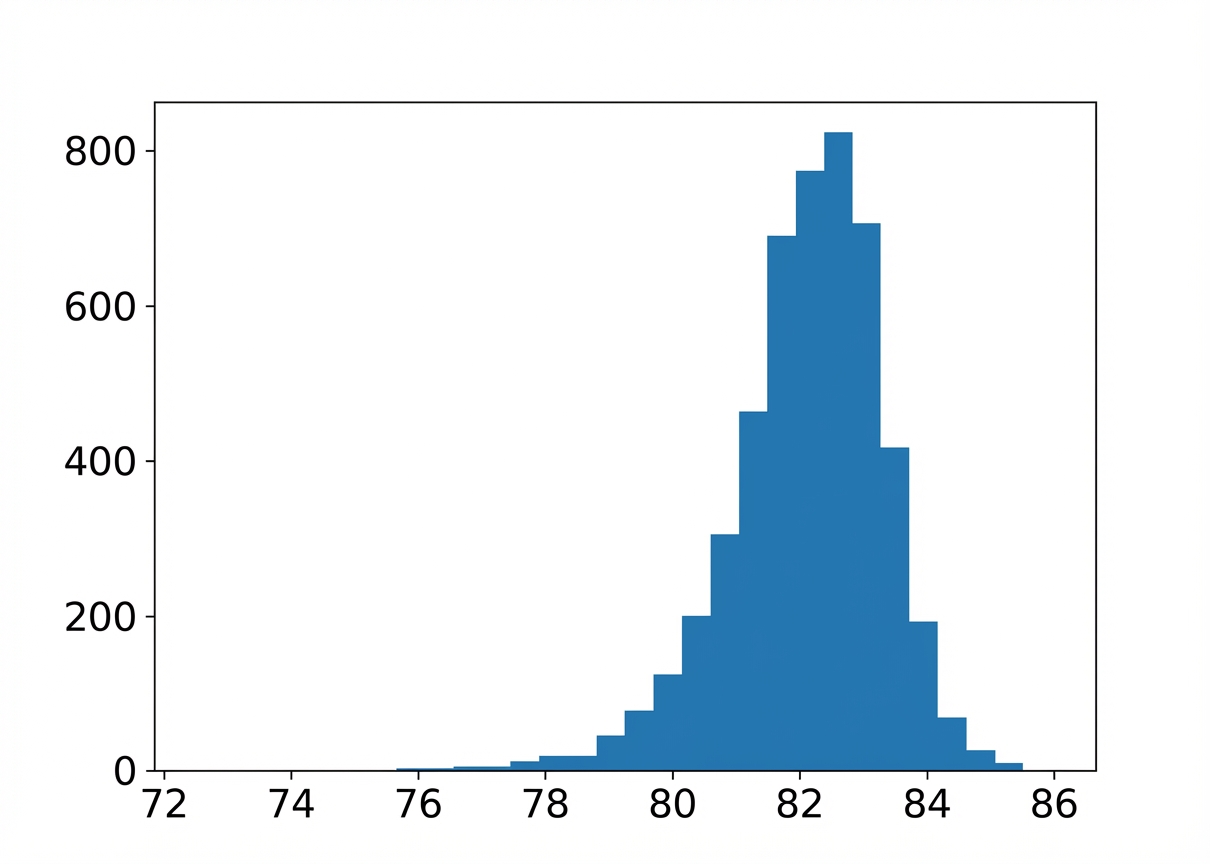
Taille d’échantillon : 20
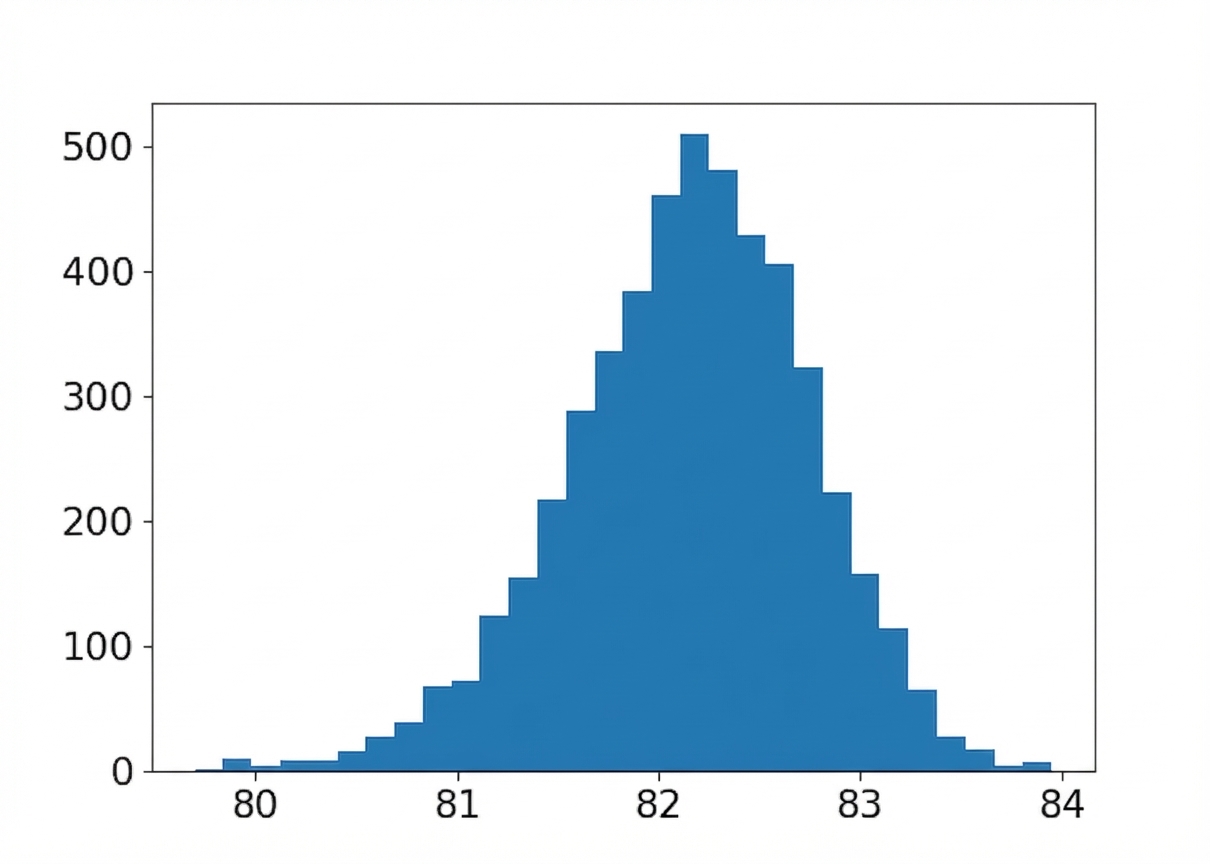
Taille d’échantillon : 80
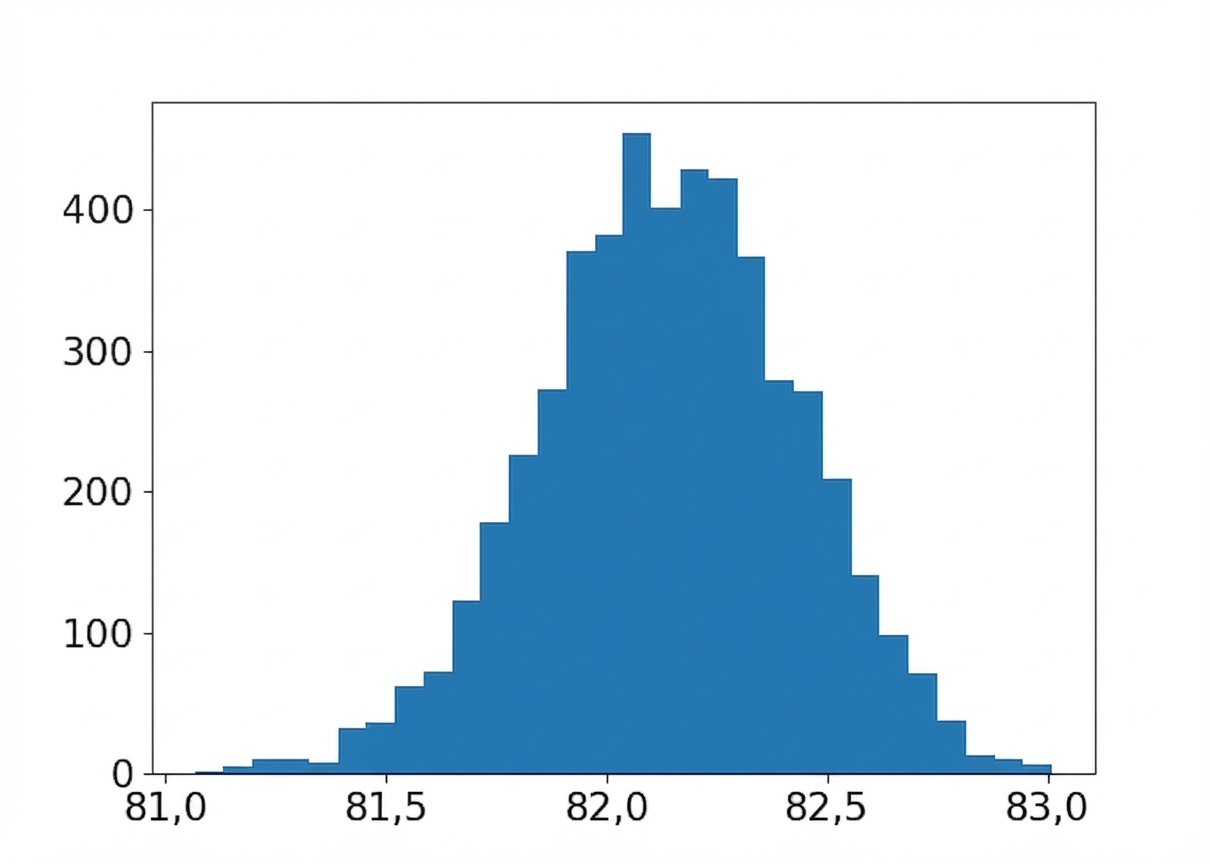
Taille d’échantillon : 320