Comparer échantillonnage et bootstrap
L’échantillonnage en Python

James Chapman
Curriculum Manager, DataCamp
Sous-ensemble centré café
coffee_sample = coffee_ratings[["variety", "country_of_origin", "flavor"]]\
.reset_index().sample(n=500)
index variety country_of_origin flavor
132 132 Other Costa Rica 7.58
51 51 None United States (Hawaii) 8.17
42 42 Yellow Bourbon Brazil 7.92
569 569 Bourbon Guatemala 7.67
.. ... ... ... ...
643 643 Catuai Costa Rica 7.42
356 356 Caturra Colombia 7.58
494 494 None Indonesia 7.58
169 169 None Brazil 7.81
[500 rows x 4 columns]
Bootstrap des moyennes de saveur du café
import numpy as np
mean_flavors_5000 = []
for i in range(5000):
mean_flavors_5000.append(
np.mean(coffee_sample.sample(frac=1, replace=True)['flavor'])
)
bootstrap_distn = mean_flavors_5000
Distribution bootstrap de la moyenne de saveur
import matplotlib.pyplot as plt
plt.hist(bootstrap_distn, bins=15)
plt.show()
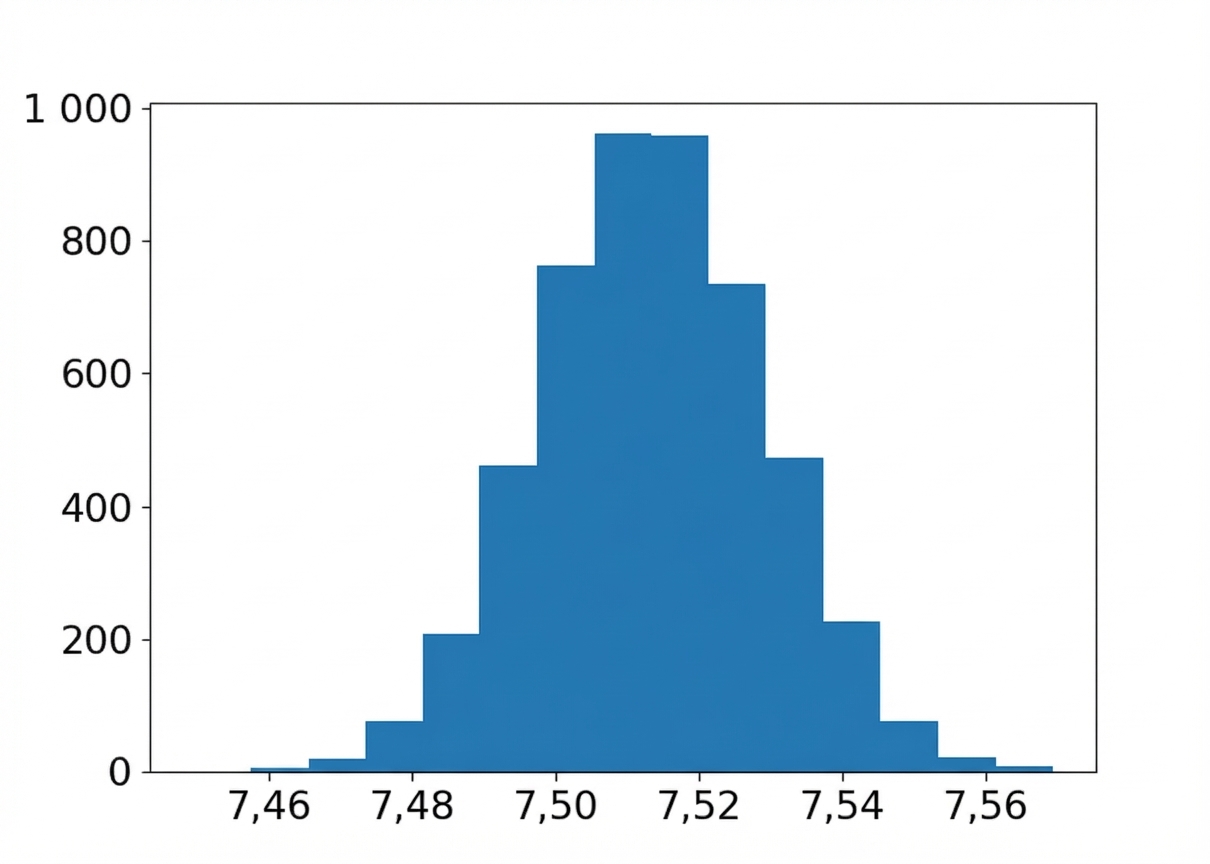
Moyennes : échantillon, bootstrap, population
Moyenne de l’échantillon :
coffee_sample['flavor'].mean()
7.5132200000000005
Moyenne de population estimée :
np.mean(bootstrap_distn)
7.513357731999999
Vraie moyenne de population :
coffee_ratings['flavor'].mean()
7.526046337817639
Interpréter les moyennes
Moyenne de la distribution bootstrap :
- Souvent proche de la moyenne de l’échantillon
- Peut mal estimer la moyenne de la population
Le bootstrap ne corrige pas les biais d’échantillonnage
Écart-type échantillon vs. distribution bootstrap
Écart-type de l’échantillon :
coffee_sample['flavor'].std()
0.3540883911928703
Écart-type de population estimé ?
np.std(bootstrap_distn, ddof=1)
0.015768474367958217
Écart-types : échantillon, bootstrap, population
Écart-type de l’échantillon :
coffee_sample['flavor'].std()
0.3540883911928703
Écart-type de population estimé :
standard_error = np.std(bootstrap_distn, ddof=1)
Erreur standard = écart-type de la statistique d’intérêt
Vrai écart-type :
coffee_ratings['flavor'].std(ddof=0)
0.34125481224622645
standard_error * np.sqrt(500)
0.3525938058821761
Erreur standard multipliée par la racine de la taille d’échantillon estime l’écart-type de population
Interpréter les erreurs standard
- Erreur standard estimée → écart-type de la distribution bootstrap d’une statistique d’échantillon
- $\text{Écart-type population} \approx \text{Erreur standard} \times \sqrt{\text{Taille d’échantillon}}$
Passons à la pratique !
L’échantillonnage en Python

