Intervalles de confiance
L’échantillonnage en Python

James Chapman
Curriculum Manager, DataCamp
Prévoir la météo
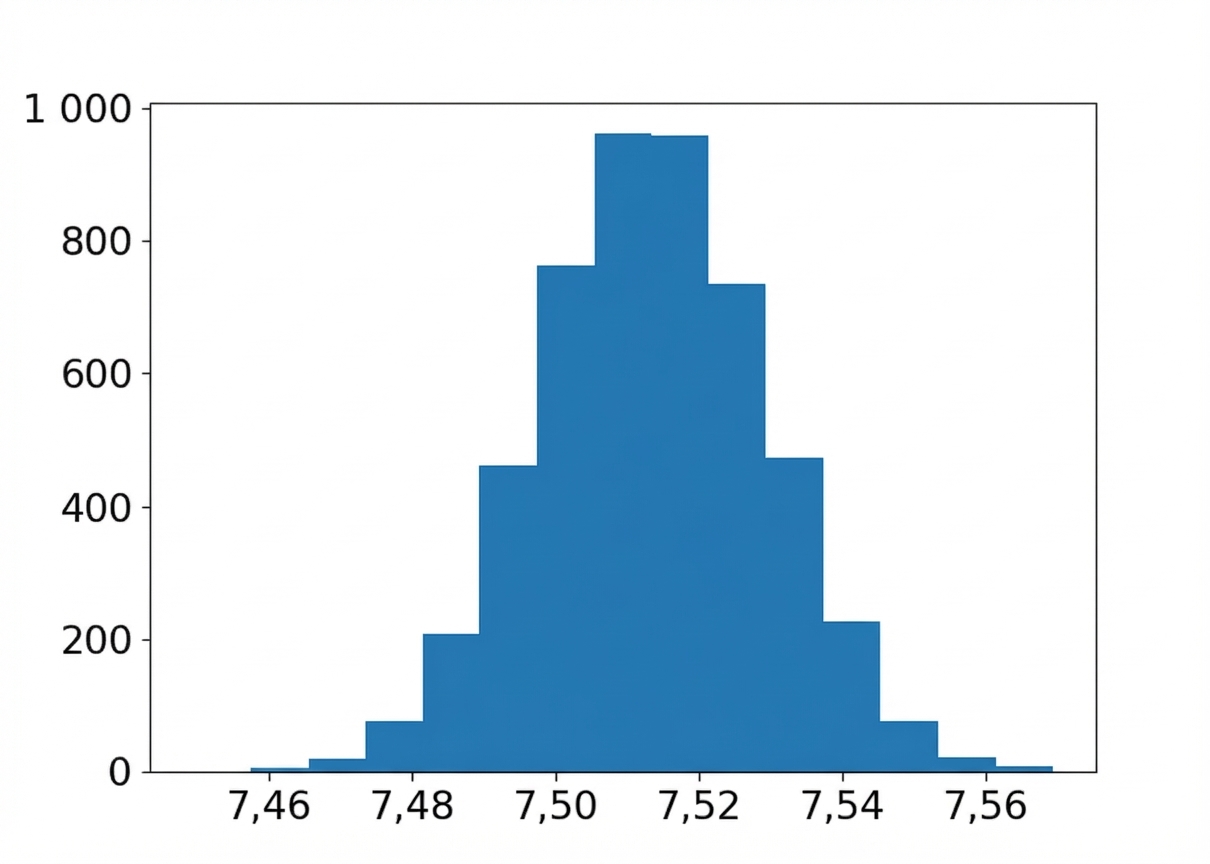
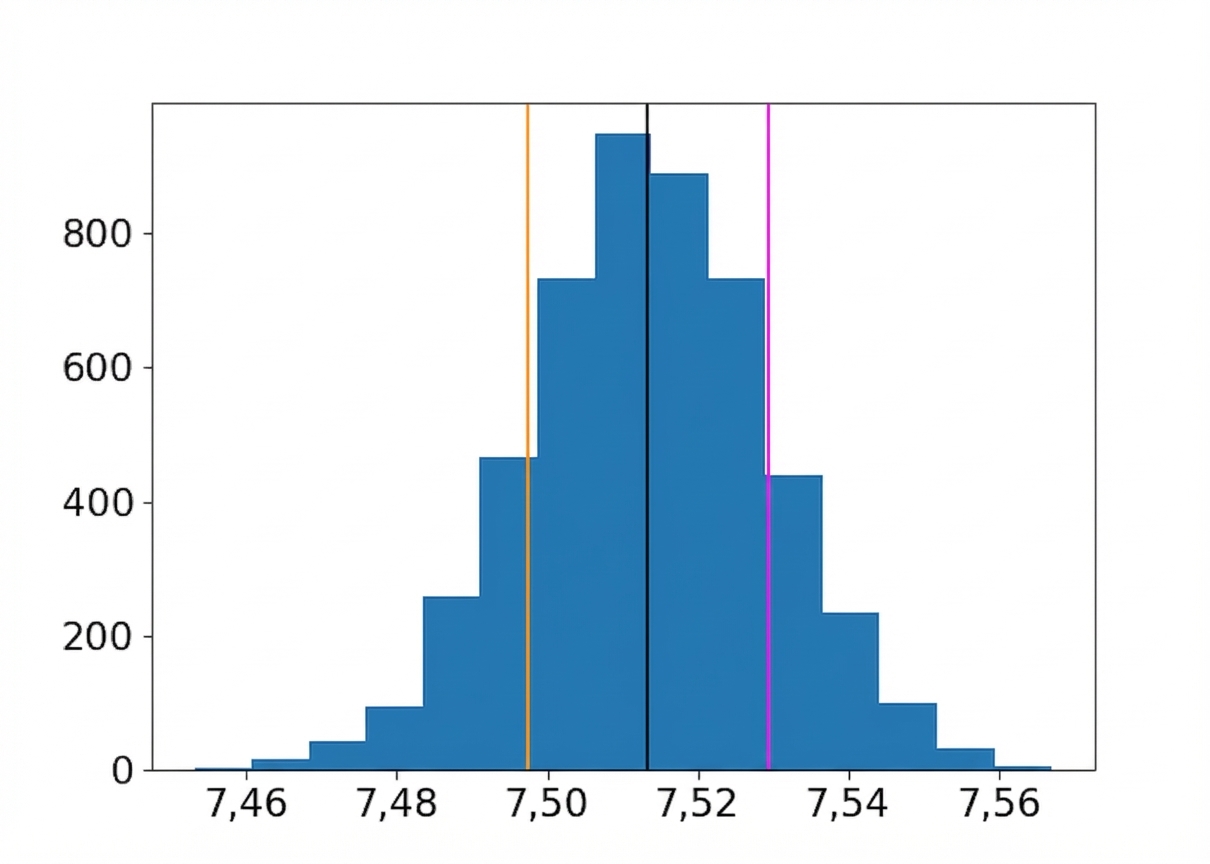
Distribution bootstrap de la saveur moyenne
Moyenne des rééchantillonnages
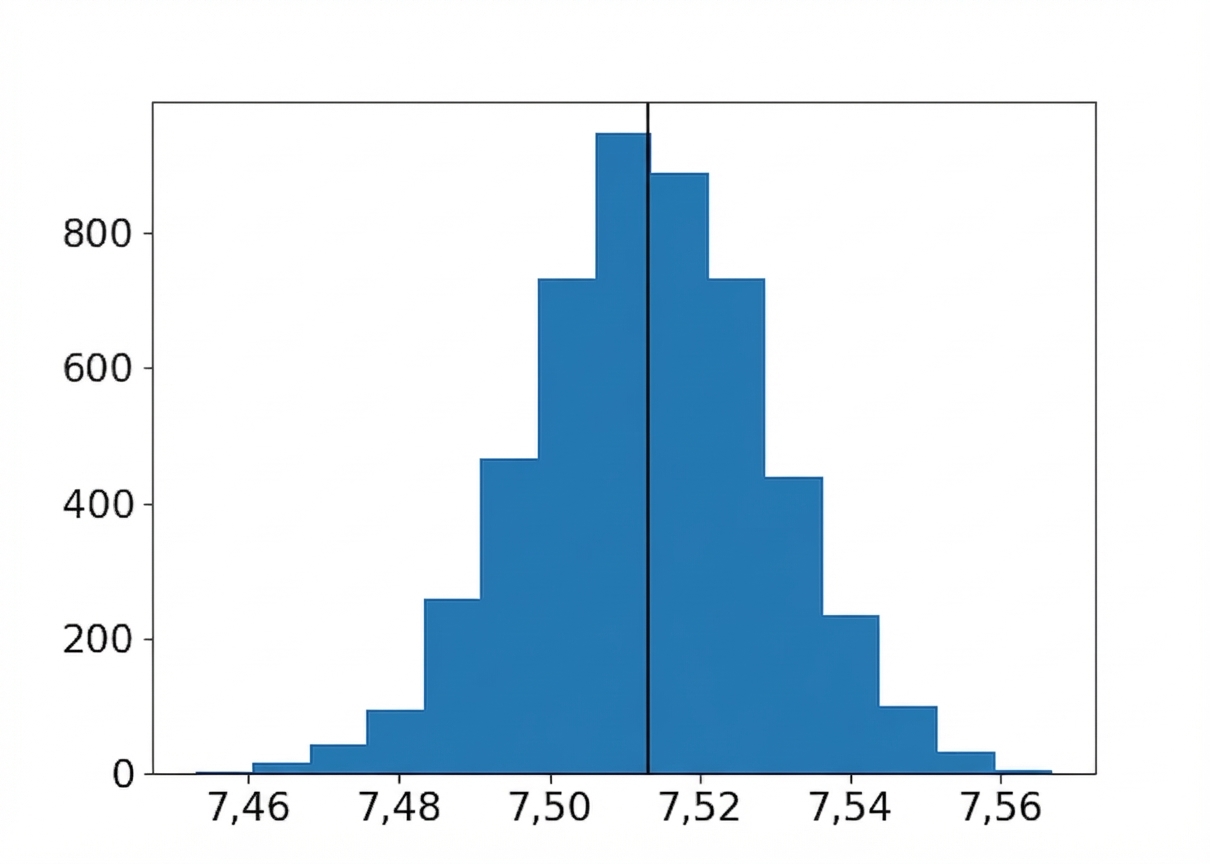
Moyenne ± un écart type
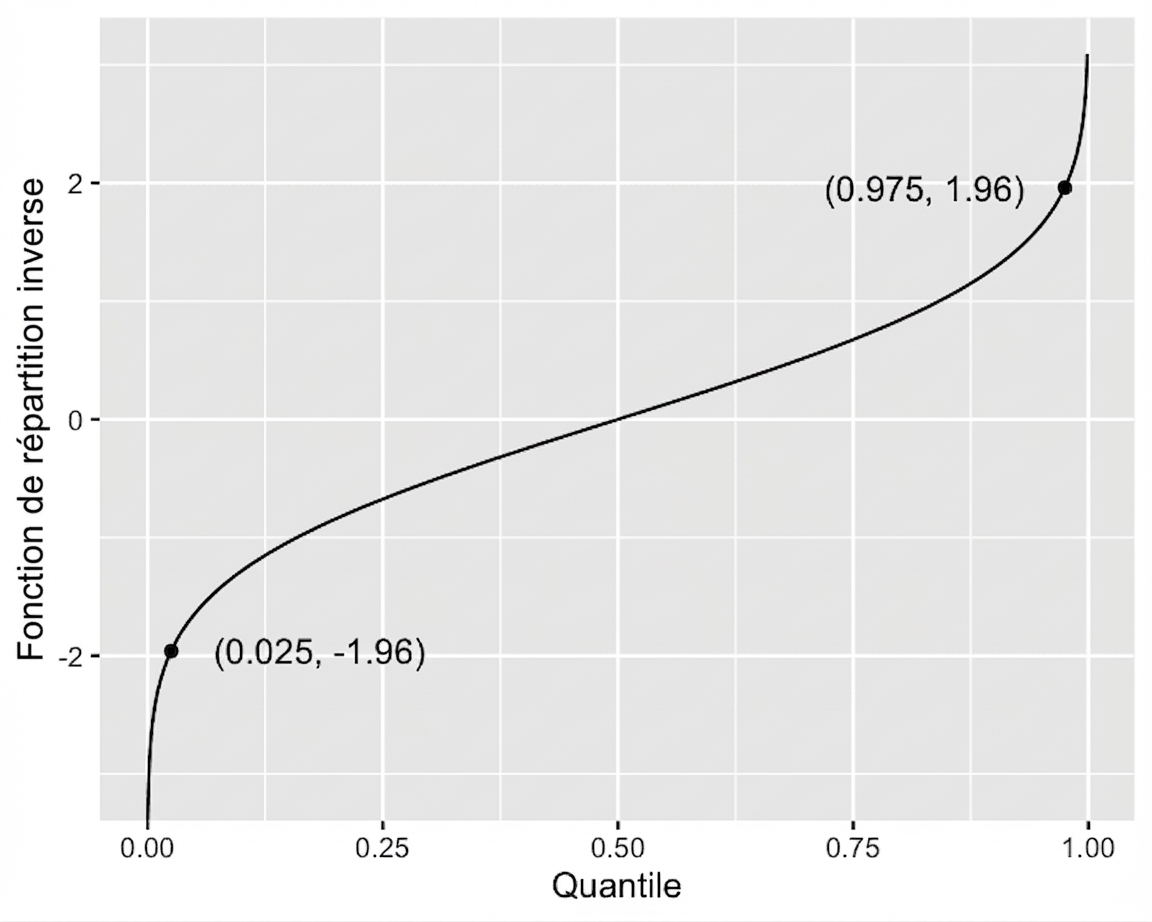
Méthode des quantiles pour l’intervalle de confiance
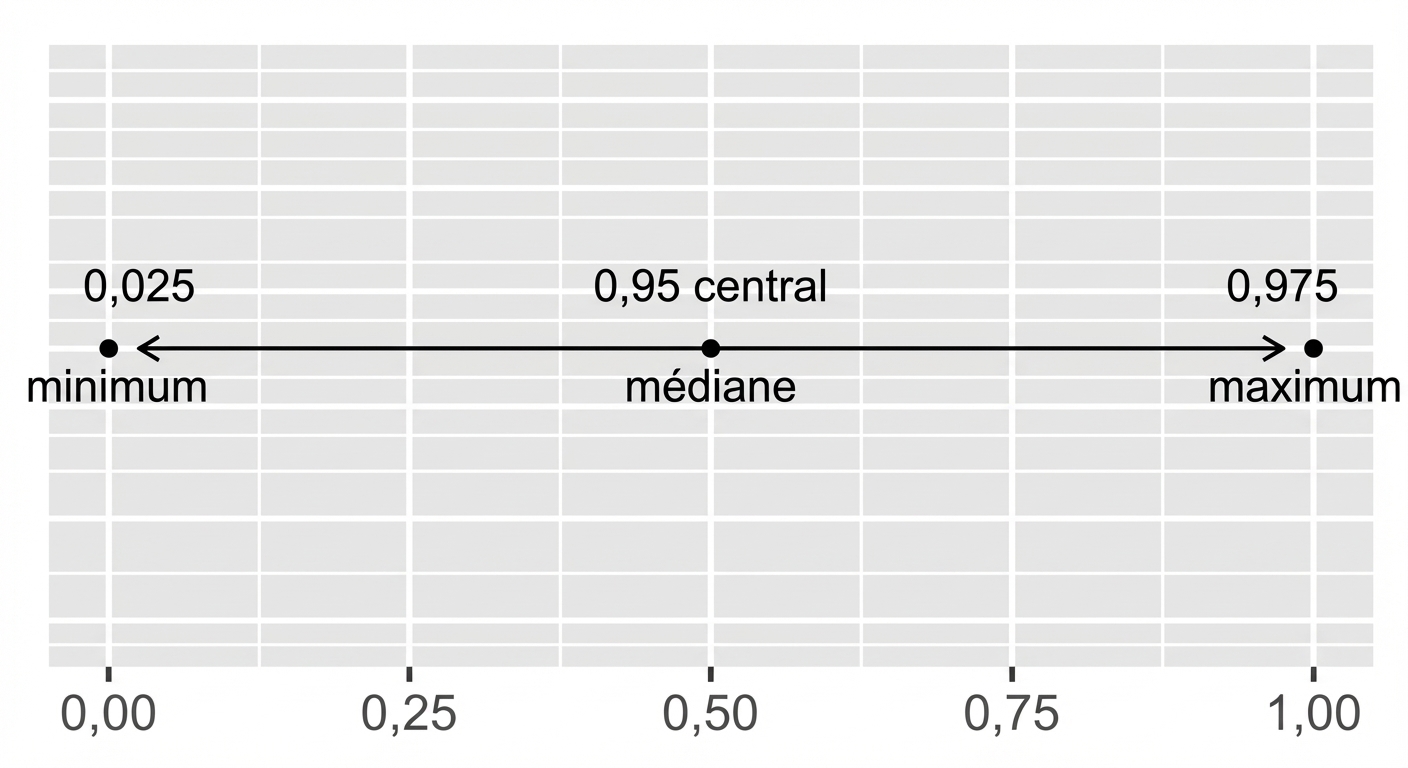
Fonction de répartition cumulée inverse