Introduction au bootstrap
L’échantillonnage en Python

James Chapman
Curriculum Manager, DataCamp
Avec ou sans
Échantillonnage sans remise :

Échantillonnage avec remise (« rééchantillonnage ») :

Échantillonnage aléatoire simple sans remise
Population :

Échantillon :

Échantillonnage aléatoire simple avec remise
Population :
Rééchantillon :

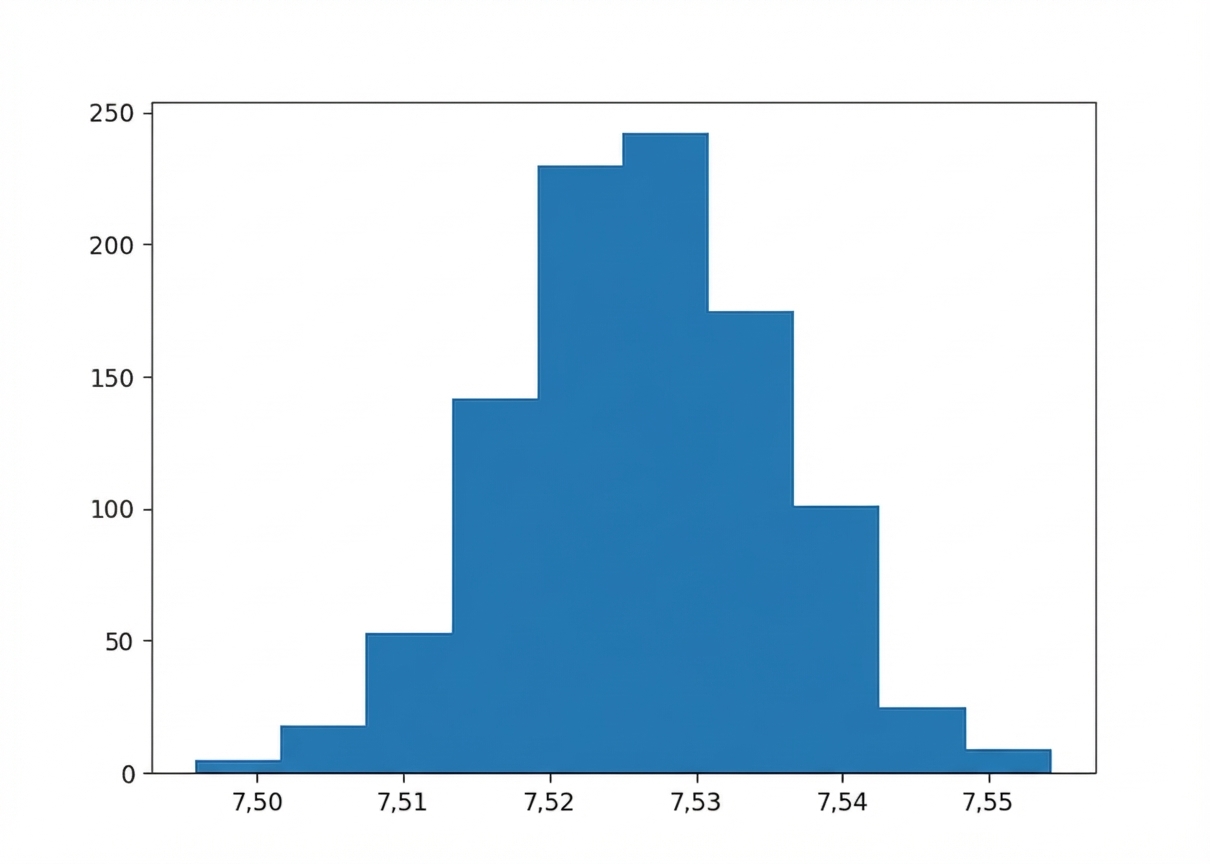
Bootstrap
Histogramme de la distribution bootstrap