Créer une distribution d’échantillonnage
L’échantillonnage en Python

James Chapman
Curriculum Manager, DataCamp
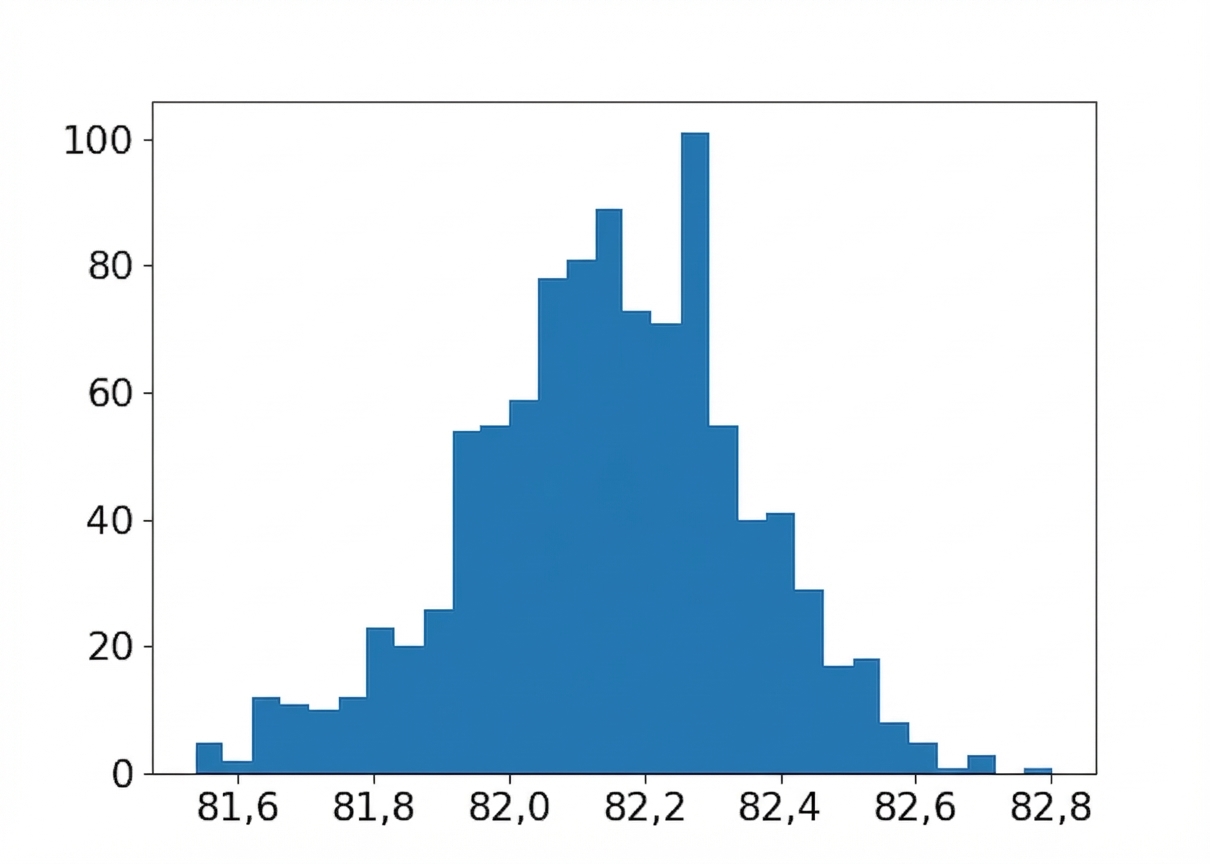
Distribution des moyennes d’échantillon (taille 30)
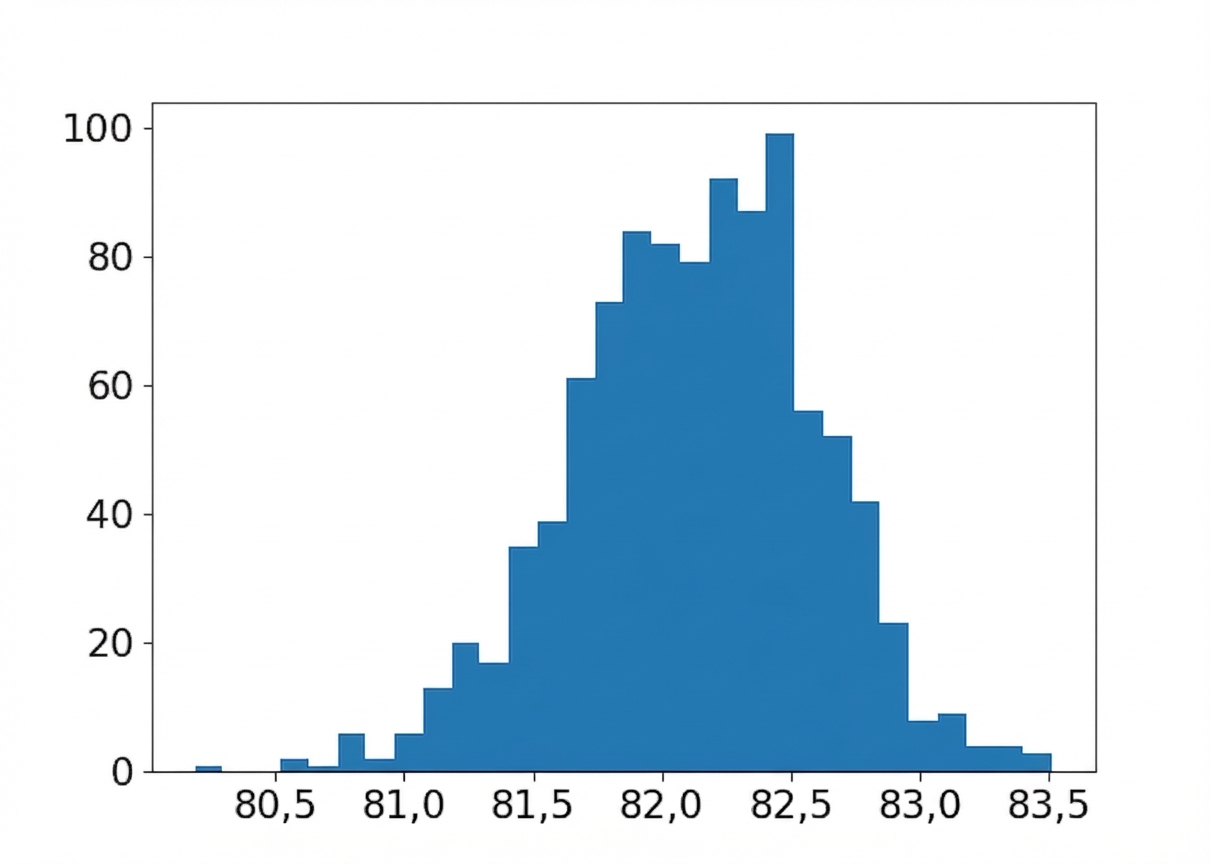
Tailles d’échantillon différentes
Taille d’échantillon : 6
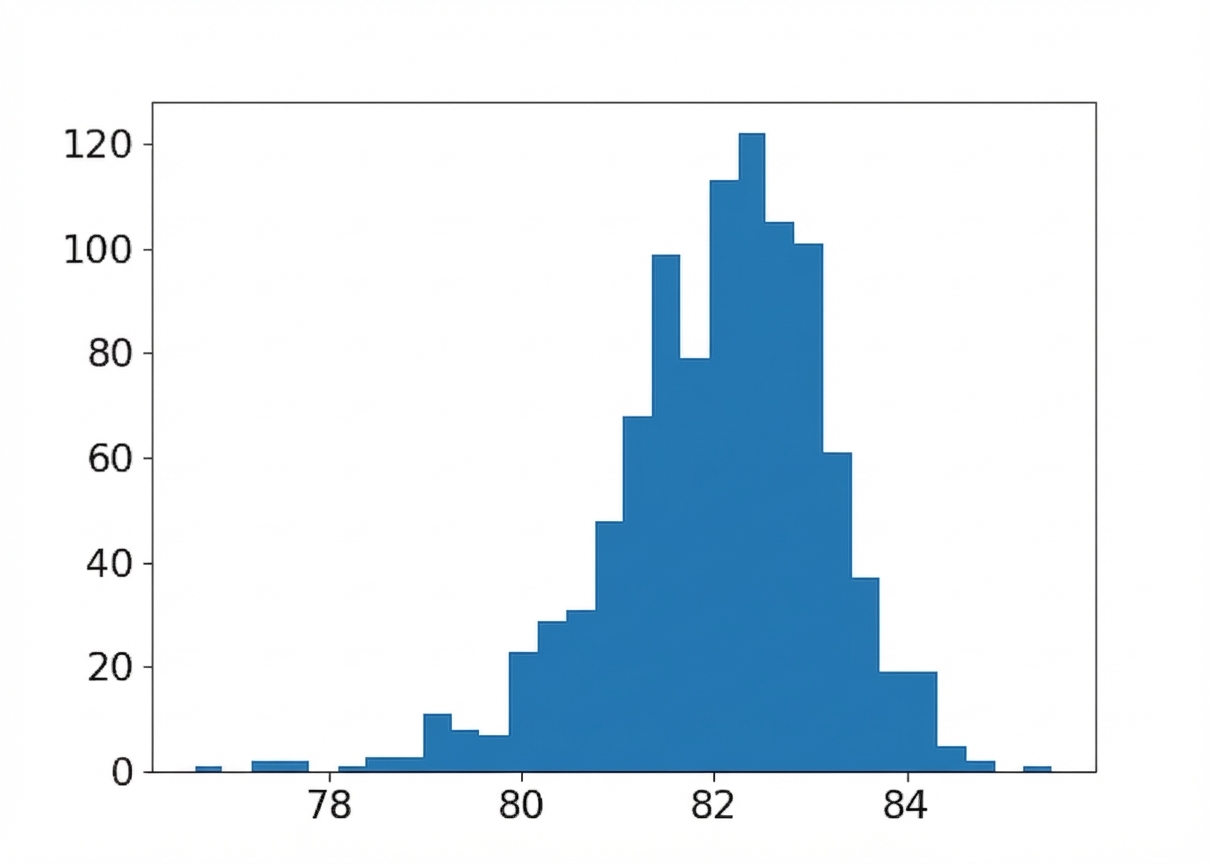
Taille d’échantillon : 150