Fractionnement des données externes pour la récupération
Développement d'applications LLM avec LangChain

Jonathan Bennion
AI Engineer & LangChain Contributor
Étapes du développement RAG
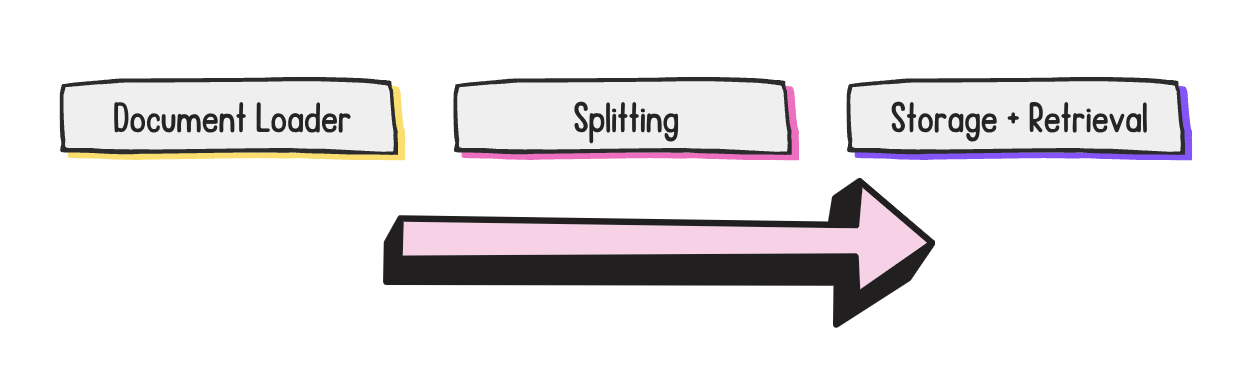
- Division de documents : diviser un document en plusieurs parties
- Divisez les documents pour qu'ils s'adaptent à la fenêtre contextuelle d'un LLM
Chevauchement de morceaux

Quelle est la meilleure stratégie pour diviser un document ?

1 Wikipedia Commons


{kind=link}