Forêts aléatoires
Machine learning avec des modèles arborescents en Python

Elie Kawerk
Data Scientist
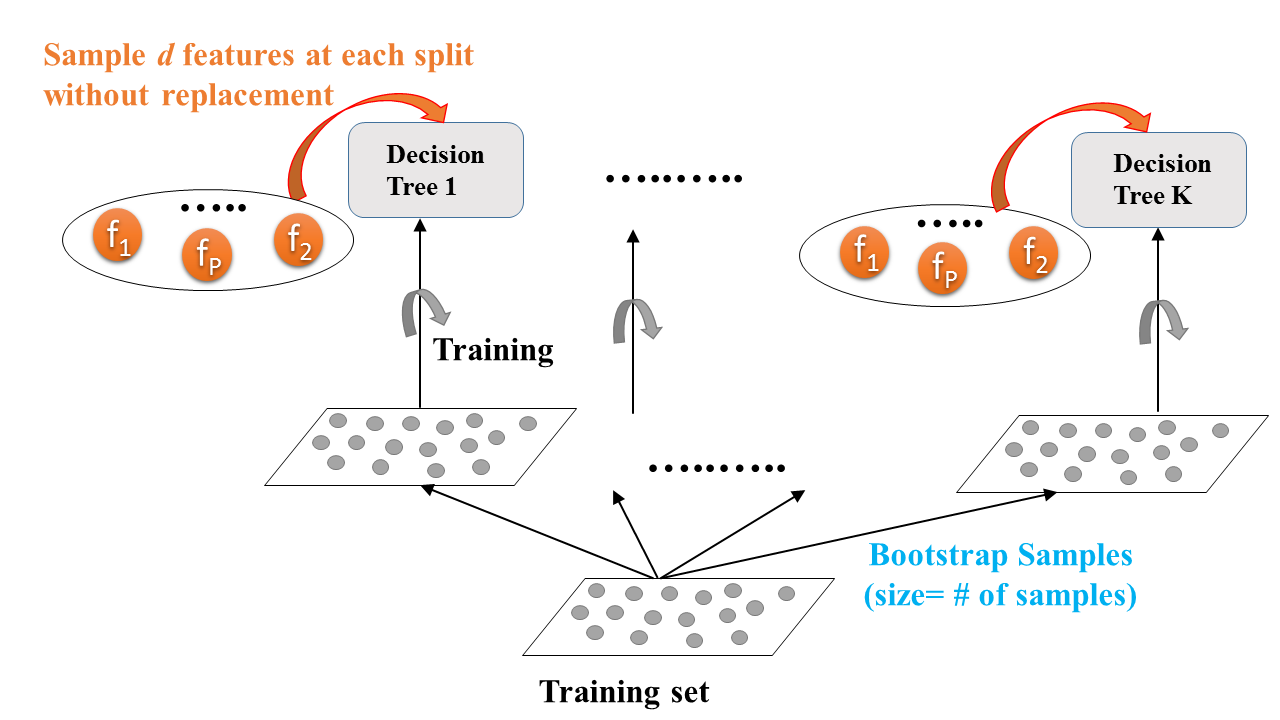
Forêts aléatoires : Entraînement
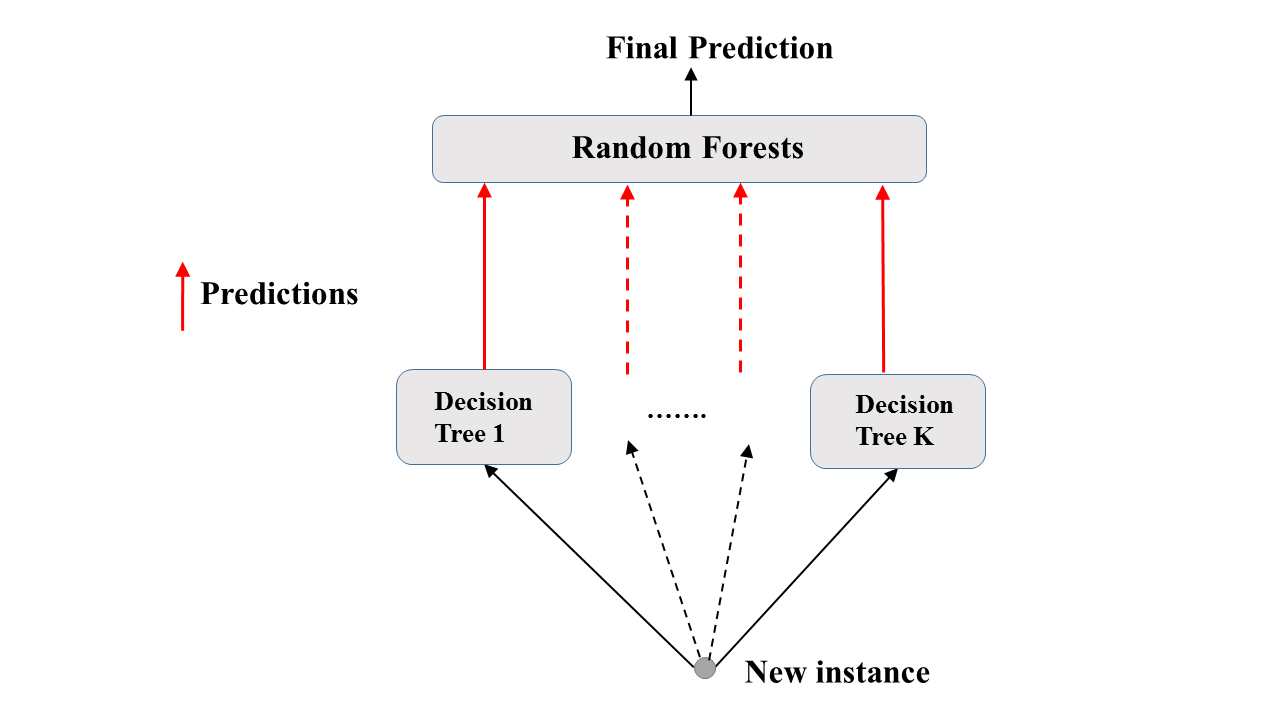
Forêts aléatoires : Prédiction
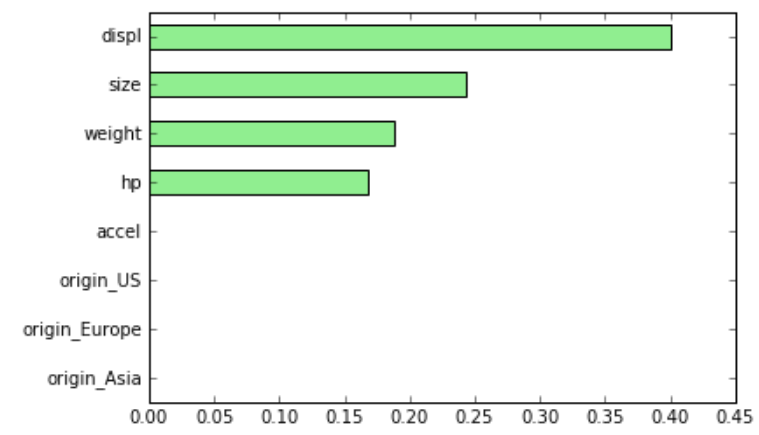
Importance des caractéristiques dans sklearn
Machine learning avec des modèles arborescents en Python
Elie Kawerk
Data Scientist

