Erreur de généralisation
Machine learning avec des modèles arborescents en Python

Elie Kawerk
Data Scientist
Apprentissage supervisé - En détail
- Apprentissage supervisé : $y =f(x)$, $f$ est inconnue.

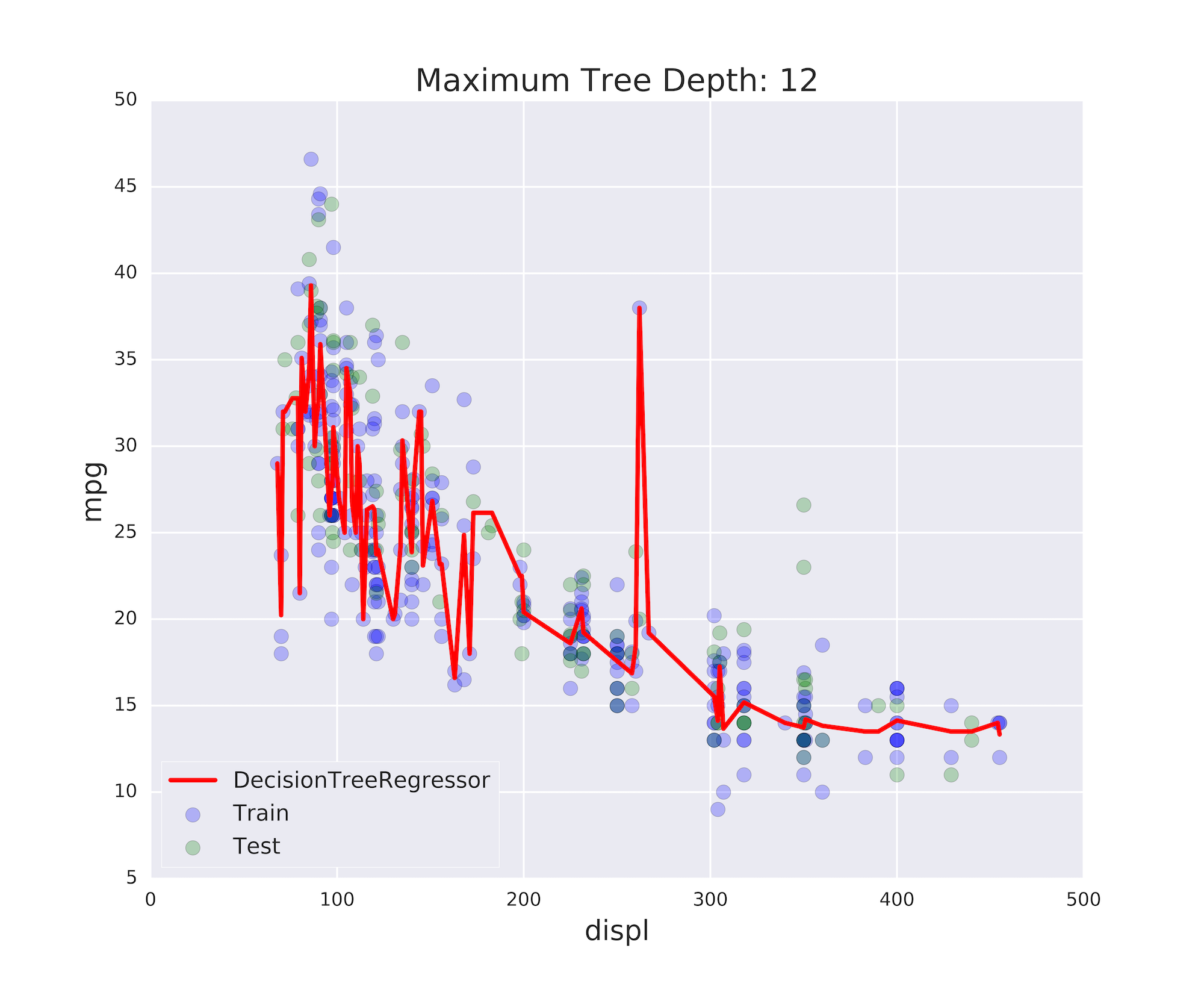
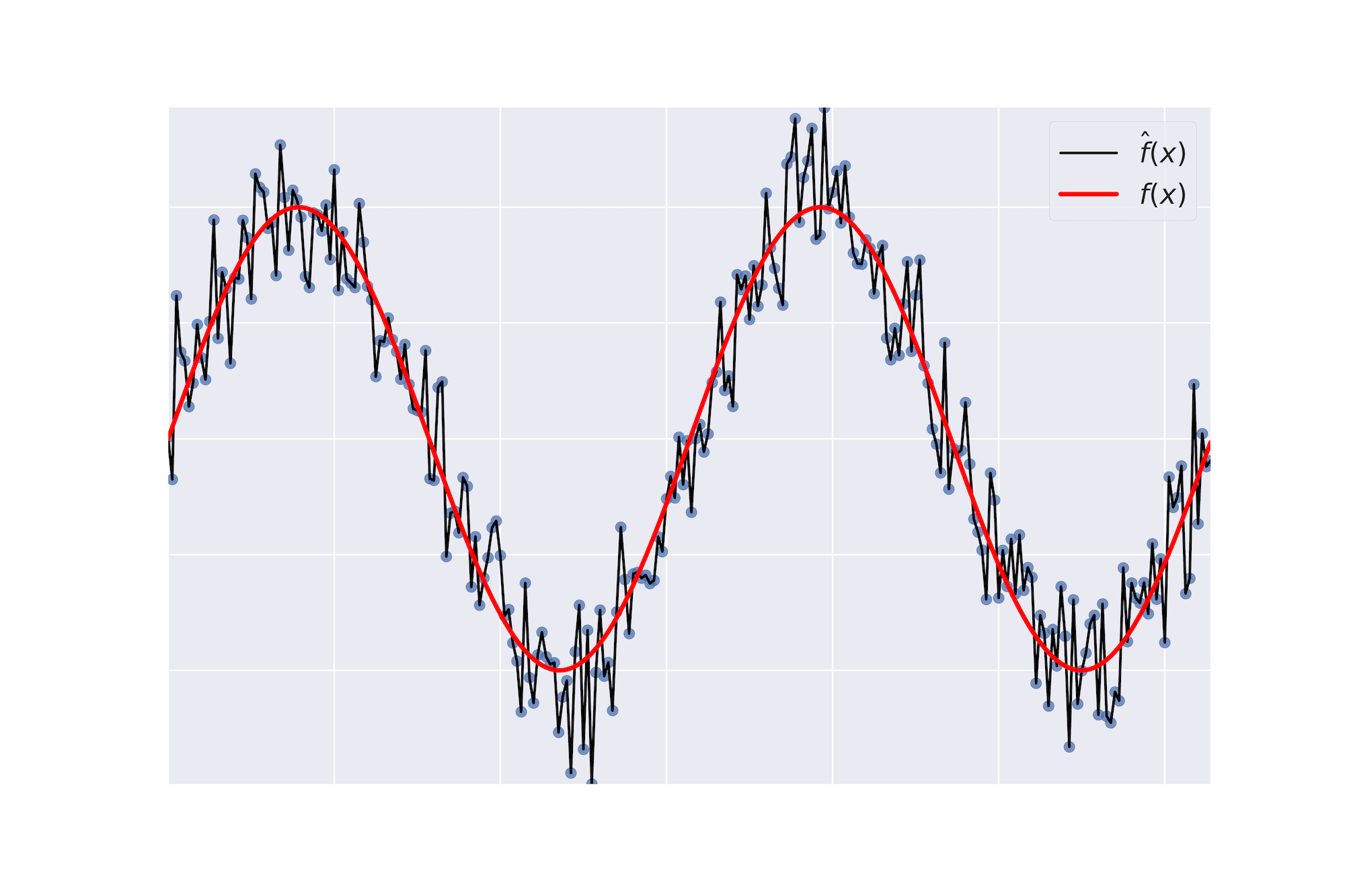
Surajustement
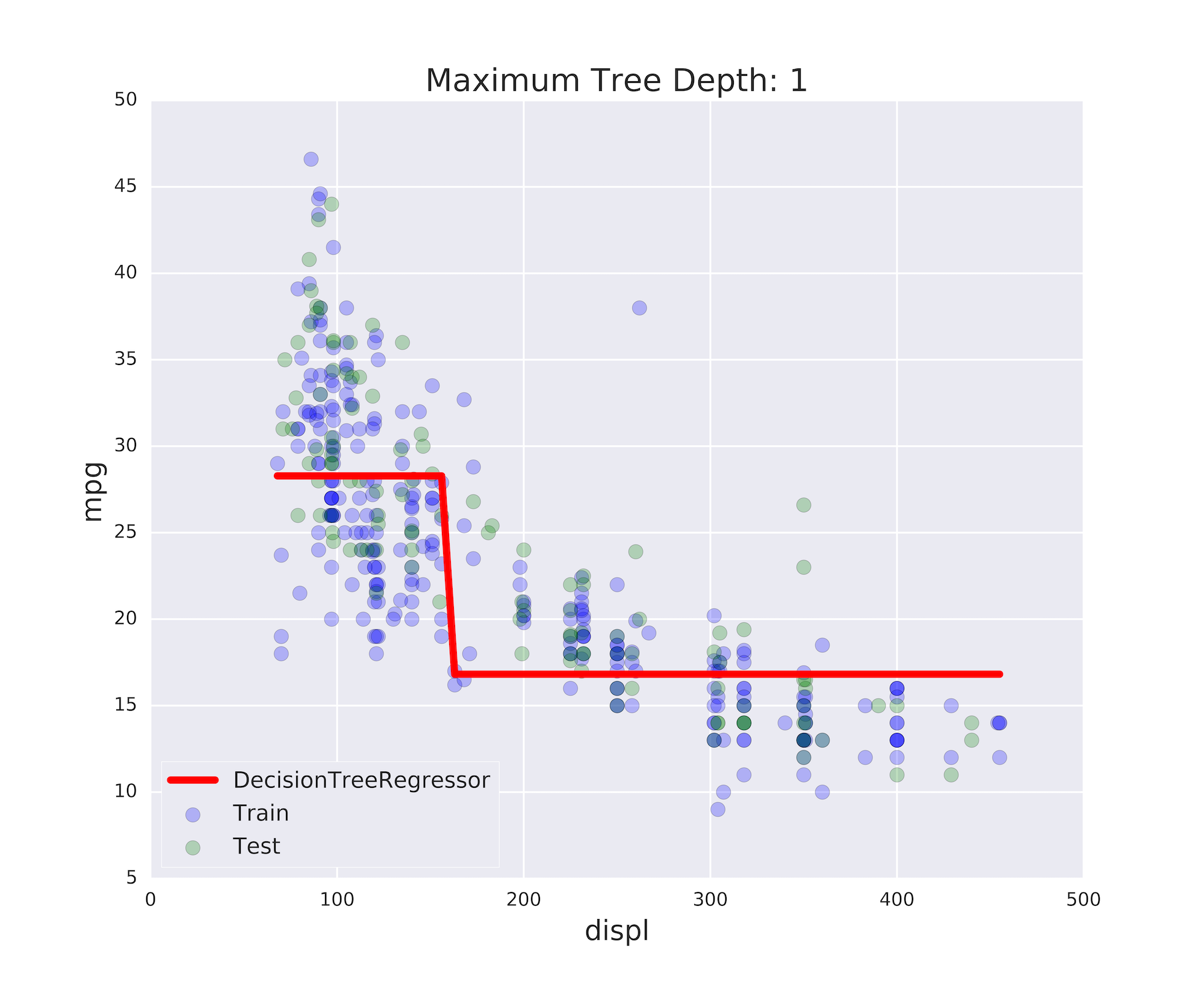
Sous-ajustement
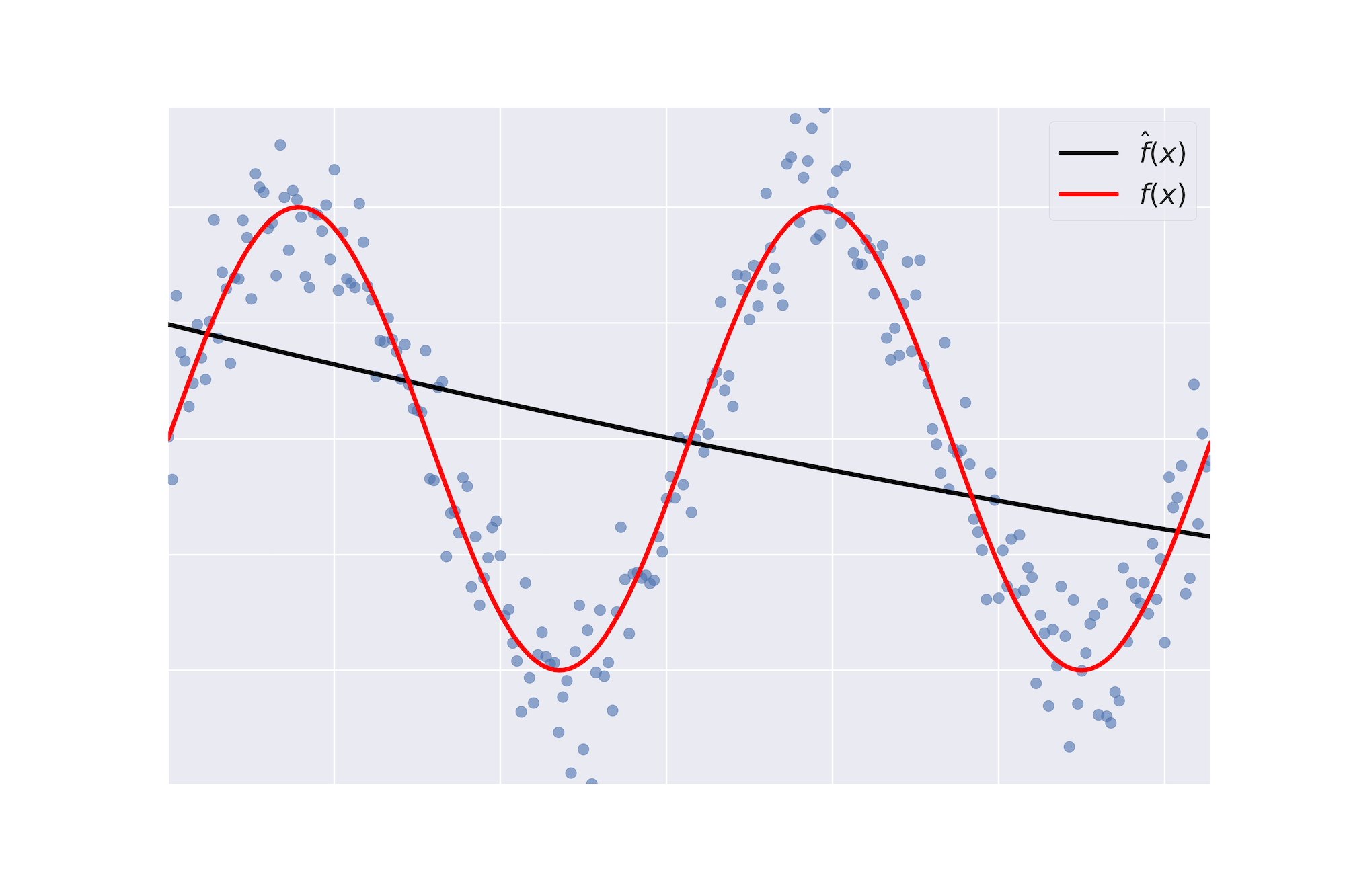
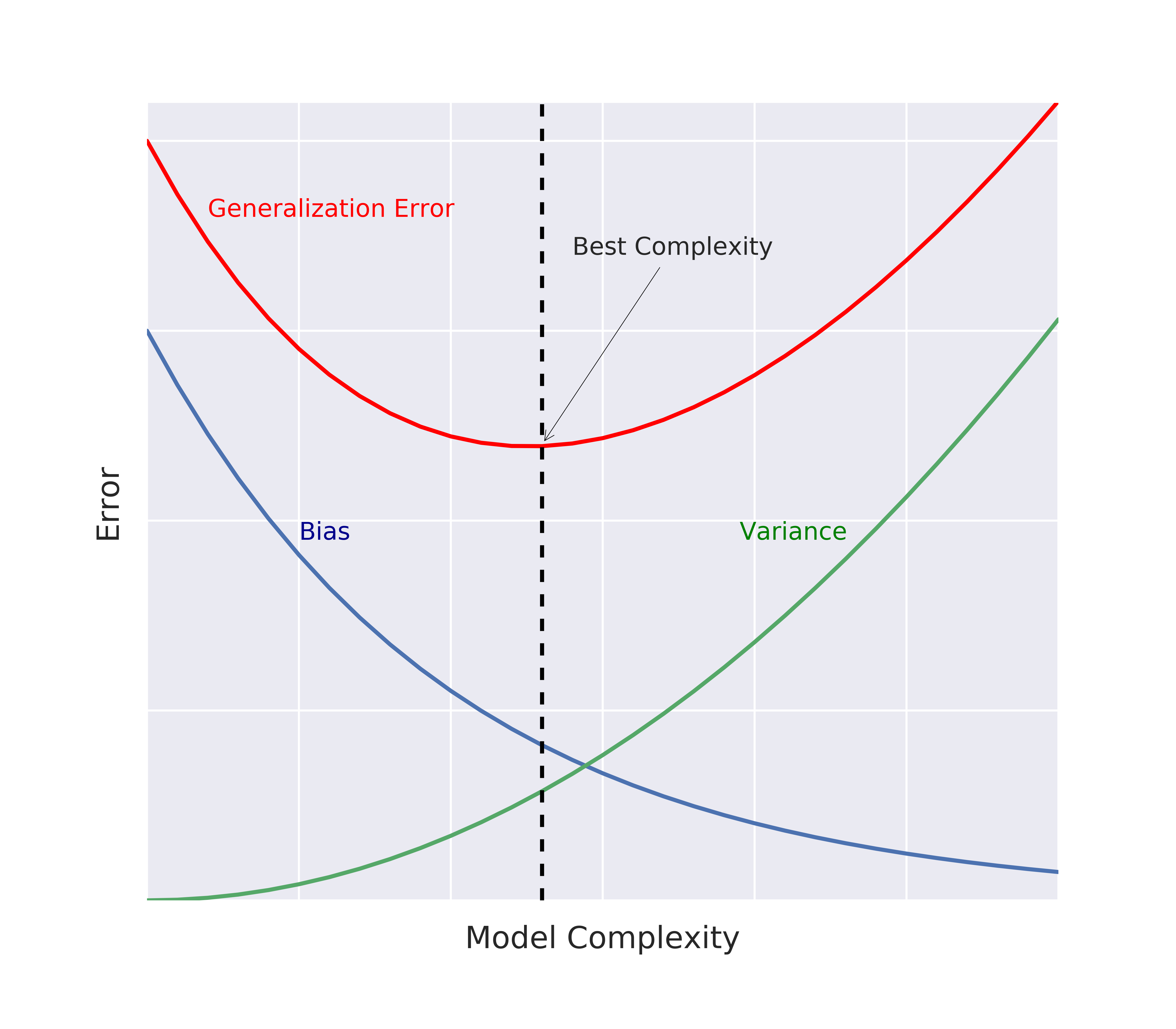
Biais
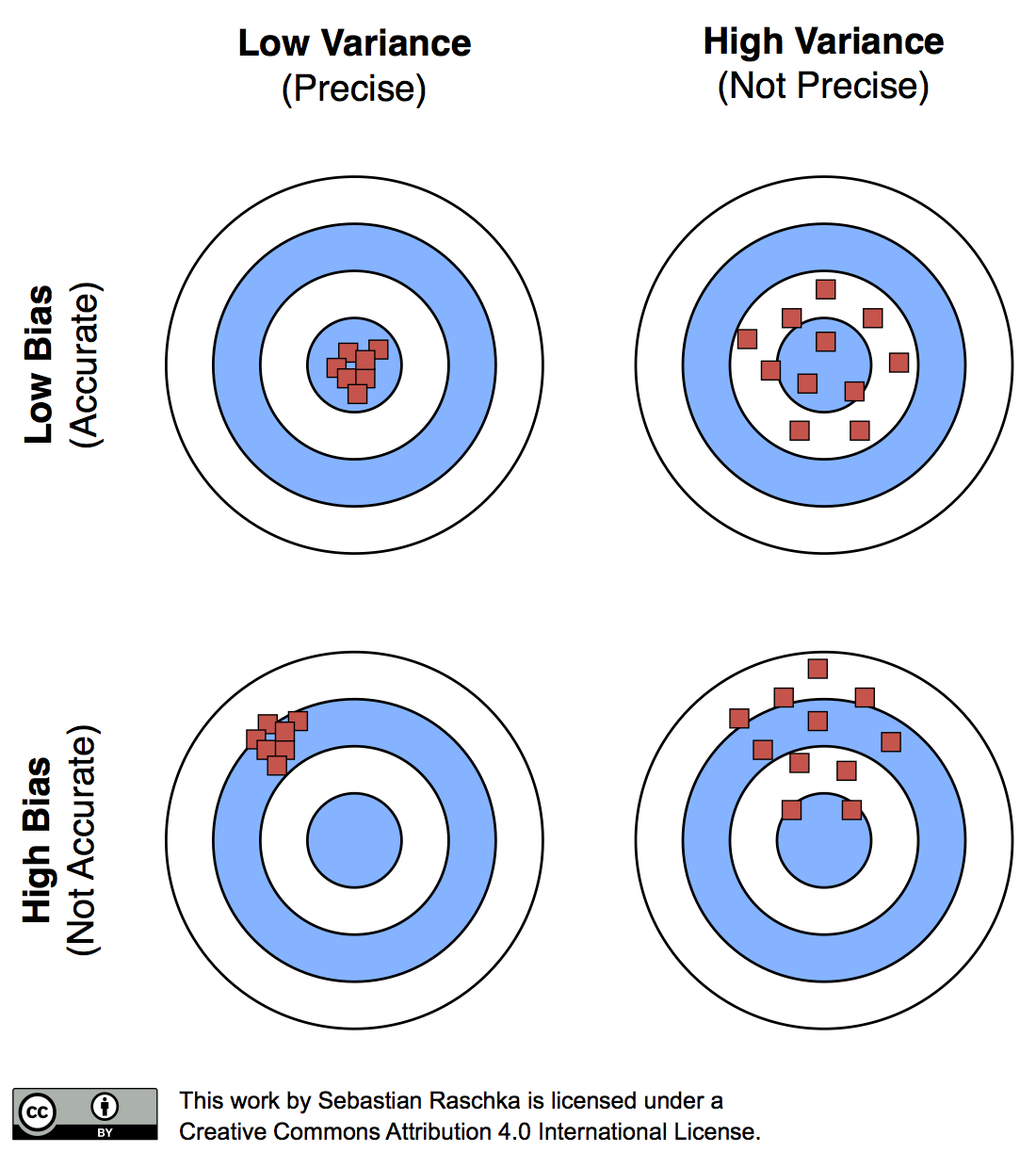
- Biais : terme d'erreur qui indique, en moyenne, la valeur de $\hat{f} \neq f$.
Variance
- Variance : indique le degré d'incohérence de $\hat{f}$ entre différents ensembles d'apprentissage.
Compromis biais-variance
Compromis biais-variance : Une explication visuelle