Ensemble d’apprentissage
Machine learning avec des modèles arborescents en Python

Elie Kawerk
Data Scientist
Avantages des CART
Facile à comprendre.
Facile à interpréter.
Facile à utiliser.
Flexibilité : capacité à décrire des dépendances non linéaires.
Prétraitement : il n'est pas nécessaire de standardiser ou de normaliser les caractéristiques, ...
Limites des CART
Classification : ne peut produire que des frontières de décision orthogonales.
Sensible aux petites variations dans l'ensemble d'entraînement.
Variance élevée : les CART non contraints peuvent surajuster l'ensemble d'entraînement.
Solution : apprentissage collaboratif.
Ensemble d’apprentissage
Entraînez différents modèles sur le même ensemble de données.
Laissez chaque modèle formuler ses prévisions.
Méta-modèle : regroupe les prédictions des modèles individuels.
Prévision finale : plus robuste et moins sujette aux erreurs.
Meilleurs résultats : les modèles sont performants de différentes manières.
Apprentissage collaboratif : Une explication visuelle
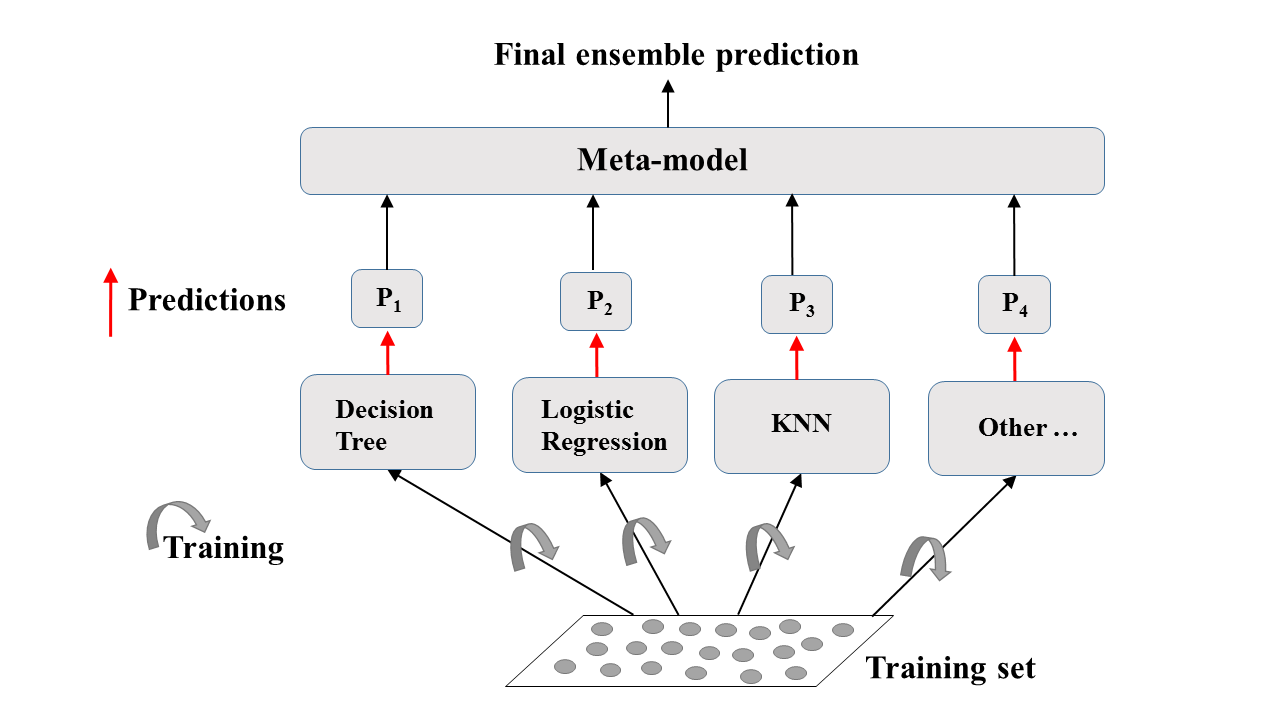
L'apprentissage collaboratif dans la pratique : Classificateur de vote
Tâche de classification binaire.
Les classificateurs $N$ émettent des prédictions : $P_1$, $P_2$, ..., $P_N$ avec $P_i$ = 0 ou 1.
Prévision du méta-modèle : vote rigoureux.
Hard Voting

Classificateur de vote dans sklearn (ensemble de données sur le cancer du sein)
# Import functions to compute accuracy and split data
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
# Import models, including VotingClassifier meta-model
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn.ensemble import VotingClassifier
# Set seed for reproducibility
SEED = 1
Classificateur de vote dans sklearn (ensemble de données sur le cancer du sein)
# Split data into 70% train and 30% test X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.3, random_state= SEED) # Instantiate individual classifiers lr = LogisticRegression(random_state=SEED) knn = KNN() dt = DecisionTreeClassifier(random_state=SEED)# Define a list called classifier that contains the tuples (classifier_name, classifier) classifiers = [('Logistic Regression', lr), ('K Nearest Neighbours', knn), ('Classification Tree', dt)]
# Iterate over the defined list of tuples containing the classifiers
for clf_name, clf in classifiers:
#fit clf to the training set
clf.fit(X_train, y_train)
# Predict the labels of the test set
y_pred = clf.predict(X_test)
# Evaluate the accuracy of clf on the test set
print('{:s} : {:.3f}'.format(clf_name, accuracy_score(y_test, y_pred)))
Logistic Regression: 0.947
K Nearest Neighbours: 0.930
Classification Tree: 0.930
Classificateur de vote dans sklearn (ensemble de données sur le cancer du sein)
# Instantiate a VotingClassifier 'vc'
vc = VotingClassifier(estimators=classifiers)
# Fit 'vc' to the traing set and predict test set labels
vc.fit(X_train, y_train)
y_pred = vc.predict(X_test)
# Evaluate the test-set accuracy of 'vc'
print('Voting Classifier: {.3f}'.format(accuracy_score(y_test, y_pred)))
Voting Classifier: 0.953
Passons à la pratique !
Machine learning avec des modèles arborescents en Python

