Arbre de décision pour la classification
Machine learning avec des modèles arborescents en Python

Elie Kawerk
Data Scientist
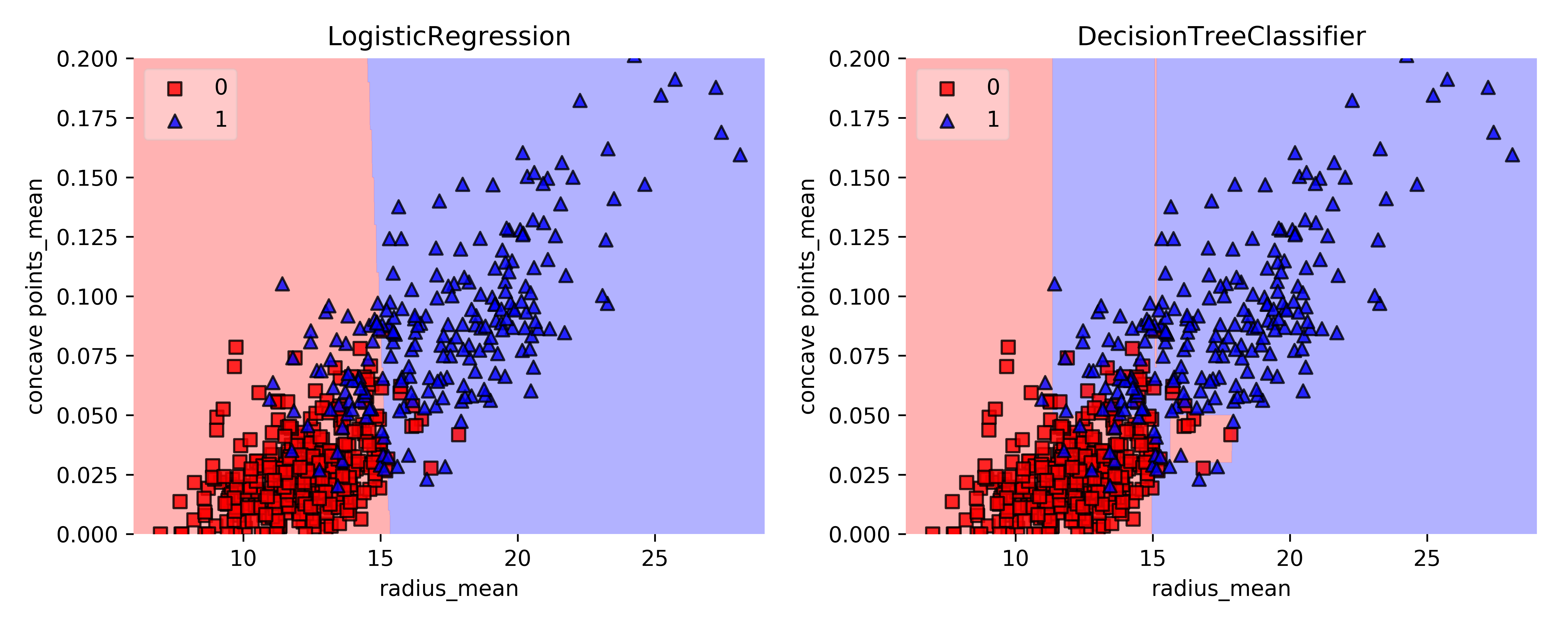
Ensemble de données sur le cancer du sein en 2D
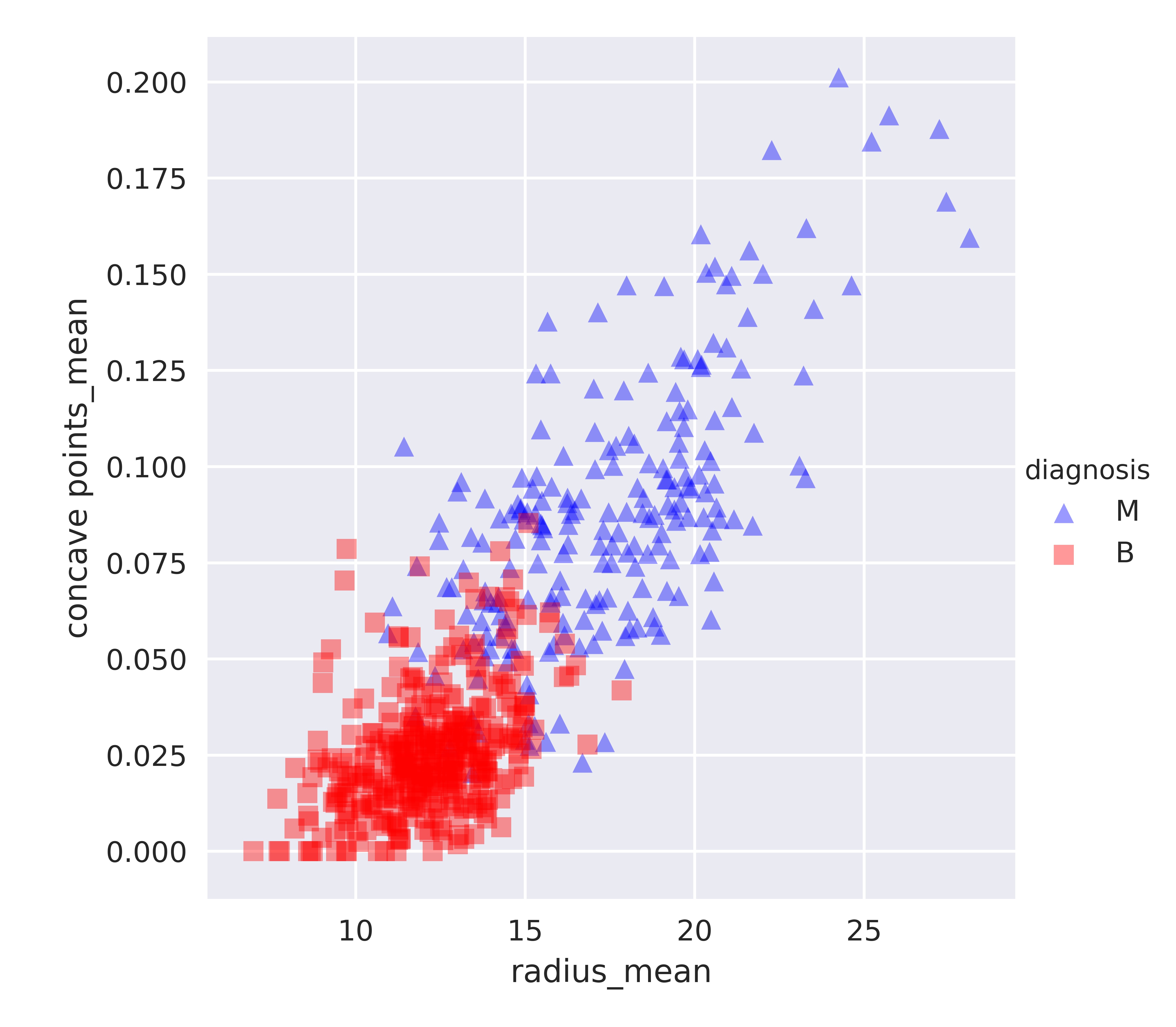
Diagramme d'arbre décisionnel

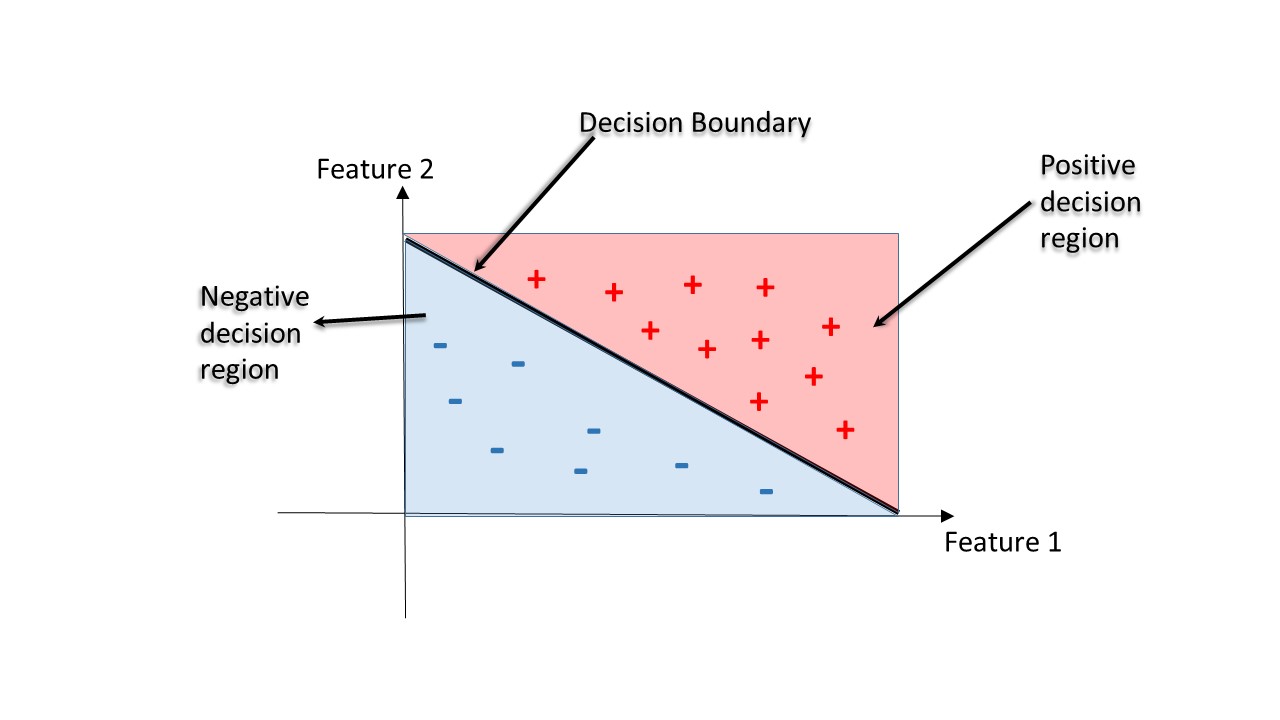
Régions décisionnelles
Région de décision : région de l'espace des caractéristiques où toutes les instances sont attribuées à une seule étiquette de classe.
Limite de décision : surface séparant différentes régions de décision.
Régions décisionnelles : CART vs Modèle linéaire