Cadres de calcul parallèle
Introduction au data engineering

Vincent Vankrunkelsven
Data Engineer @ DataCamp
![]()
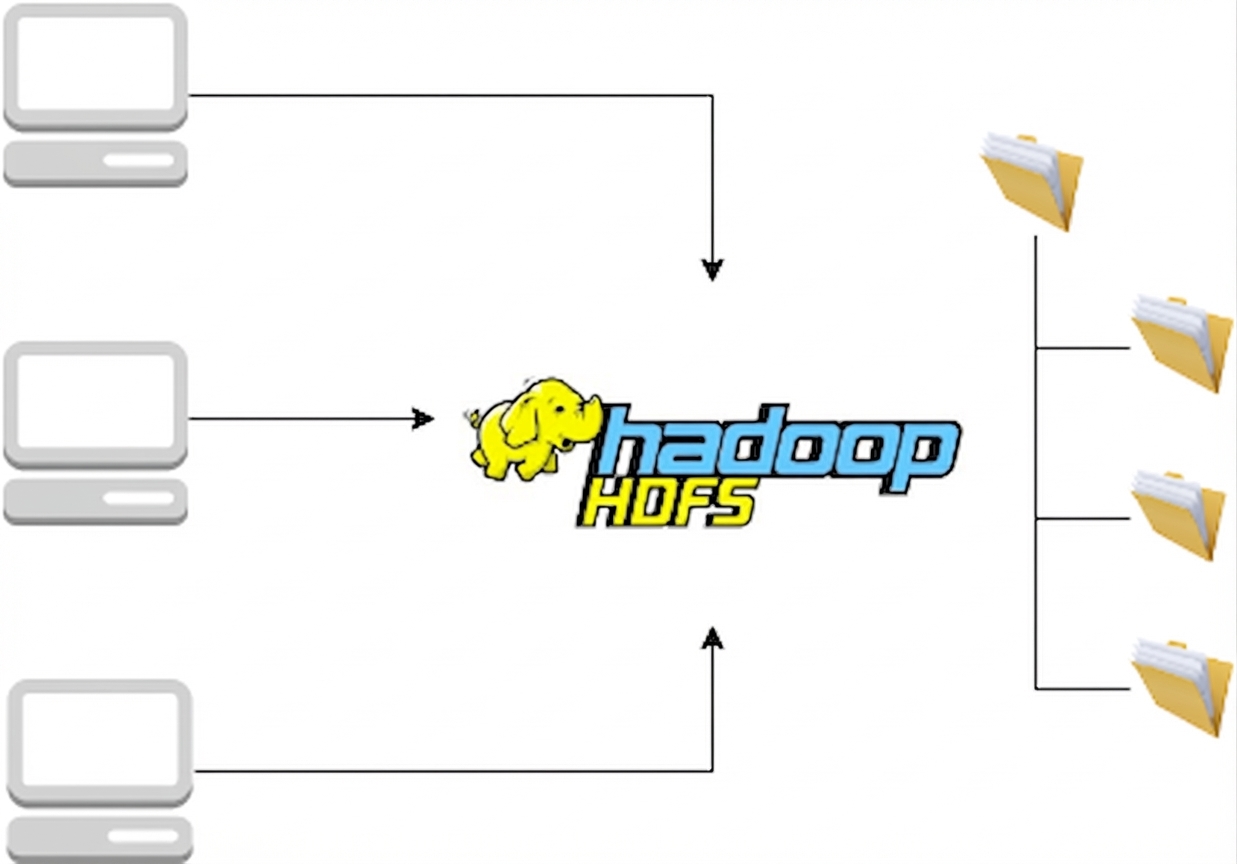
HDFS
MapReduce
![]()

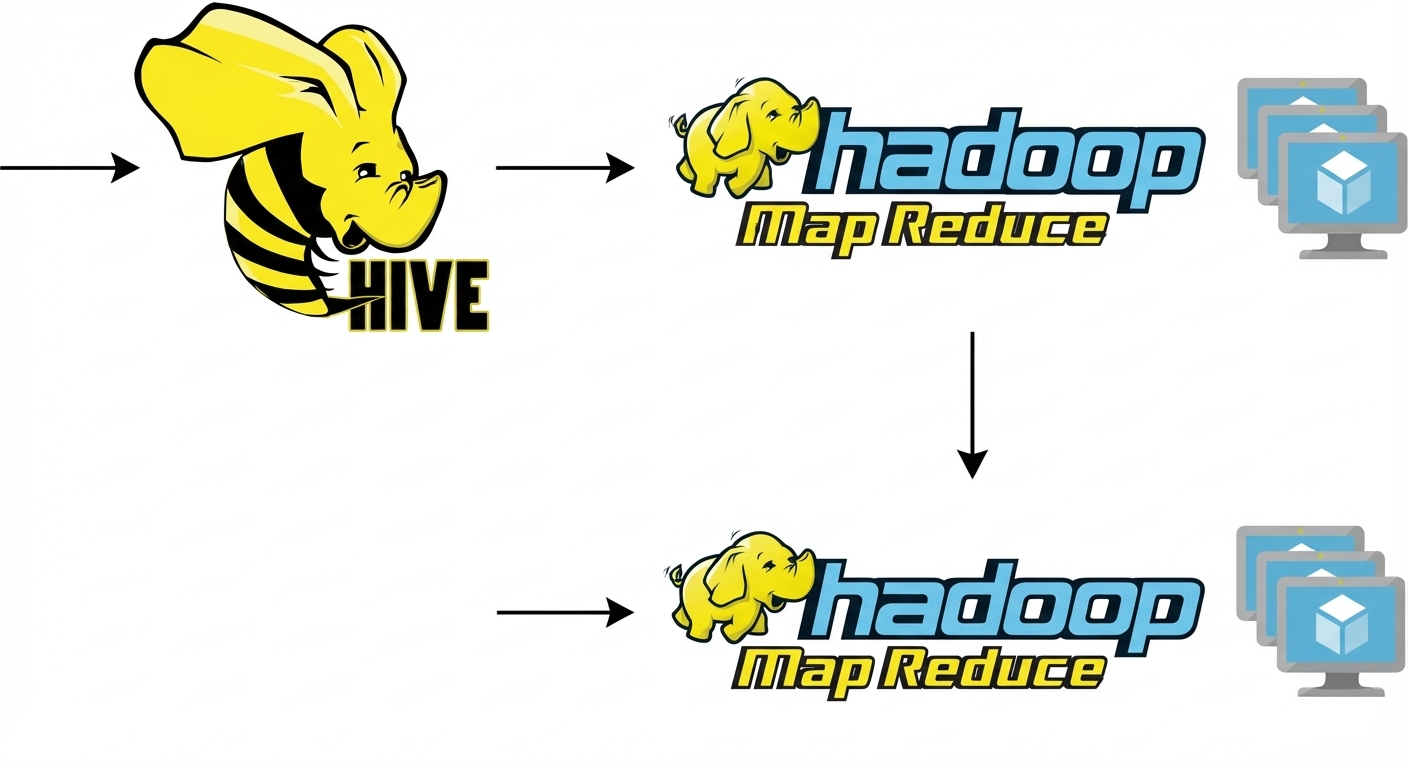
Hive
- S’exécute sur Hadoop
- Langage SQL structuré : Hive SQL
- D’abord MapReduce, maintenant d’autres outils
![]()
Hive : un exemple
![]()
- Évite les écritures disque
- Géré par l’Apache Software Foundation

