Qu’est-ce que le calcul parallèle
Introduction au data engineering

Vincent Vankrunkelsven
Data Engineer @ DataCamp
Principe du calcul parallèle
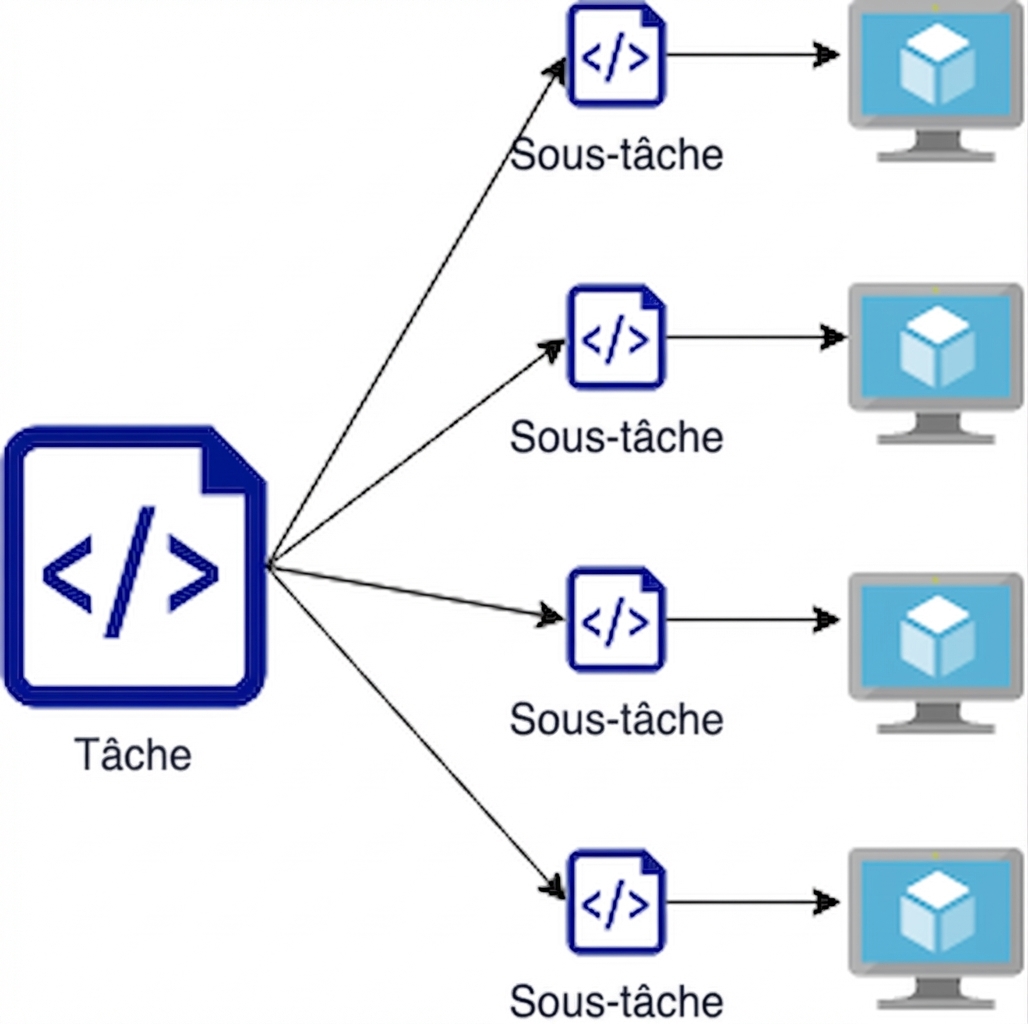
L’atelier de tailleur
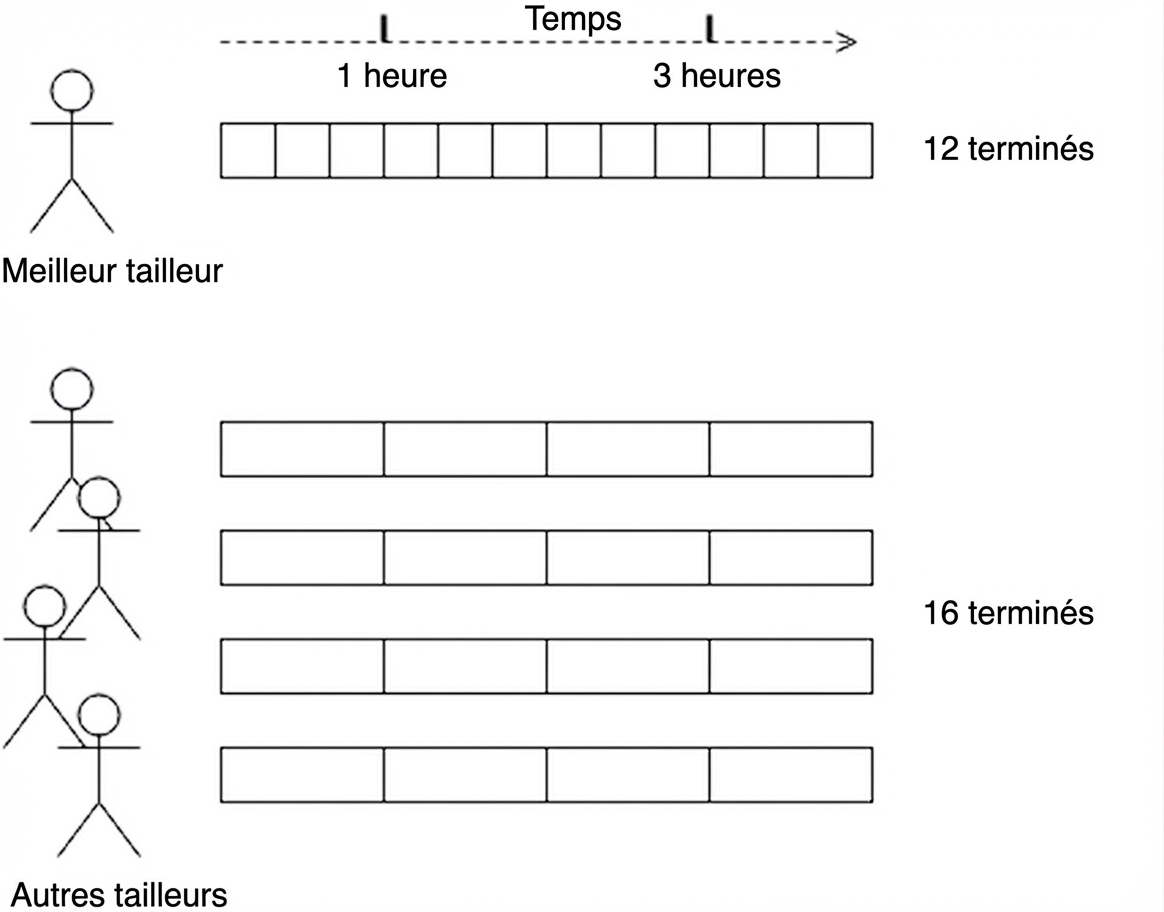
Atouts du calcul parallèle
Puce de mémoire RAM:

Risques du calcul parallèle
Ralentissement en parallèle:
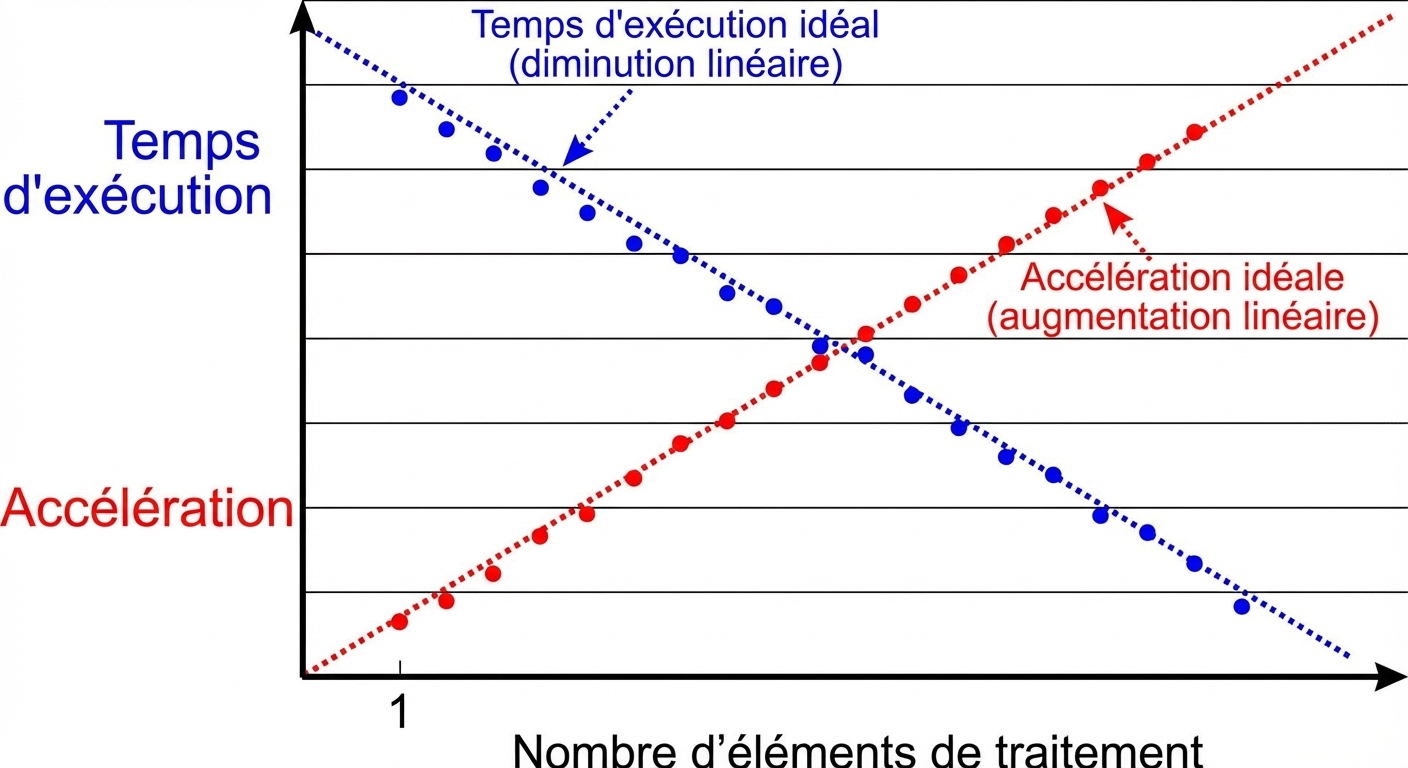
Un exemple


