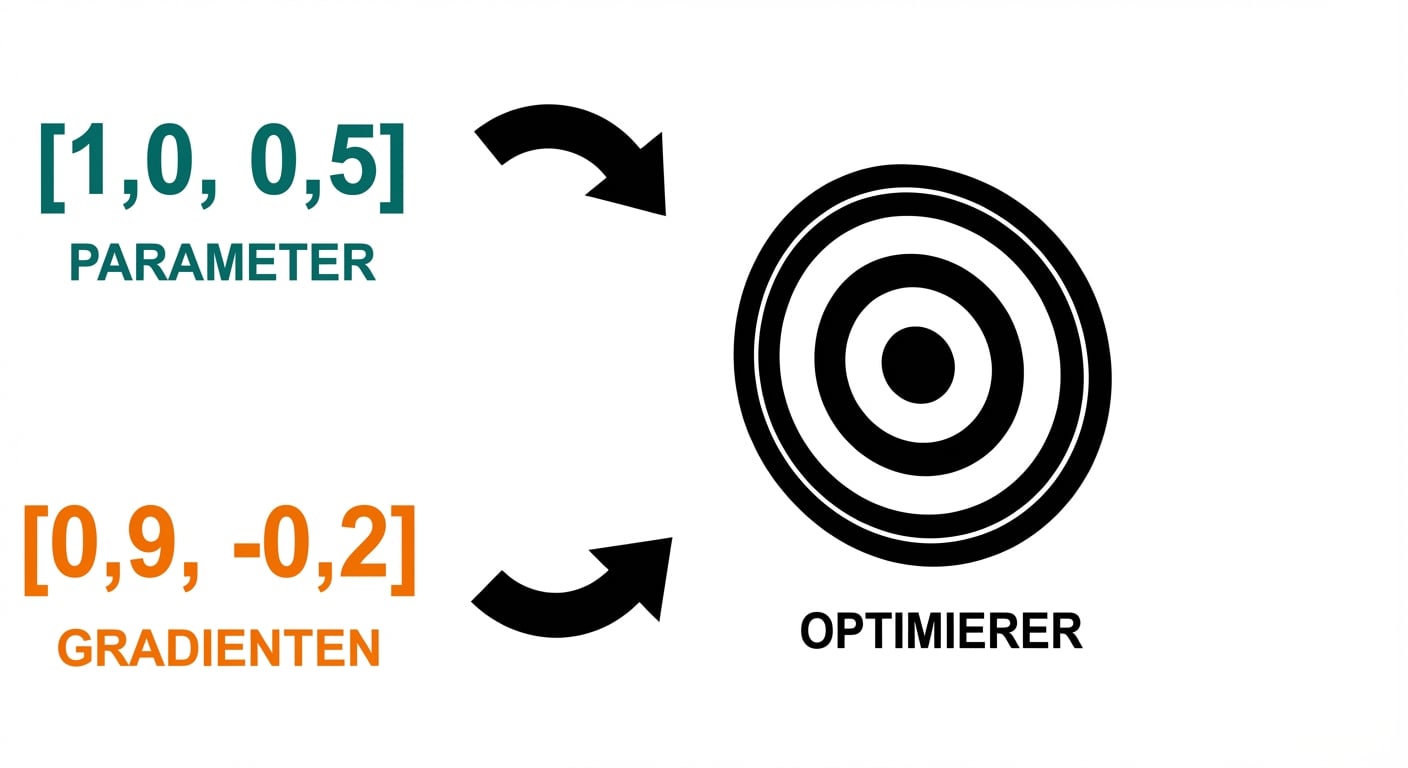
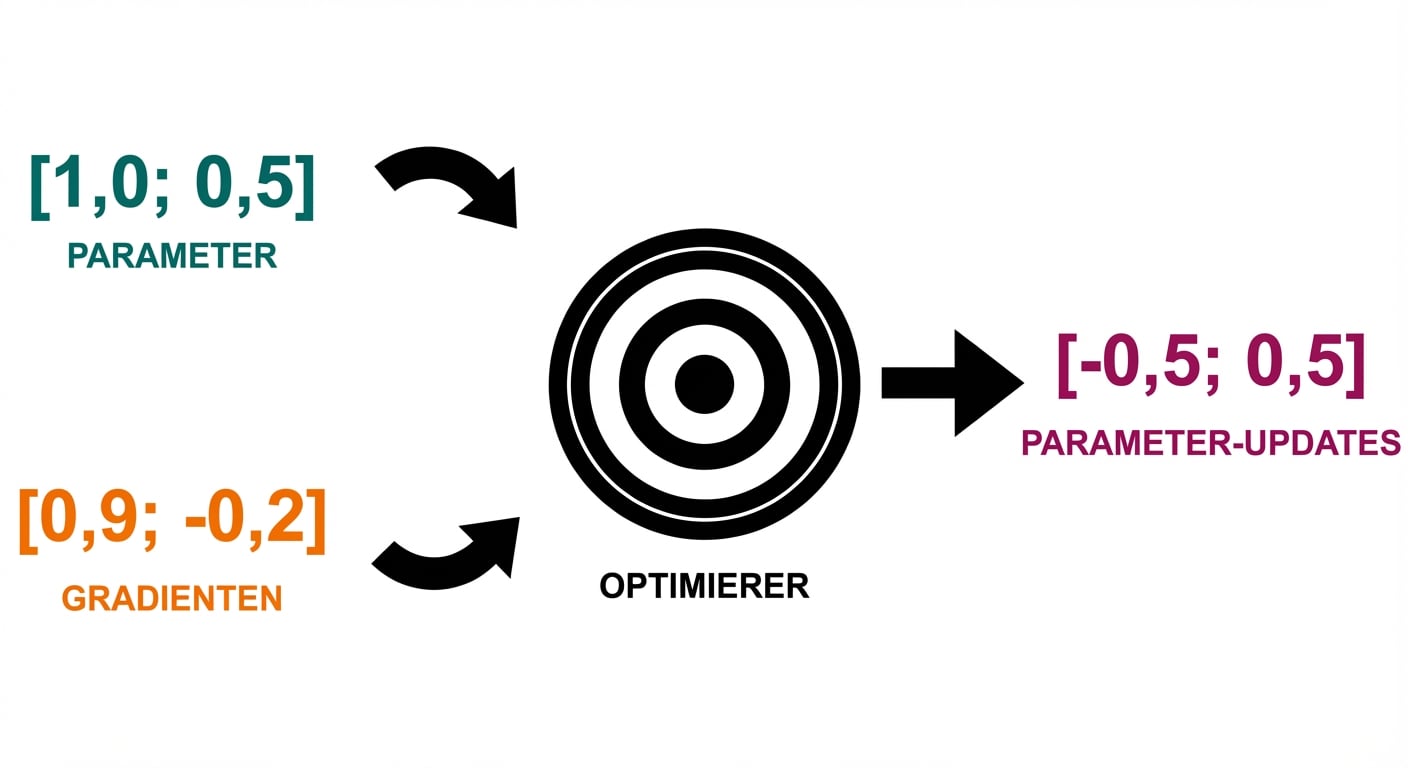
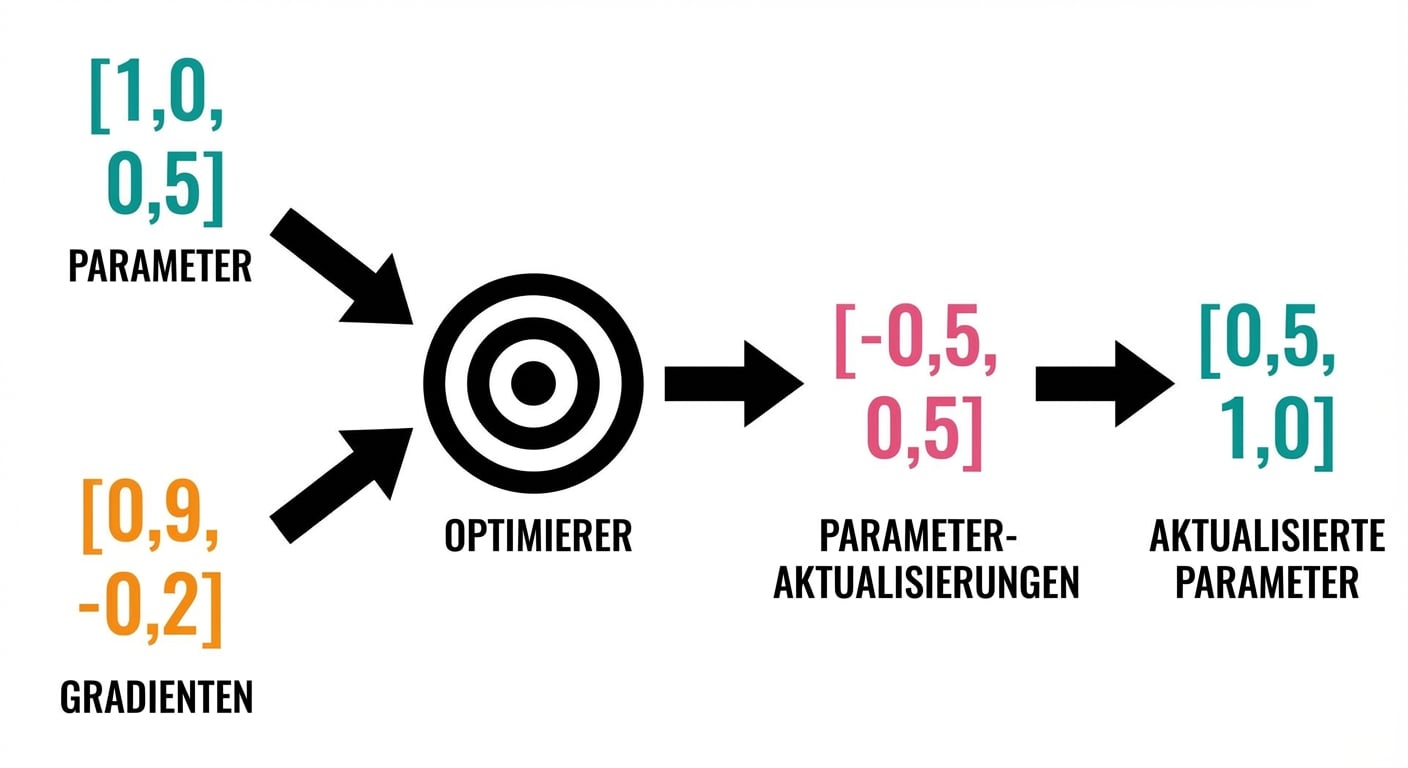
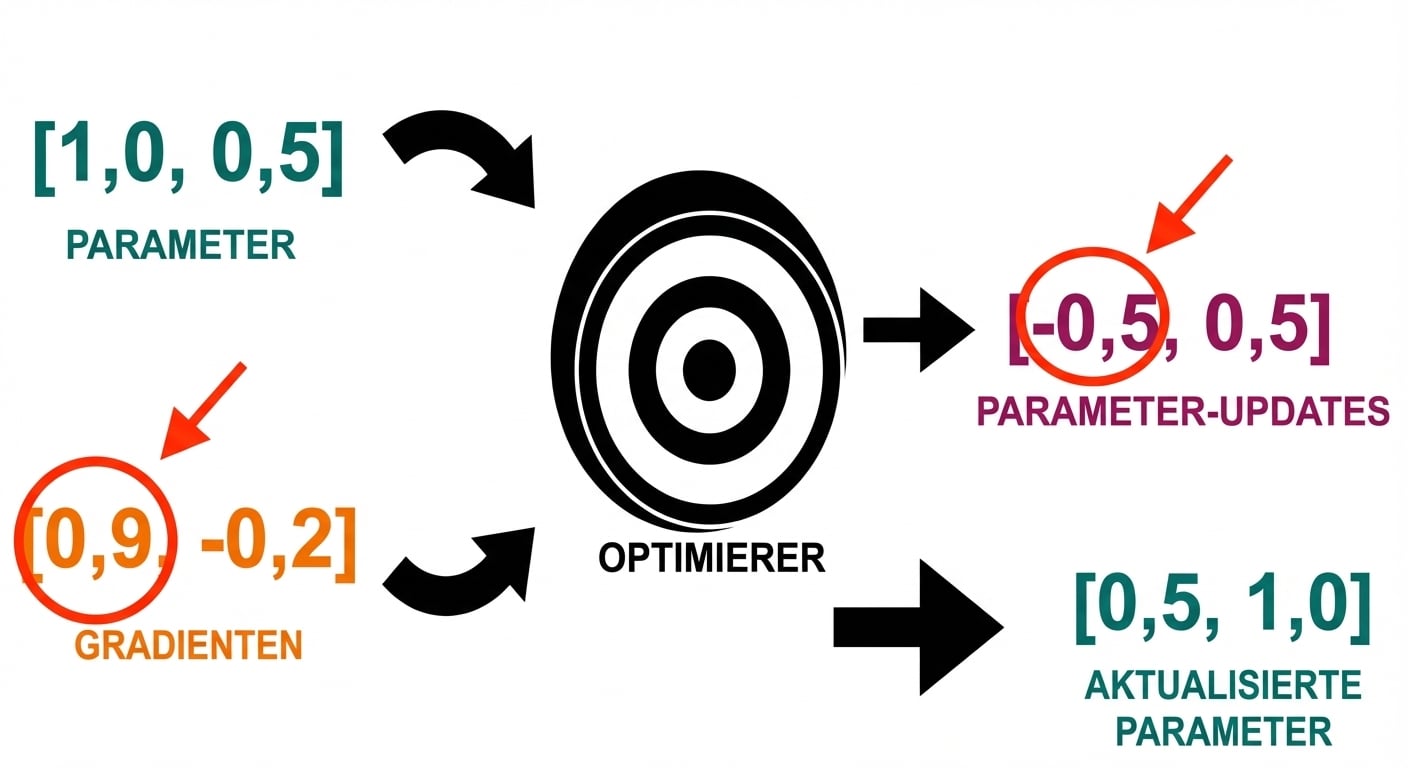
Training-Loop
import torch.nn as nn
import torch.optim as optim
criterion = nn.BCELoss()
optimizer = optim.SGD(net.parameters(), lr=0.01)
for epoch in range(1000):
for features, labels in dataloader_train:
optimizer.zero_grad()
outputs = net(features)
loss = criterion(
outputs, labels.view(-1, 1)
)
loss.backward()
optimizer.step()
- Loss-Funktion und Optimizer festlegen
BCELoss für binäre KlassifikationSGD-Optimizer
- Über Epochen und Trainingsbatches iterieren
- Gradienten zurücksetzen
- Forward-Pass: Modelloutputs holen
- Loss berechnen
- Gradienten berechnen
- Optimizer-Schritt: Parameter updaten