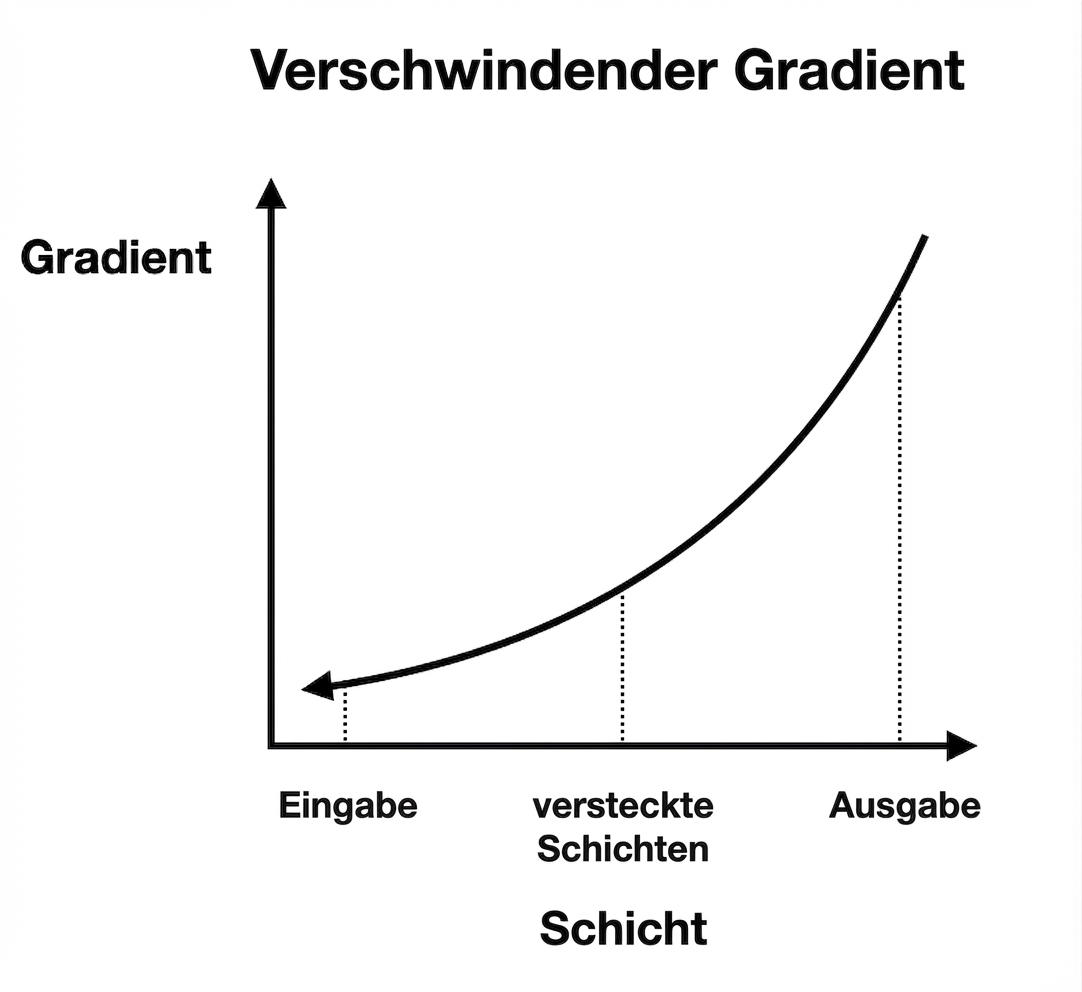
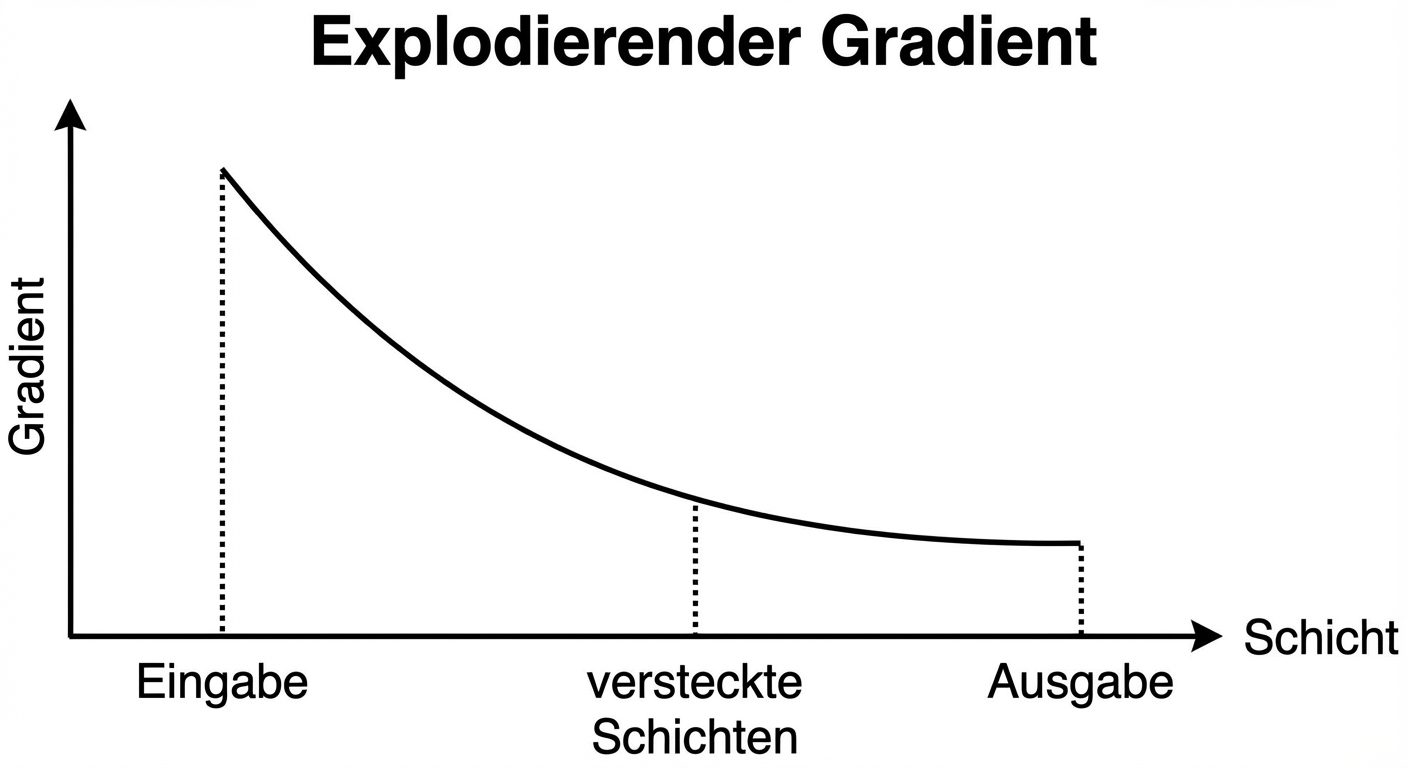
Verschwindende und explodierende Gradienten
Deep Learning mit PyTorch für Fortgeschrittene

Michal Oleszak
Machine Learning Engineer
Verschwindende Gradienten
Explodierende Gradienten
Lösung für instabile Gradienten
- Saubere Gewichtsinitialisierung
- Gute Aktivierungen
- Batch-Normalisierung

Aktivierungsfunktionen
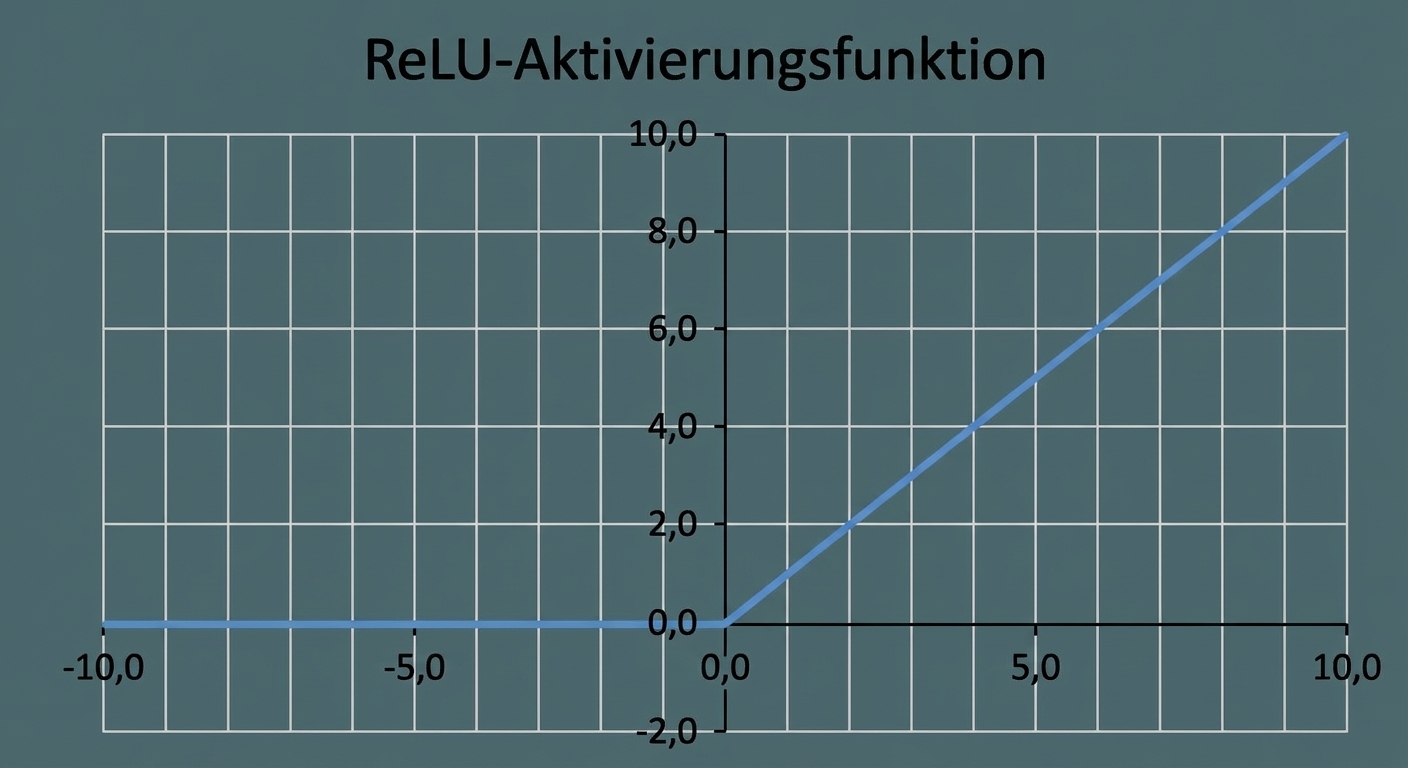
- Oft Standardaktivierung
nn.functional.relu()- Null für negative Eingaben – tote Neuronen
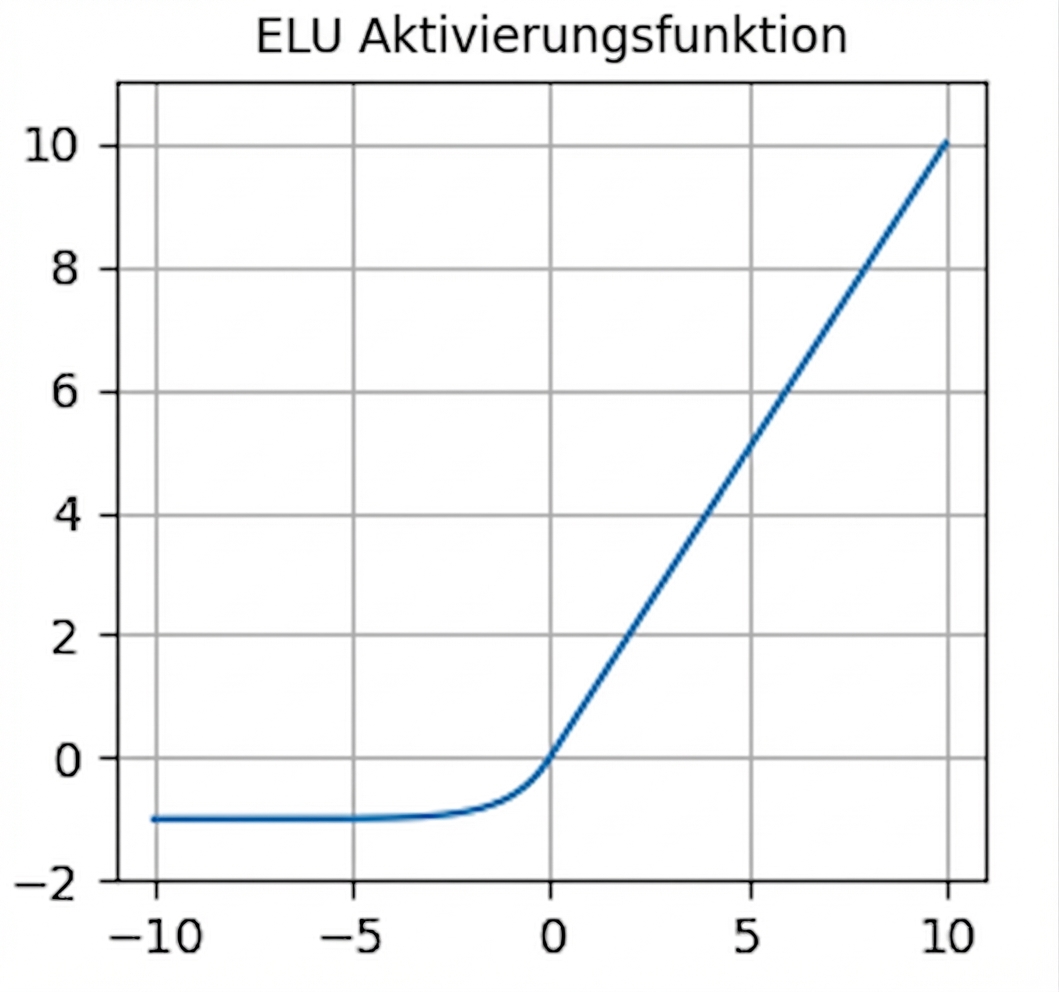
nn.functional.elu()- Nicht-null Gradienten für negative Werte – hilft gegen tote Neuronen
- Mittlerer Output um 0 – hilft gegen verschwindende Gradienten

