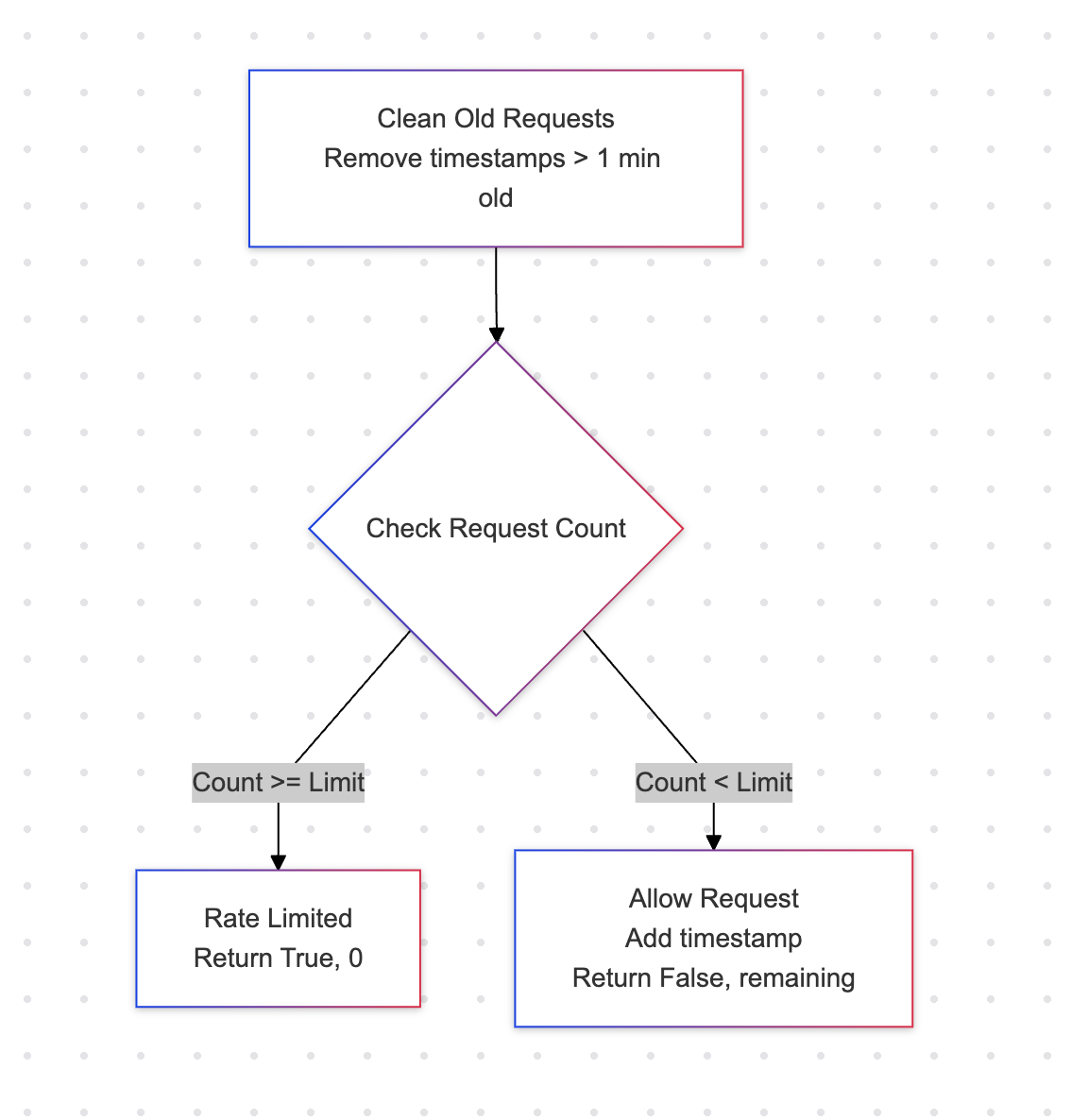
Rate Limiting
Deploying AI into Production with FastAPI

Matt Eckerle
Software and Data Engineering Leader
Introducing rate limiting

How rate limiting works
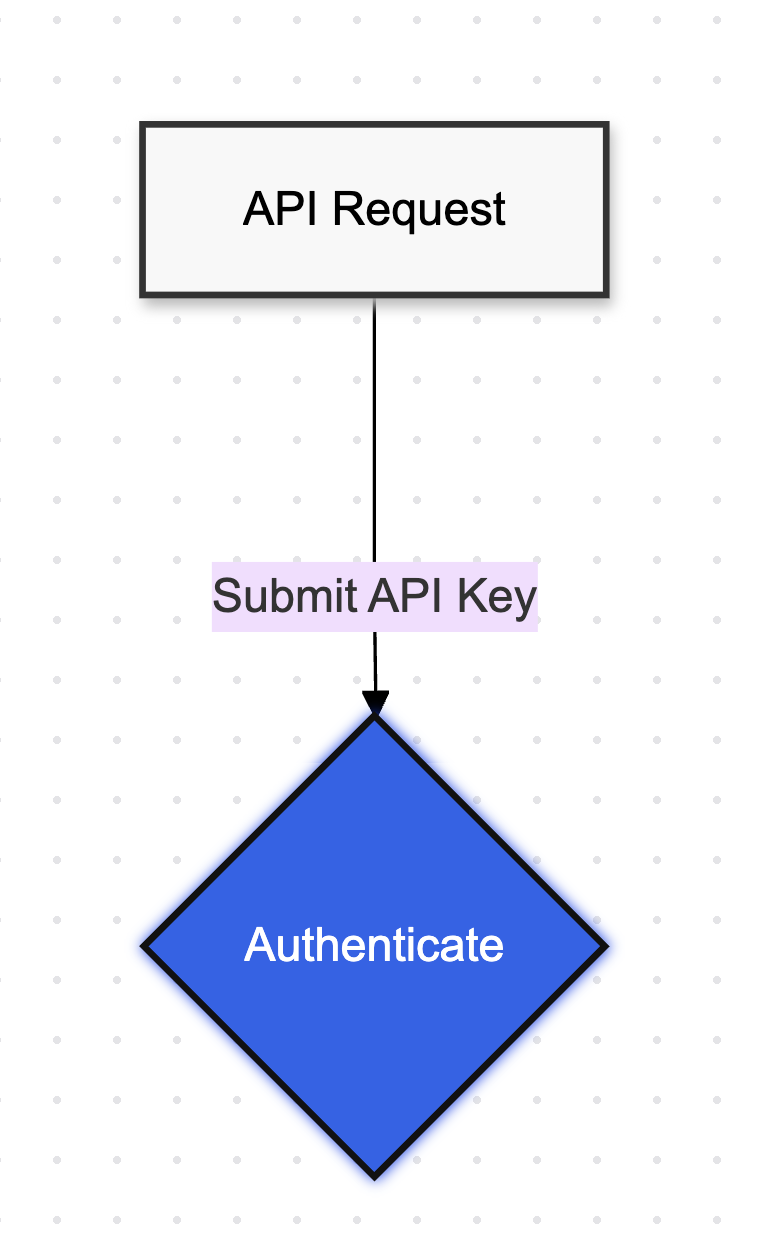
Authenticating incoming credentials
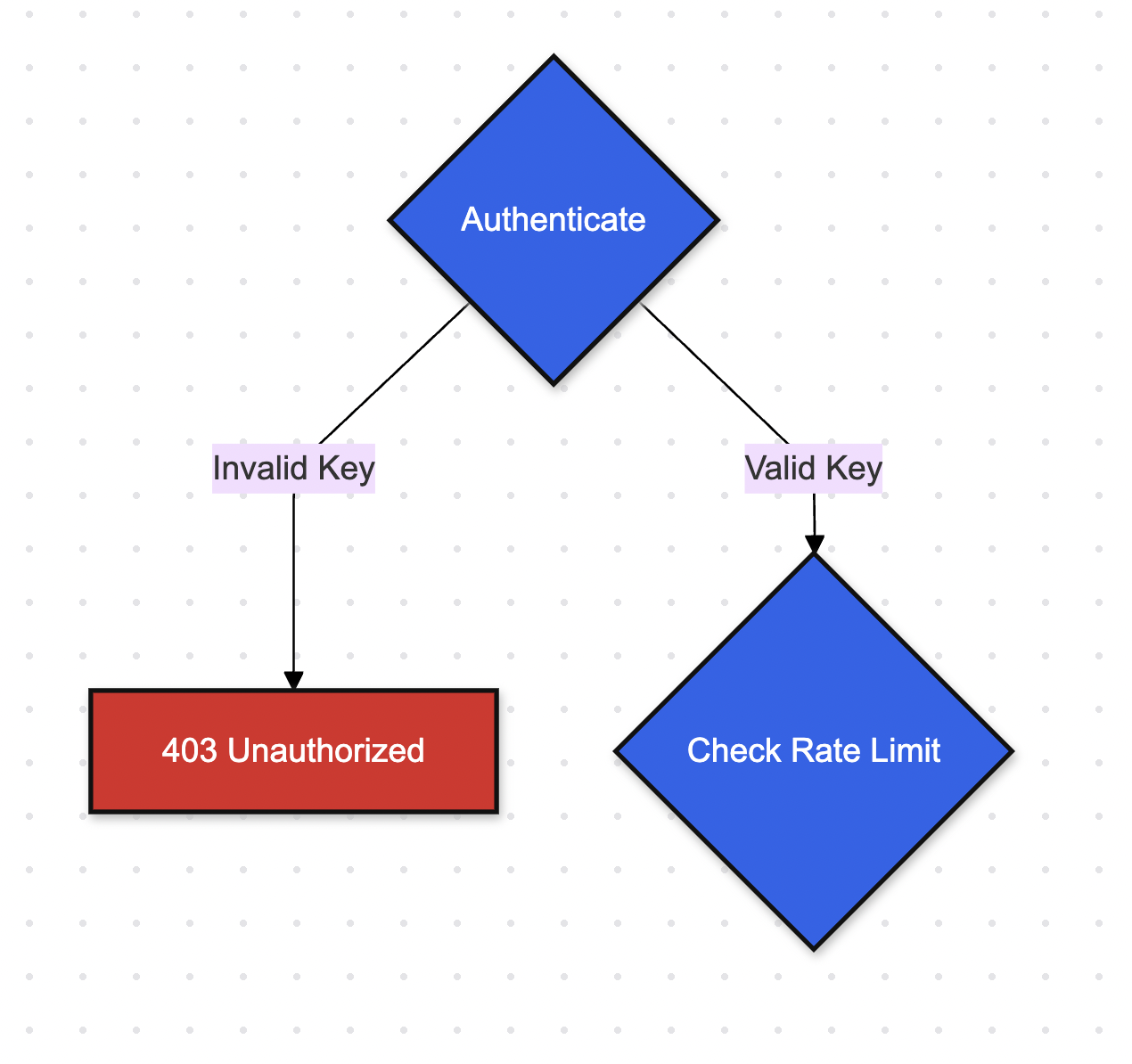
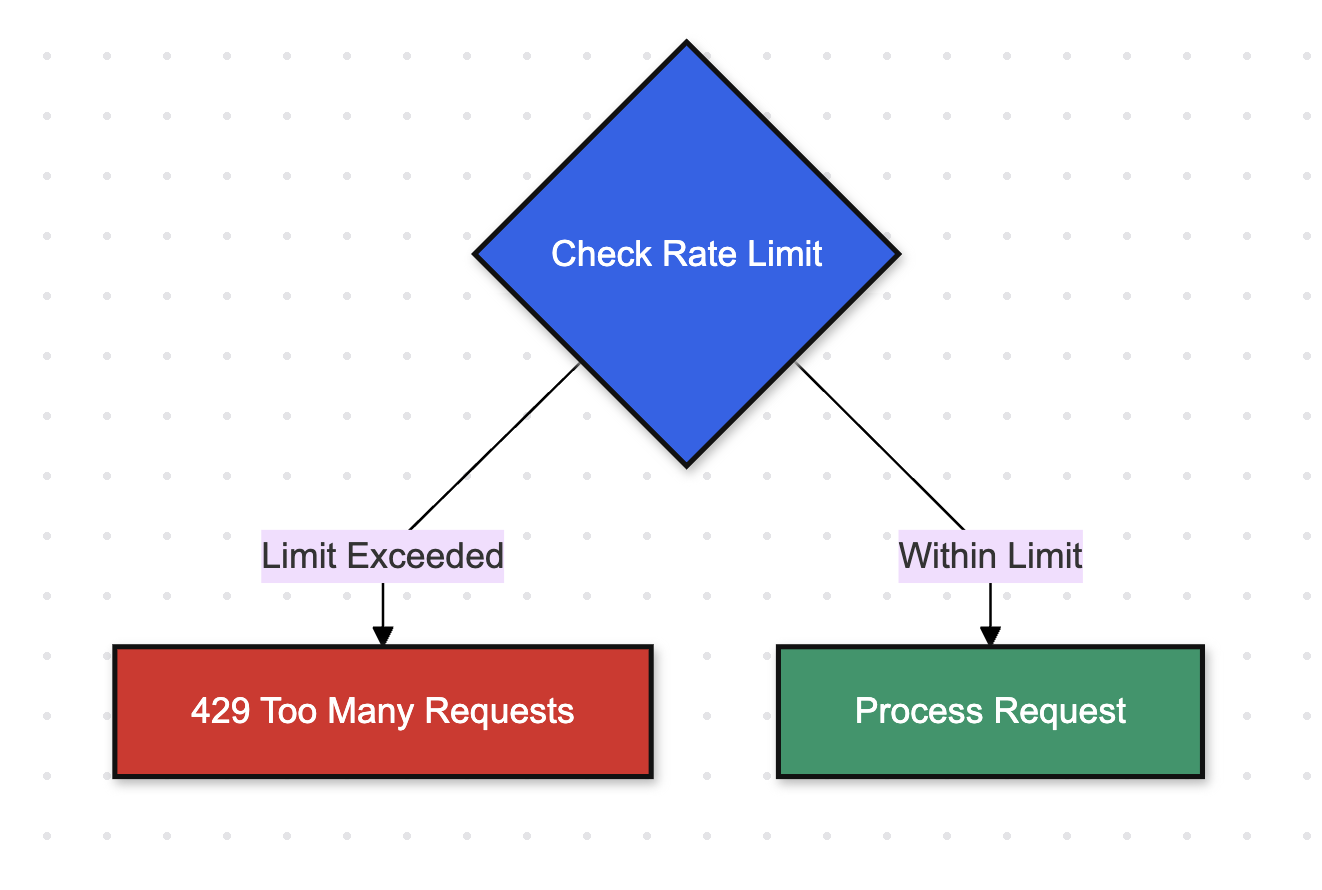
Rate limiting check
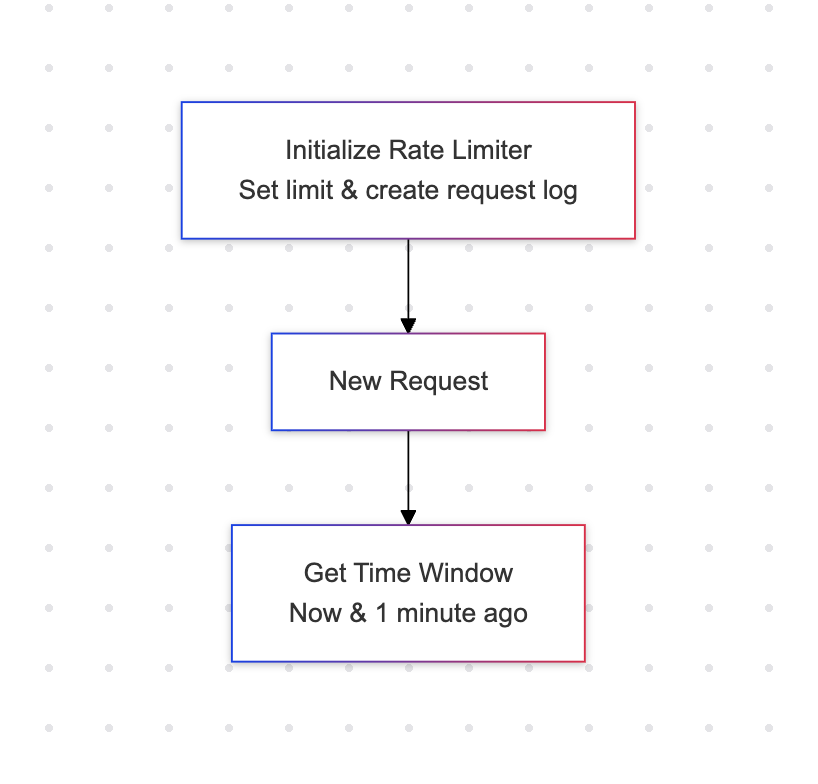
The rate limiter logic
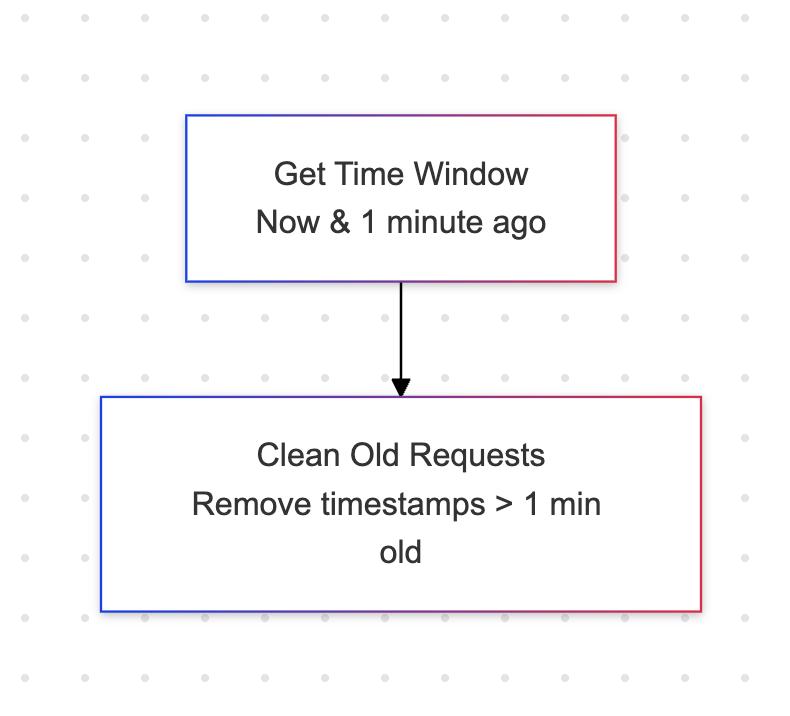
Deleting old requests
Check request count