Metriken für Sprachaufgaben: ROUGE, METEOR, EM
Einführung in LLMs mit Python

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
LLM-Aufgaben und Metriken
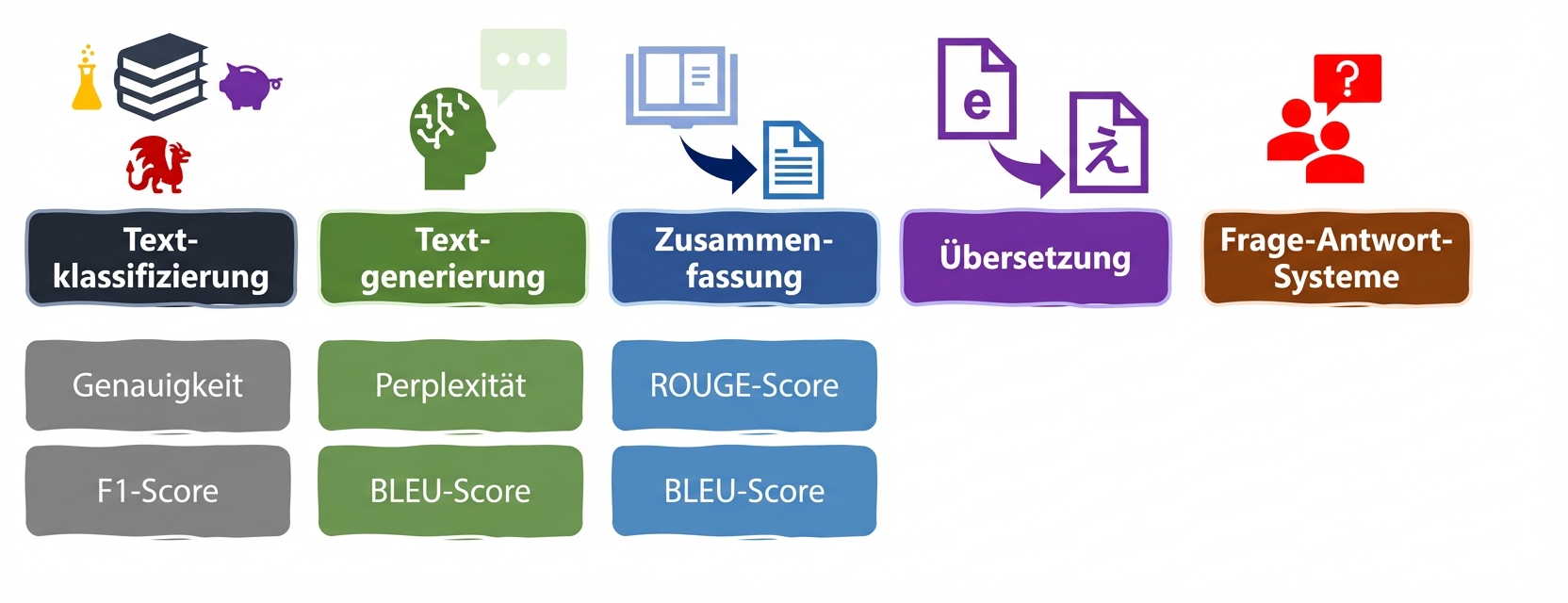
LLM-Aufgaben und Metriken
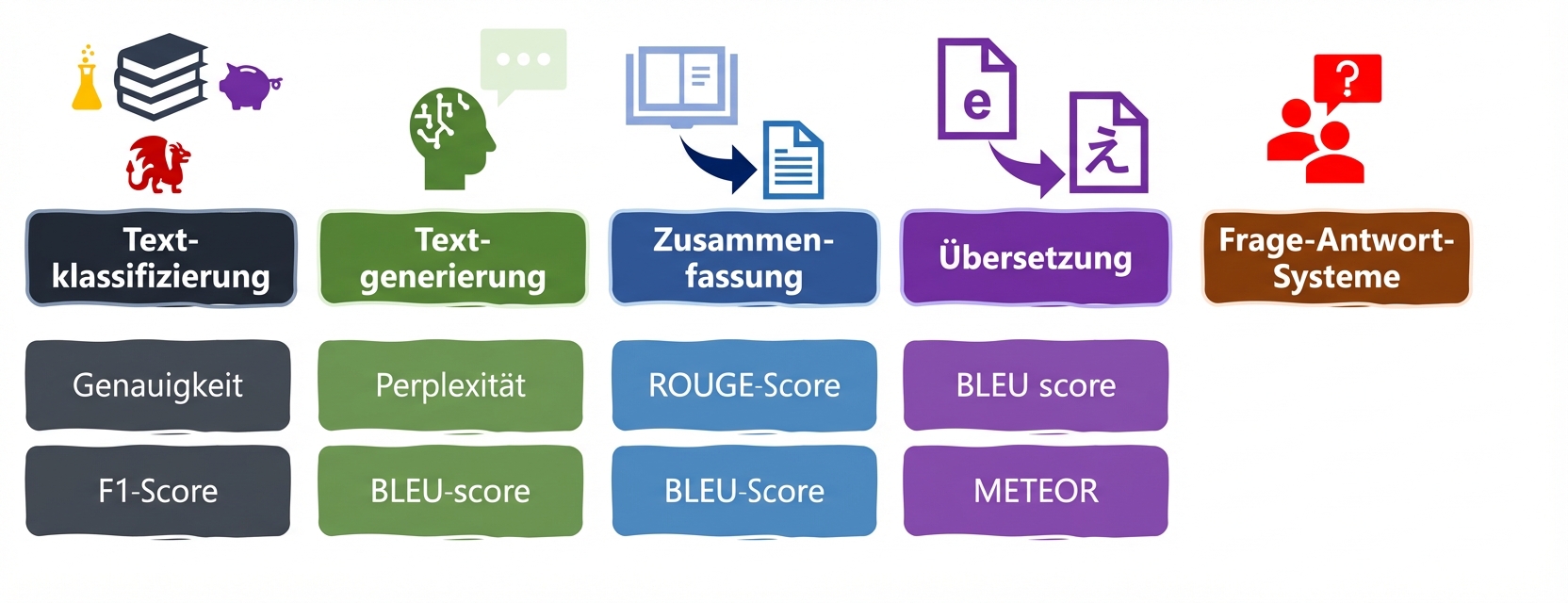
LLM-Aufgaben und Metriken
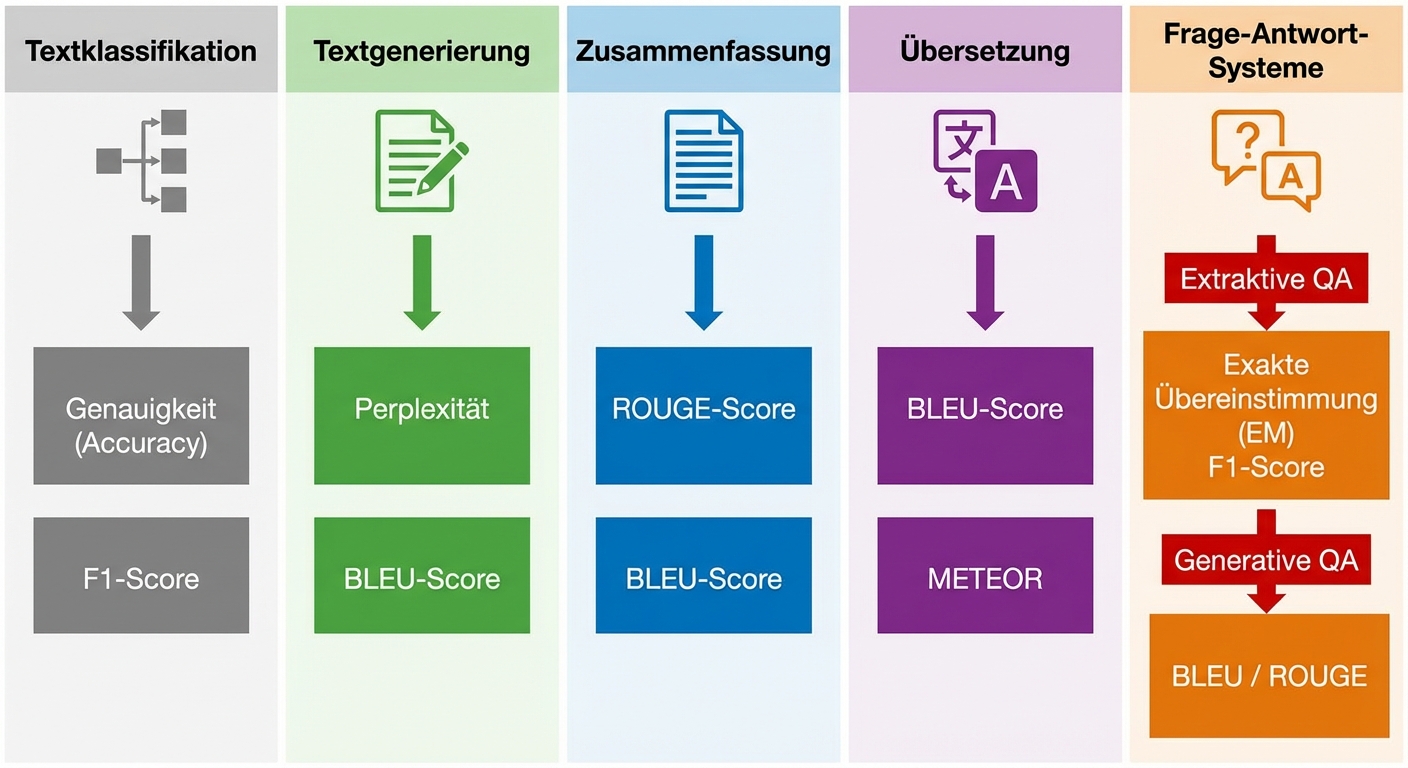
ROUGE
- ROUGE: Wie ähnlich ist die zusammengefasste Version den auf Referenztexten basierenden Zusammenfassungen?
- Schaut sich n-Gramme und Überschneidungen an
predictions:LLM-Ausgabenreferences: von Menschen erstellte Zusammenfassungen

Antwortgenerierung (Question answering)

