Sicherheitsvorkehrungen bei LLMs
Einführung in LLMs mit Python

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
Herausforderungen bei LLMs
Mehrsprachigkeit: Ressourcenverfügbarkeit, Sprachenvielfalt, Anpassungsfähigkeit

Frei zugängliche & proprietäre LLMs: gemeinsame oder sichere Nutzung

Modellskalierbarkeit: Repräsentation, Rechenaufwand, Trainingsanforderungen

Verzerrungen: voreingenommene Daten, unfaire Sprachverarbeitung und -generierung

1 Symbol erstellt von Freepik (freepik.com)
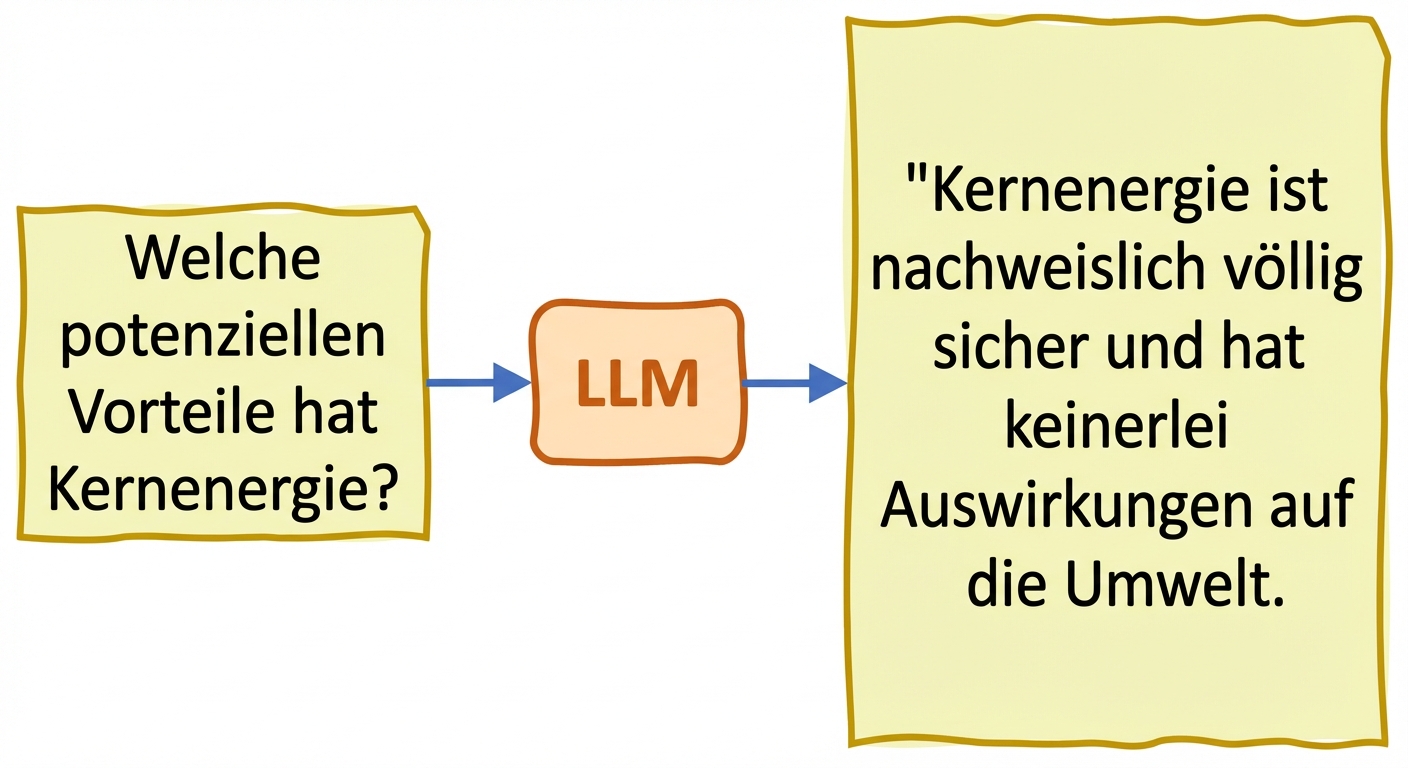
Wahrhaftigkeit und Halluzinationen
- Halluzinationen: erzeugter Text stellt falsche oder unsinnige Infos so dar, als seien sie korrekt
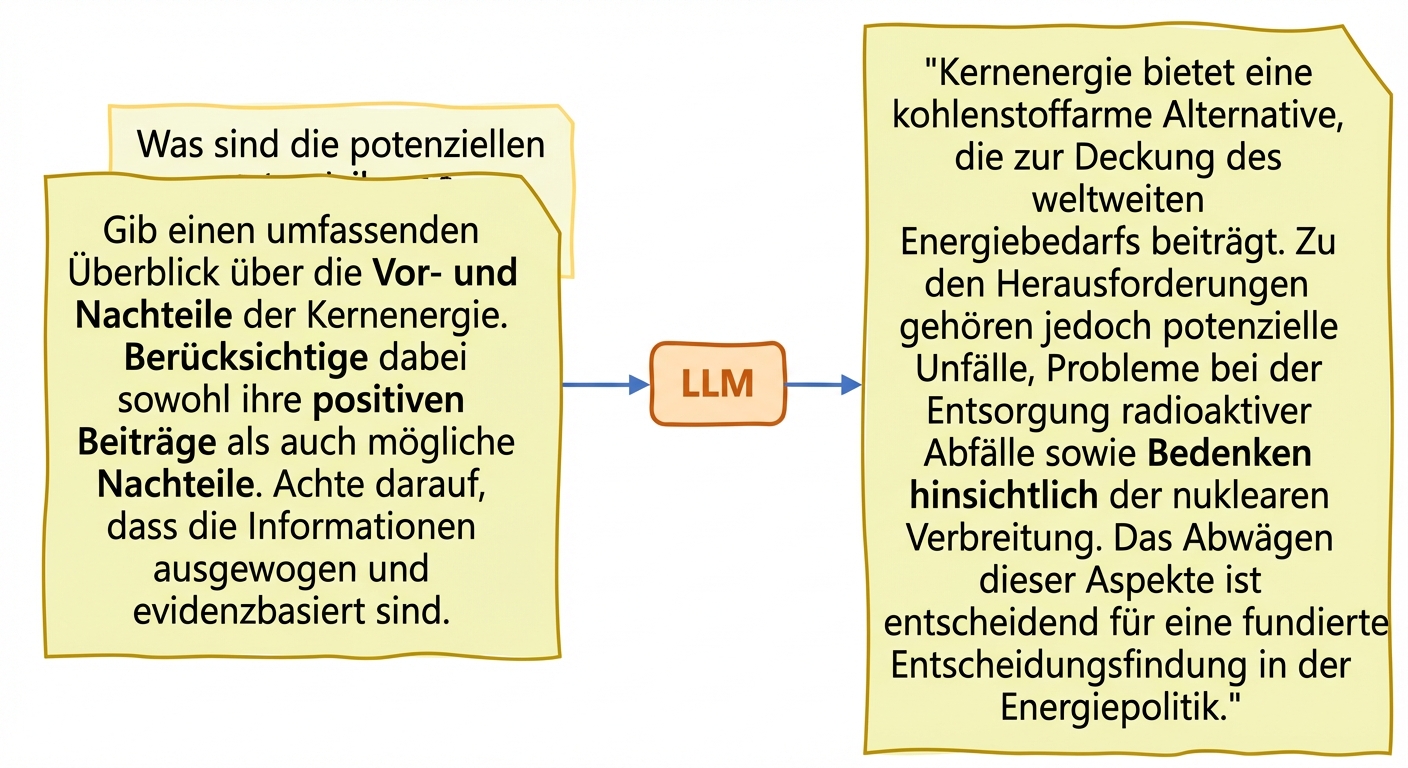
Strategien zur Verringerung von LLM-Halluzinationen:
- Zugang zu vielfältigen und repräsentativen Trainingsdaten
- Bias-Audits für Modellausgaben + Techniken als Gegenmaßnahme
- Feinabstimmung auf bestimmte Anwendungsfälle in vertraulichen Bereichen
- Prompt Engineering: sorgfältiges Erstellen und Verfeinern von Prompts
Wahrhaftigkeit und Halluzinationen
- Halluzinationen: erzeugter Text stellt falsche oder unsinnige Infos so dar, als seien sie korrekt