Vorbereitung für die Feinabstimmung
Einführung in LLMs mit Python

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
Pipelines und Auto-Klassen
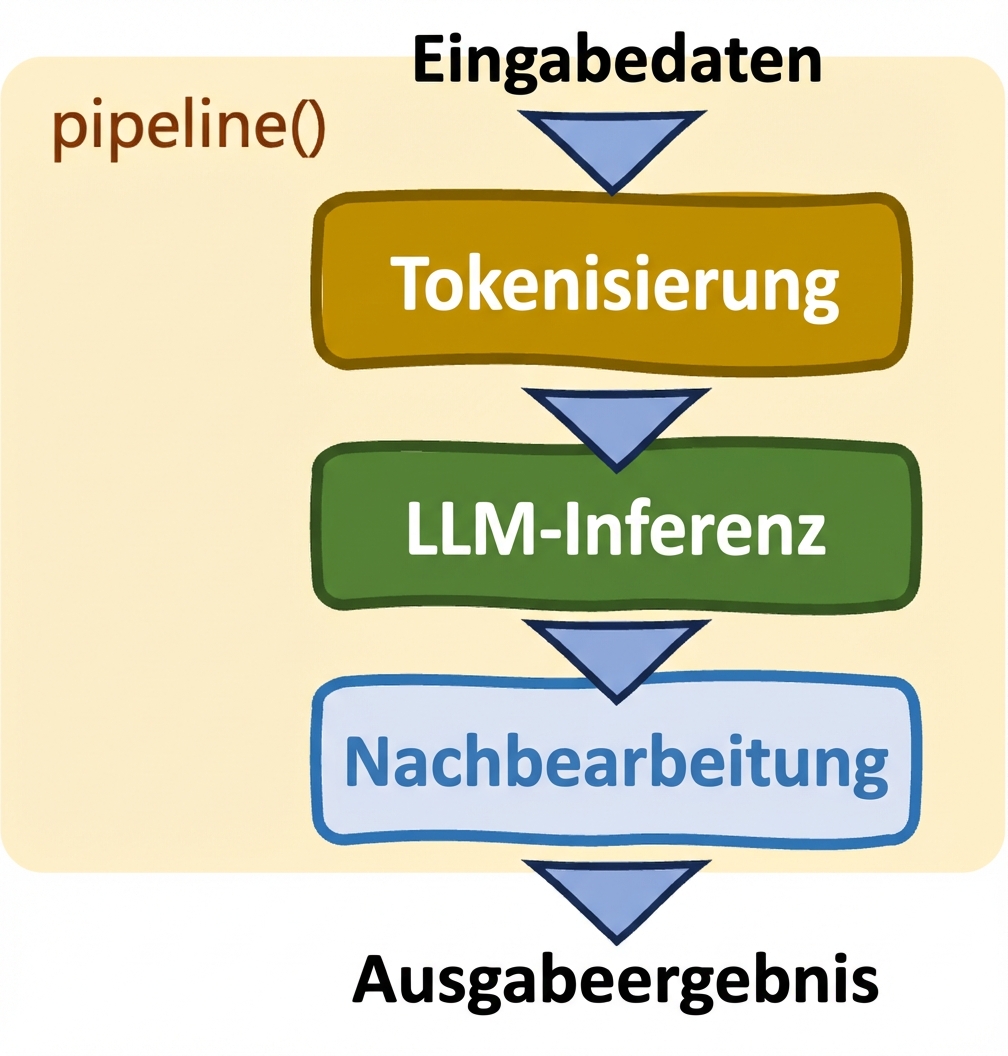
Pipelines: pipeline()
- Optimiert Aufgaben
- Automatische Auswahl von Modell und Tokenizer
- Eingeschränkte Kontrolle
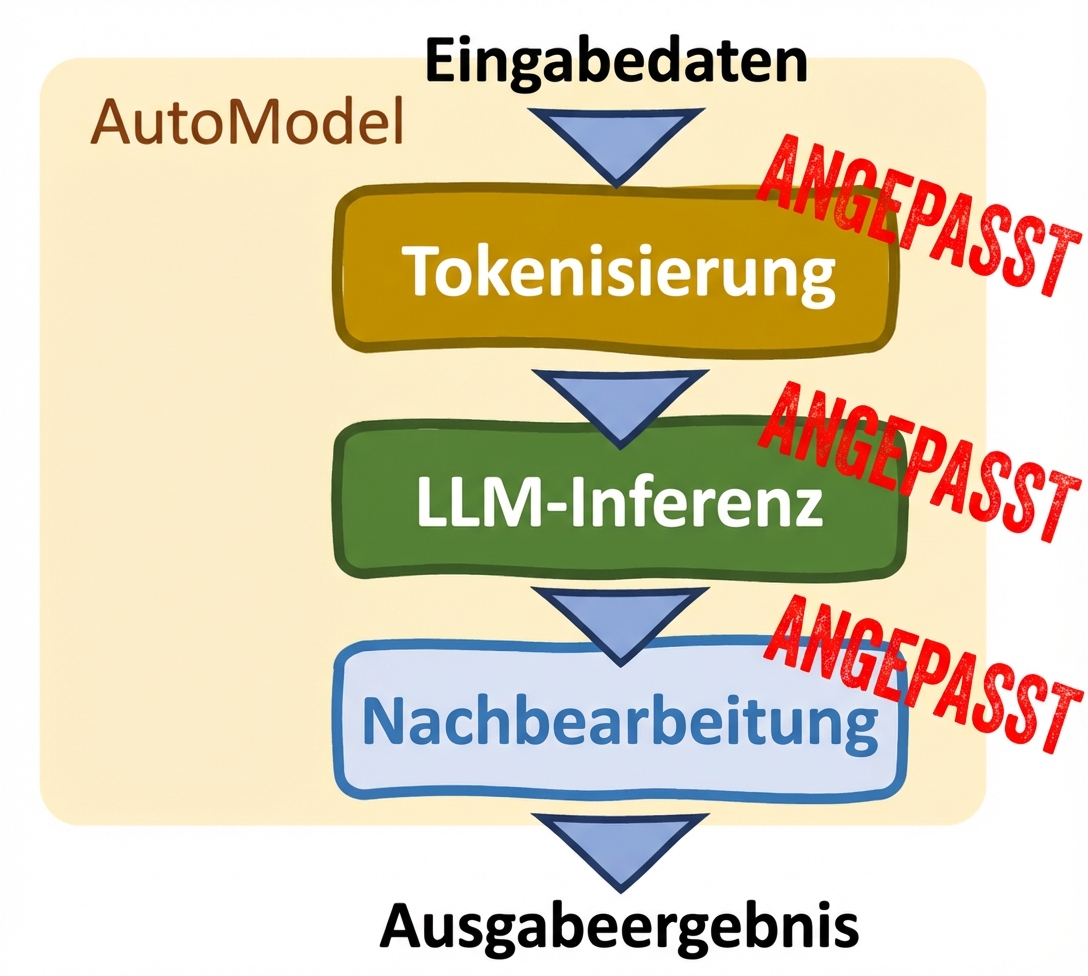
Auto-Klassen: (AutoModel-Klasse)
- Individualisierung
- Manuelle Anpassungen
- Unterstützt Feinabstimmung
LLM-Lebenszyklus
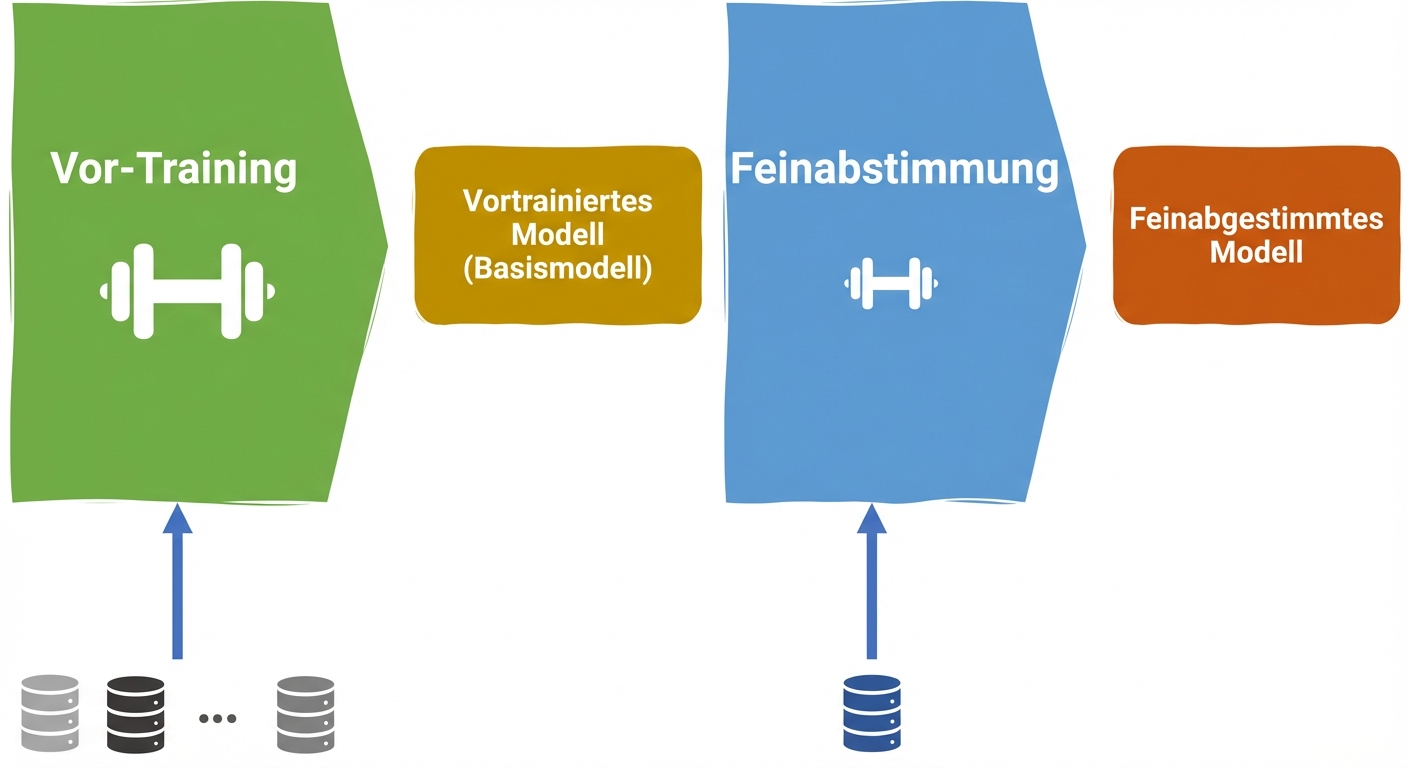
LLM-Lebenszyklus
Subword-Tokenisierung
- Bei modernen Tokenizern üblich
- Wörter in sinnvolle Teile zerlegt

Subword-Tokenisierung
- Bei modernen Tokenizern üblich
- Wörter in sinnvolle Teile zerlegt


