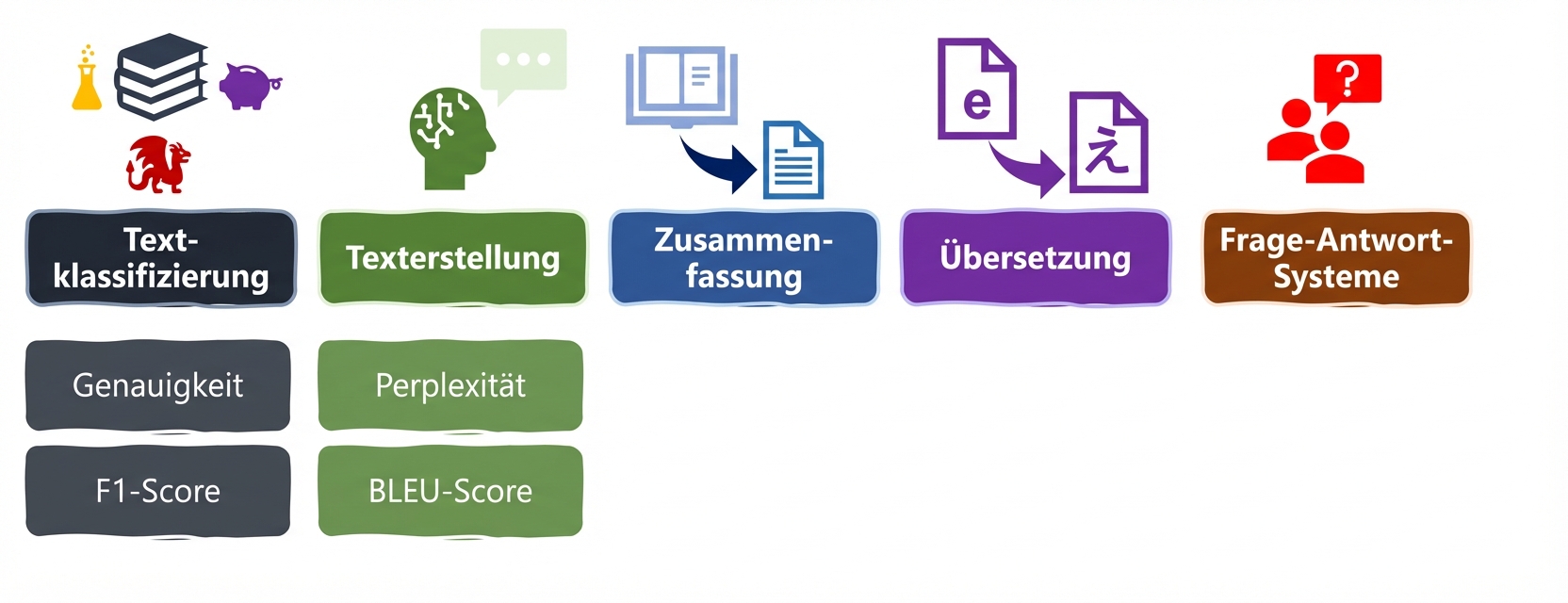
Metriken für Sprachaufgaben: Perplexity und BLEU
Einführung in LLMs mit Python

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
LLM-Aufgaben und Metriken
Einführung in LLMs mit Python
Jasmin Ludolf
Senior Data Science Content Developer, DataCamp

