Indicateurs pour les tâches linguistiques : ROUGE, METEOR, EM
Introduction aux LLM en Python

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
Tâches et indicateurs LLM
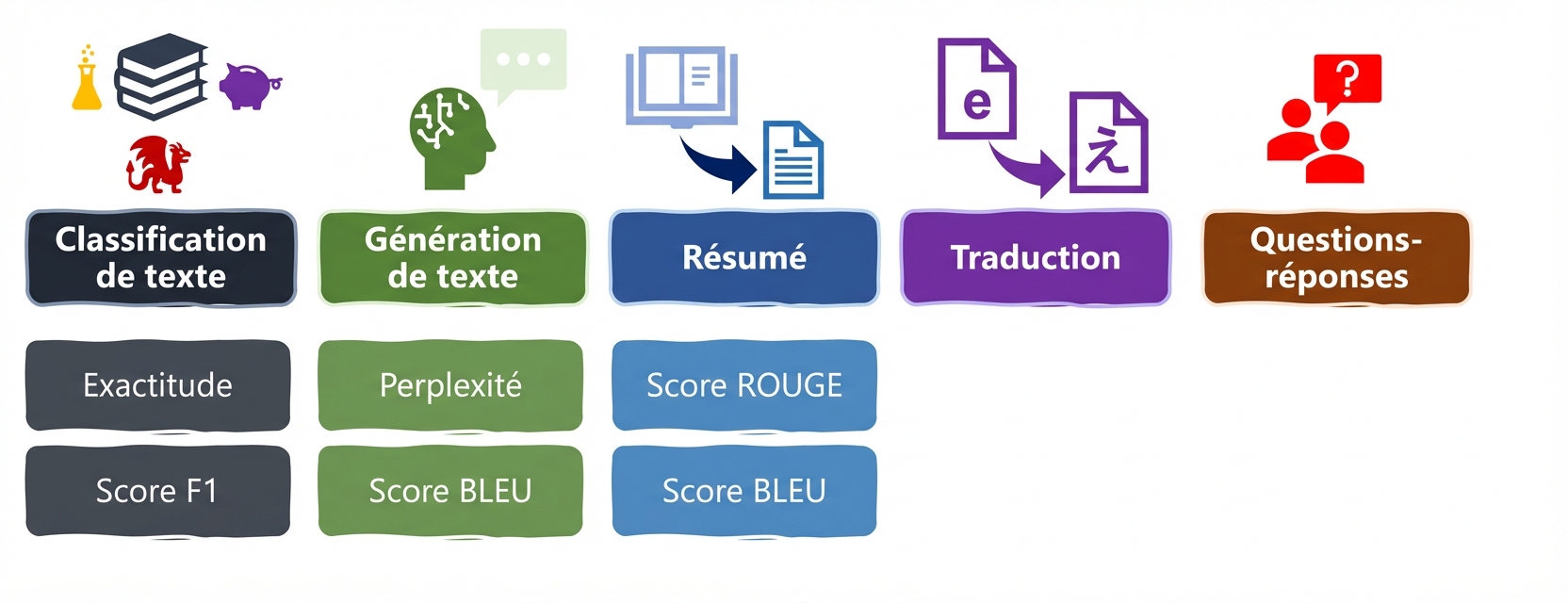
Tâches et indicateurs LLM
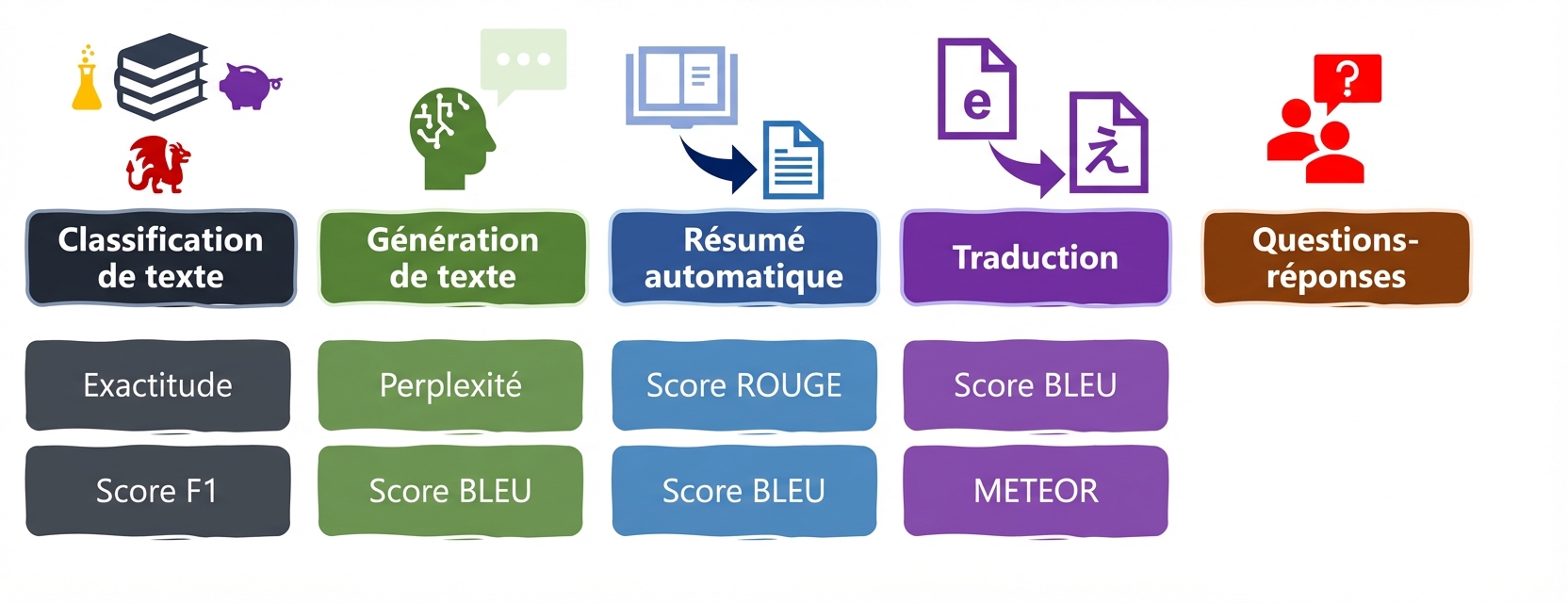
Tâches et indicateurs LLM
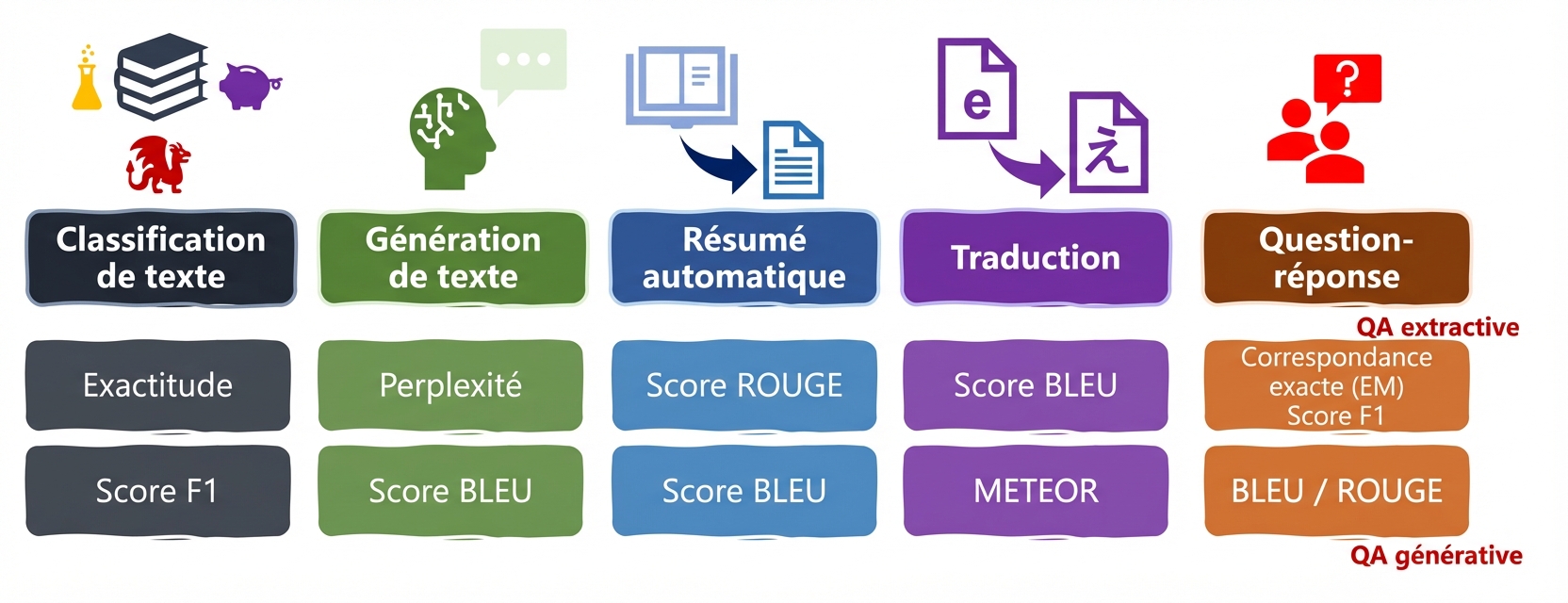
ROUGE
- ROUGE : similitude entre le résumé généré et les résumés de référence
- Analyse les n-grammes et les chevauchements
predictions:résultats du LLMreferences: résumés fournis par des personnes

Questions et réponses

