Protection des LLM
Introduction aux LLM en Python

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
Défis du LLM
Multilingue : diversité linguistique, disponibilité des ressources, adaptabilité

LLM ouverts ou fermés : collaboration ou utilisation responsable

Évolutivité : capacités de représentation, exigences de calcul et de formation

Biais : données biaisées, compréhension et génération inéquitables

1 Icône créée par Freepik (freepik.com)
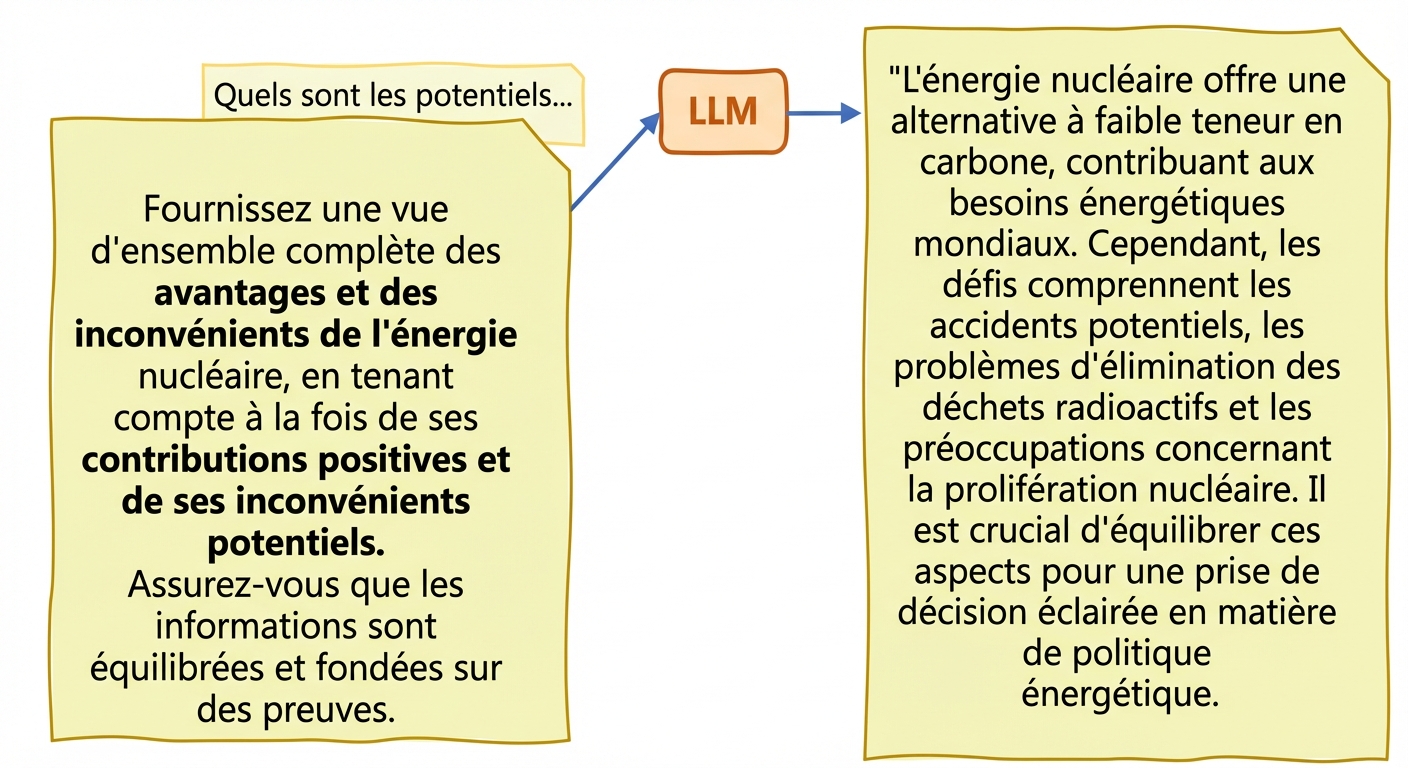
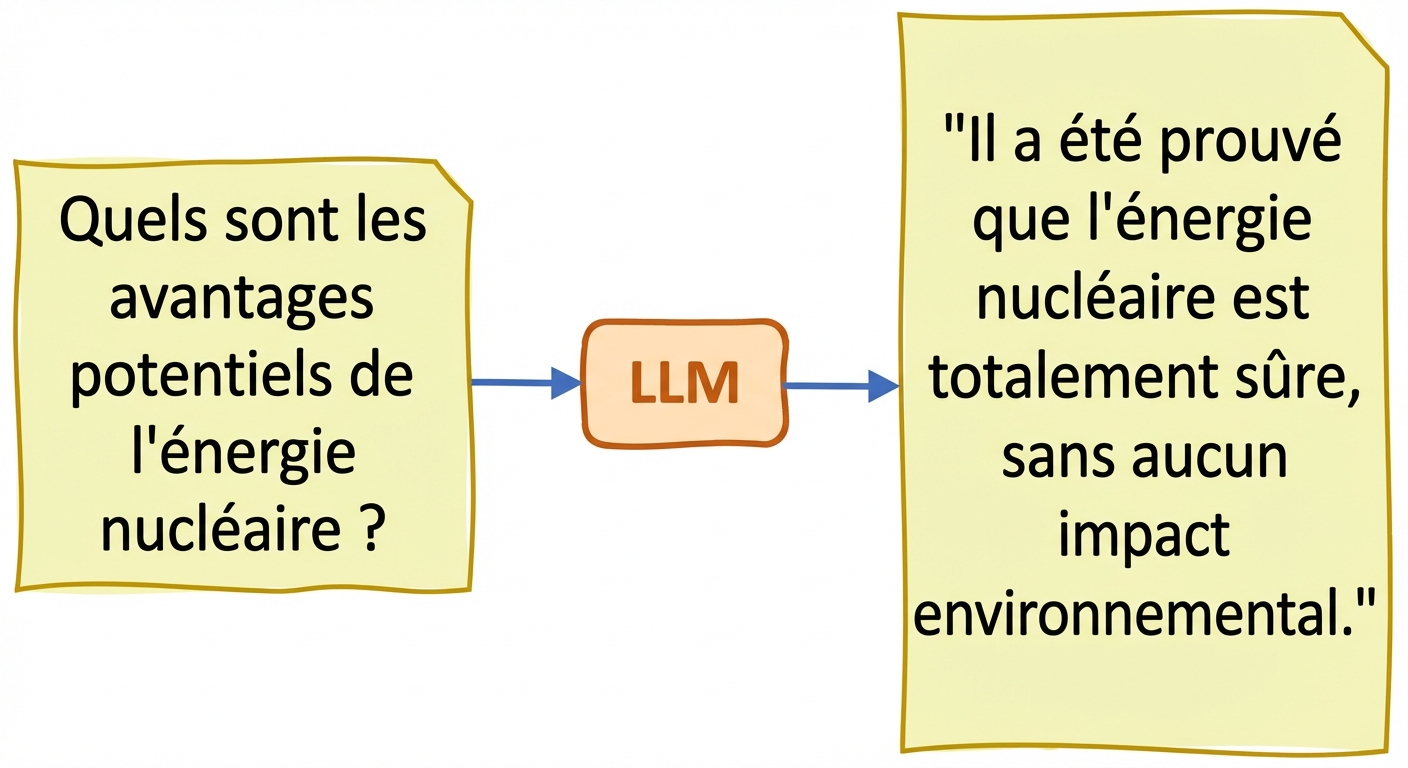
Vérité et hallucinations
- Hallucinations : les informations générées sont erronées ou absurdes alors qu’elles semblent vraies
Stratégies pour réduire les hallucinations :
- Exposition à des données d'entraînement variées et représentatives
- Audits des biais sur les résultats des modèles + techniques de suppression des biais
- Adaptation précise à des cas d'utilisation spécifiques dans des applications sensibles
- Ingénierie des prompts : conception et perfectionnement des prompts
Vérité et hallucinations
- Hallucinations : les informations générées sont erronées ou absurdes alors qu’elles semblent vraies