Préparation pour l’affinage
Introduction aux LLM en Python

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
Pipelines et classes automatiques
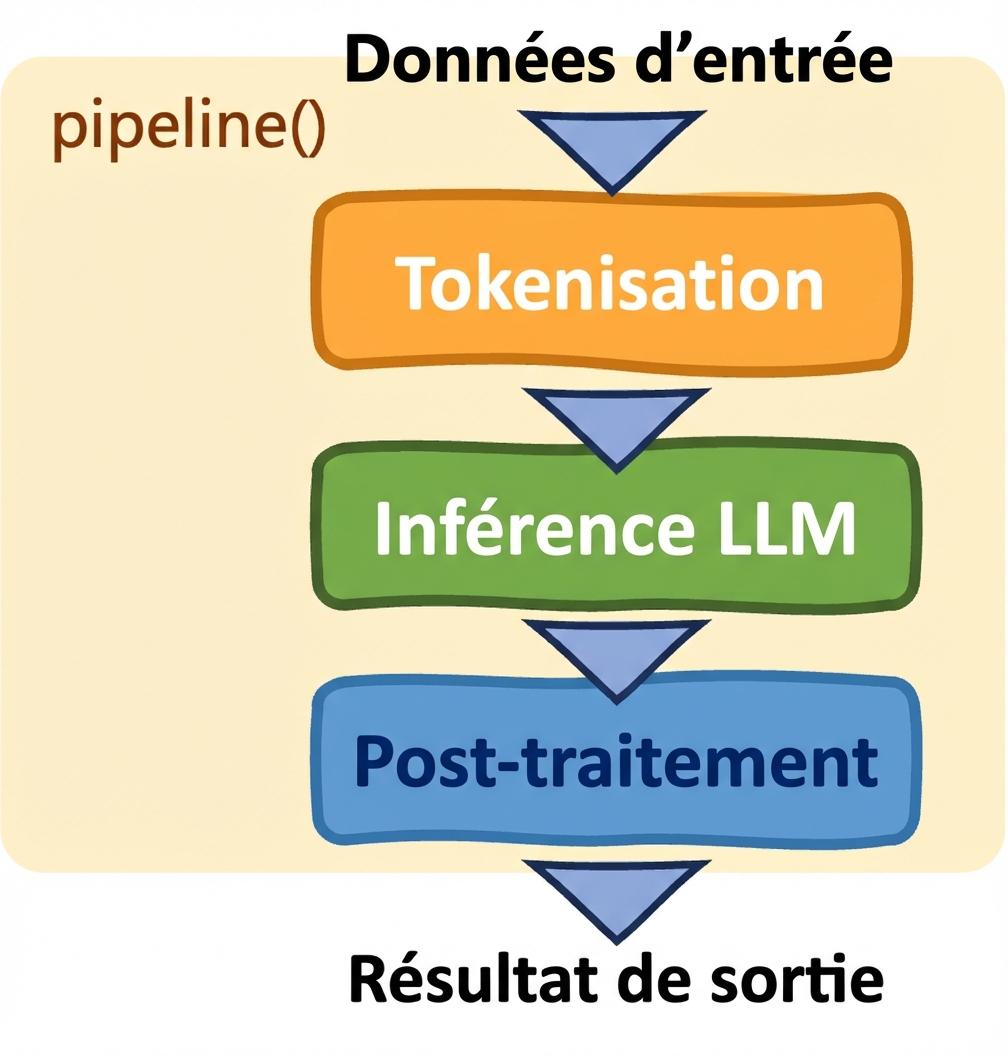
Pipelines : pipeline()
- Simplifie les tâches
- Sélection automatique du modèle et du tokenizer
- Contrôle restreint
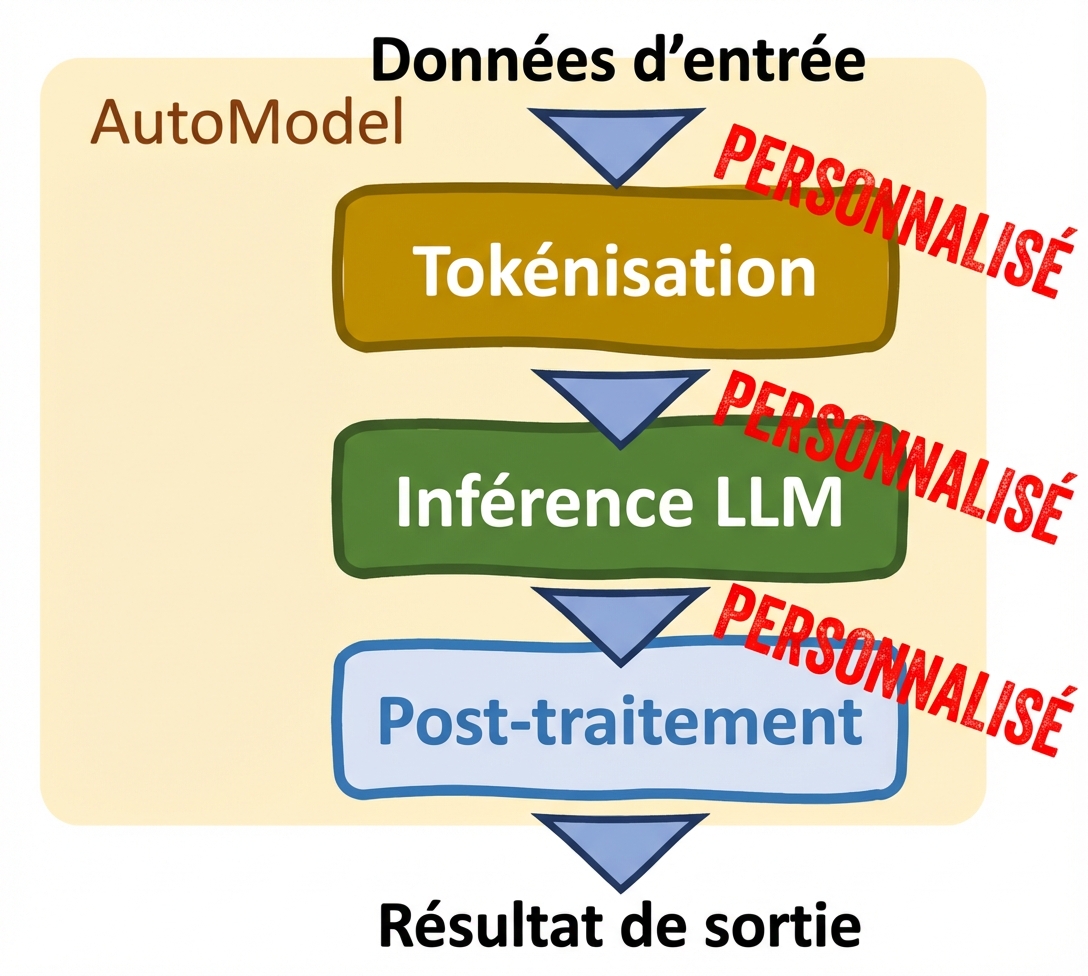
Classes automatiques ( classeAutoModel )
- Personnalisation
- Réglages manuels
- Prend en charge l’affinage
Cycle de vie LLM
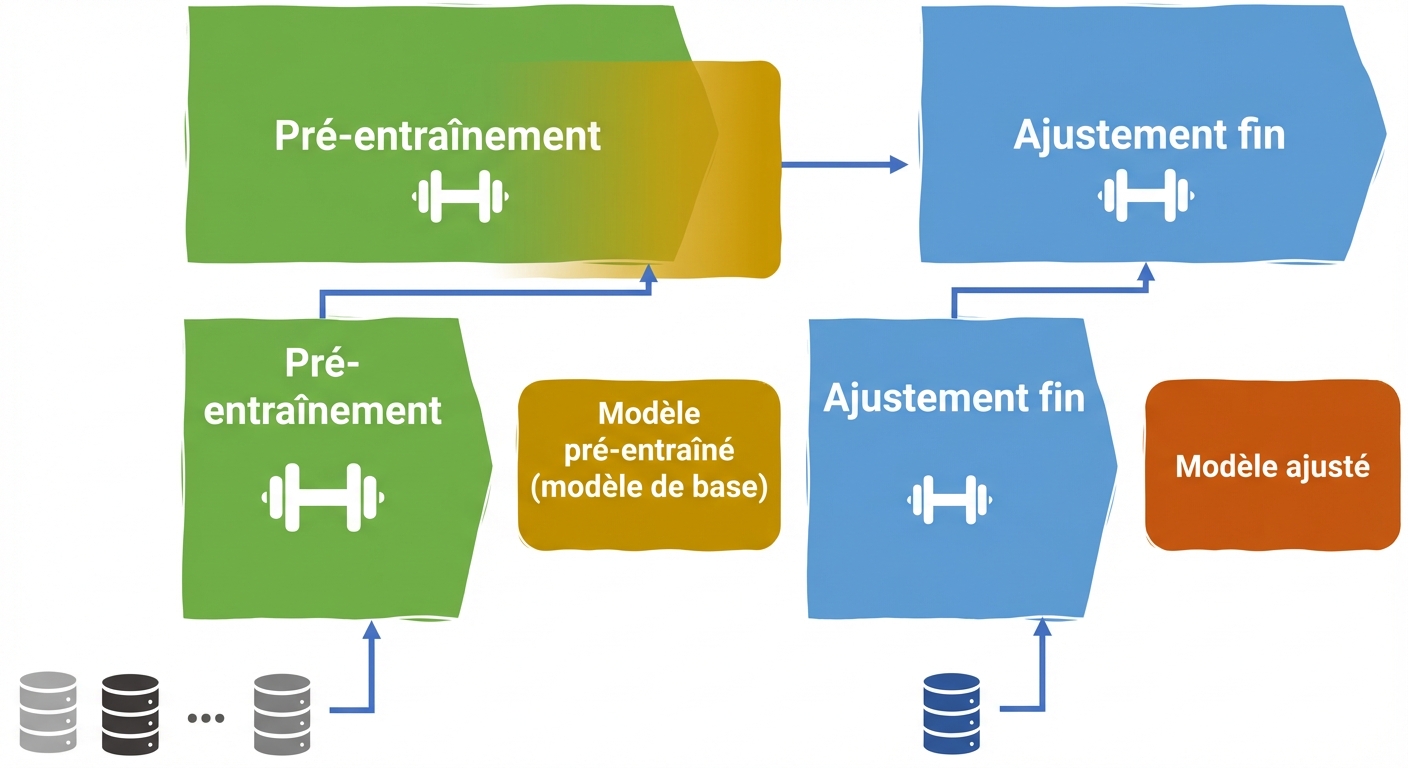
Cycle de vie LLM
Tokenisation des sous-mots
- Courant dans les tokenizers modernes
- Mots divisés en sous-parties significatives

Tokenisation des sous-mots
- Courant dans les tokenizers modernes
- Mots divisés en sous-parties significatives


