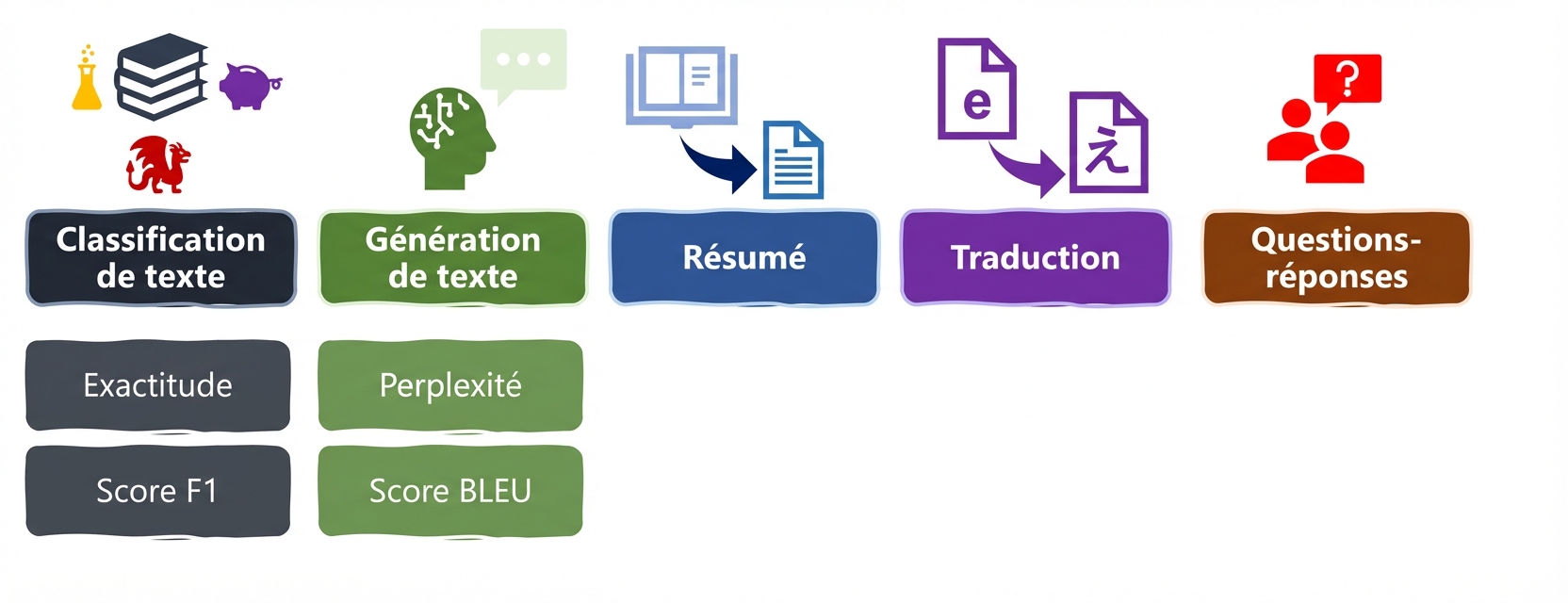
Mesures pour les tâches linguistiques : perplexité et BLEU
Introduction aux LLM en Python

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
Tâches et indicateurs LLM
Introduction aux LLM en Python
Jasmin Ludolf
Senior Data Science Content Developer, DataCamp

