Il teorema del limite centrale
Introduzione alla statistica in R

Maggie Matsui
Content Developer, DataCamp
Lanciare il dado 5 volte

Distribuzioni campionarie
Distribuzione campionaria della media campionaria
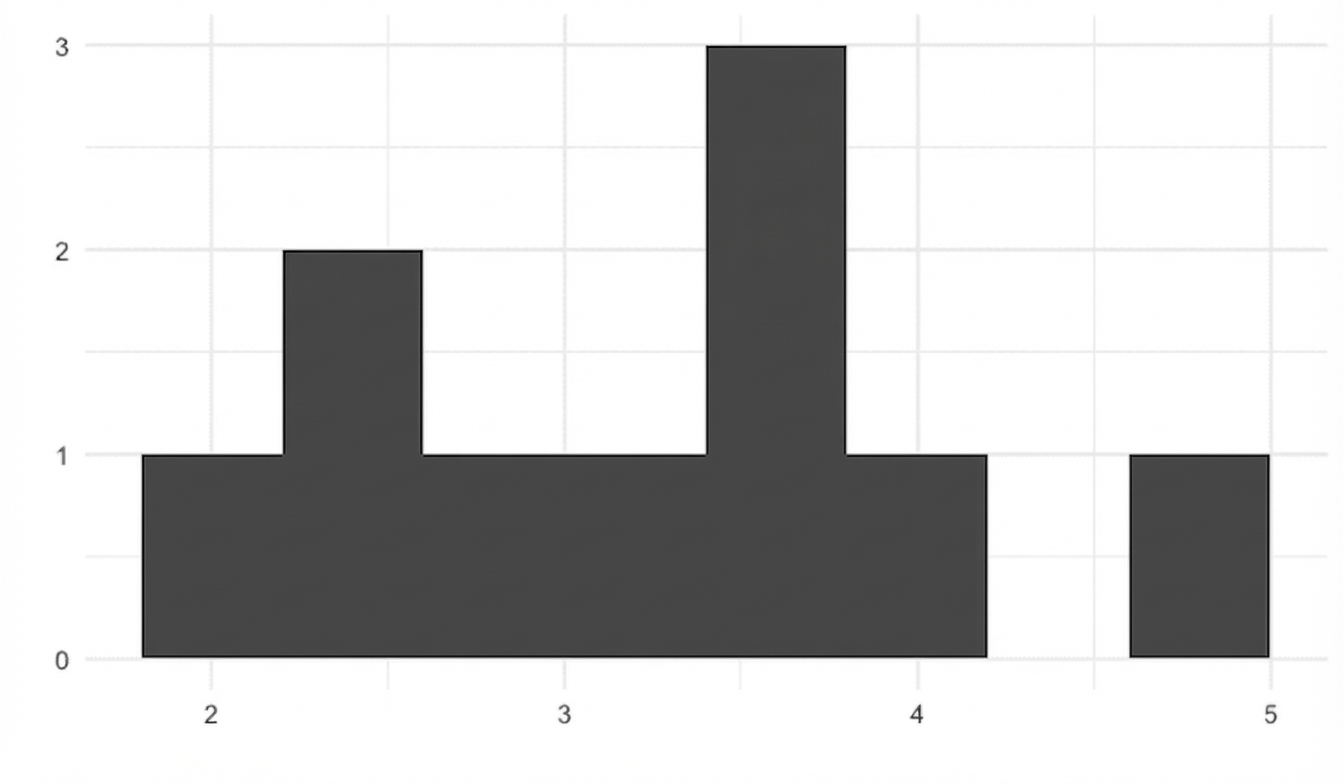
100 medie campionarie
replicate(100, sample(die, 5, replace = TRUE) %>% mean())
2.8 3.2 1.8 4.6 4.0 2.8 4.4 2.4 3.4 2.8 4.2 3.4 ... 2.2 3.8 3.6 3.8 4.4 4.8 2.4
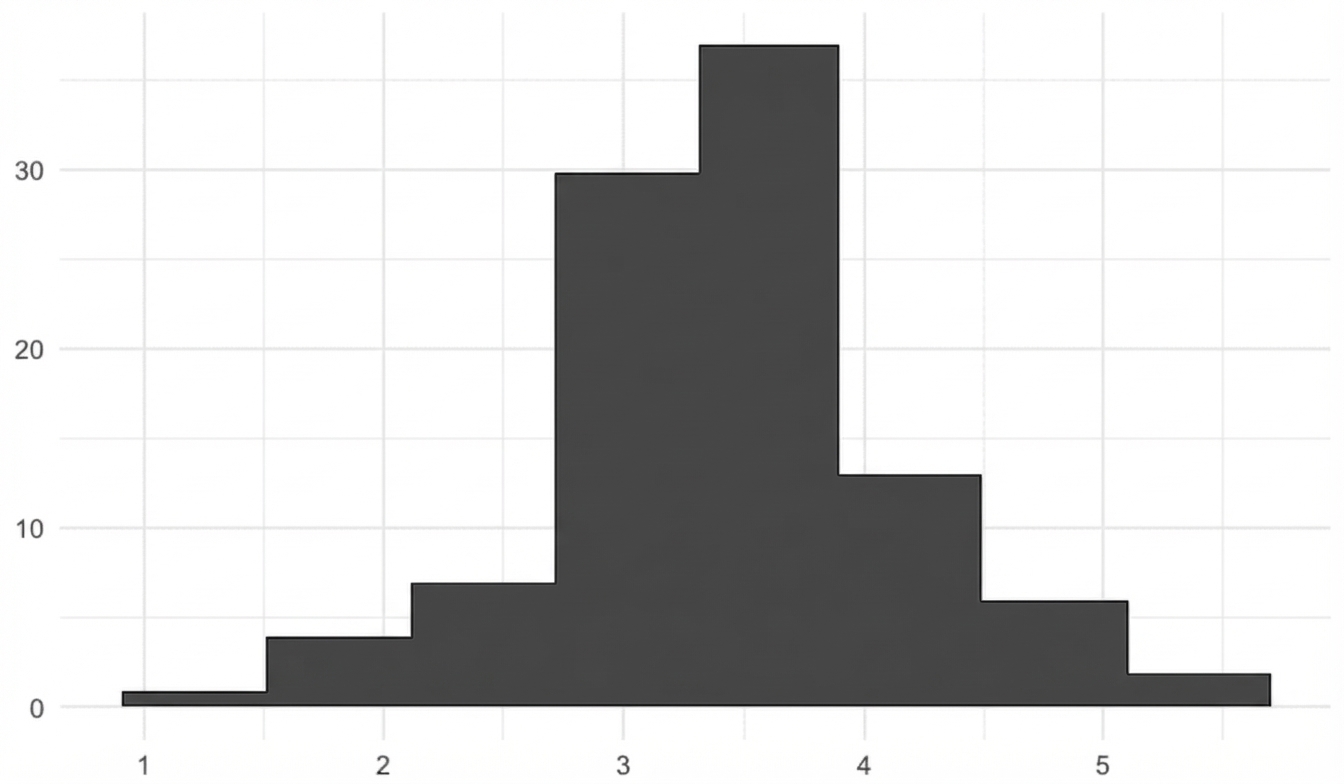
1000 medie campionarie
sample_means <- replicate(1000, sample(die, 5, replace = TRUE) %>% mean())
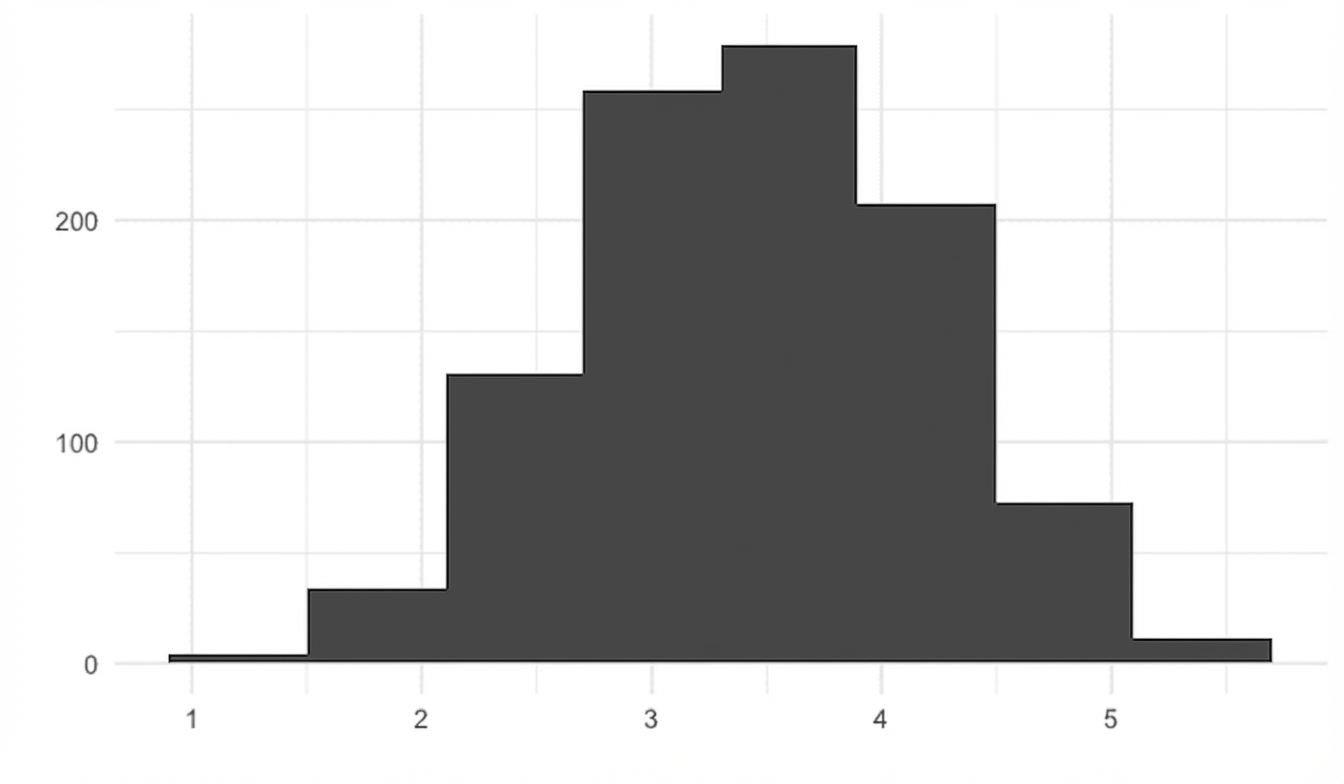
Teorema del limite centrale
La distribuzione campionaria di una statistica si avvicina a quella normale al crescere del numero di prove.
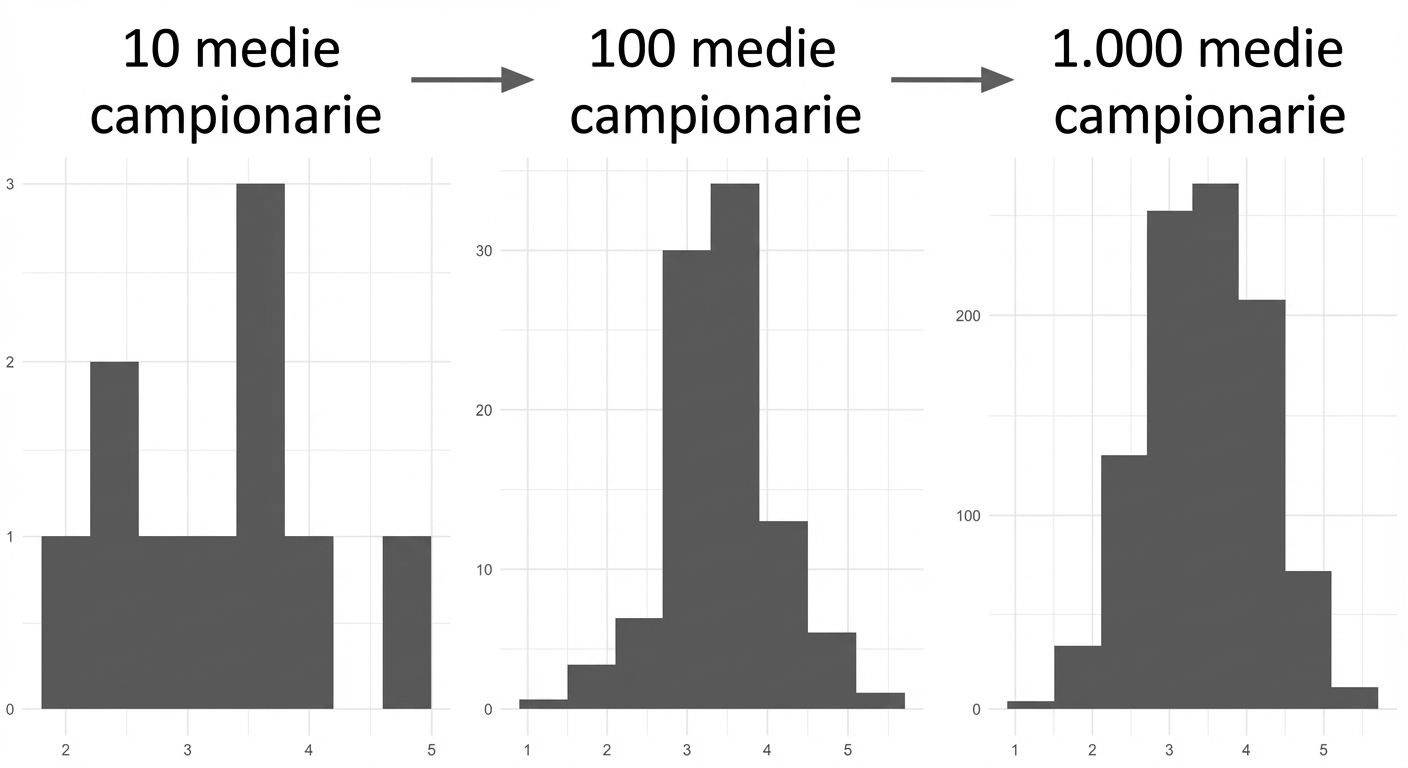
* I campioni devono essere casuali e indipendenti
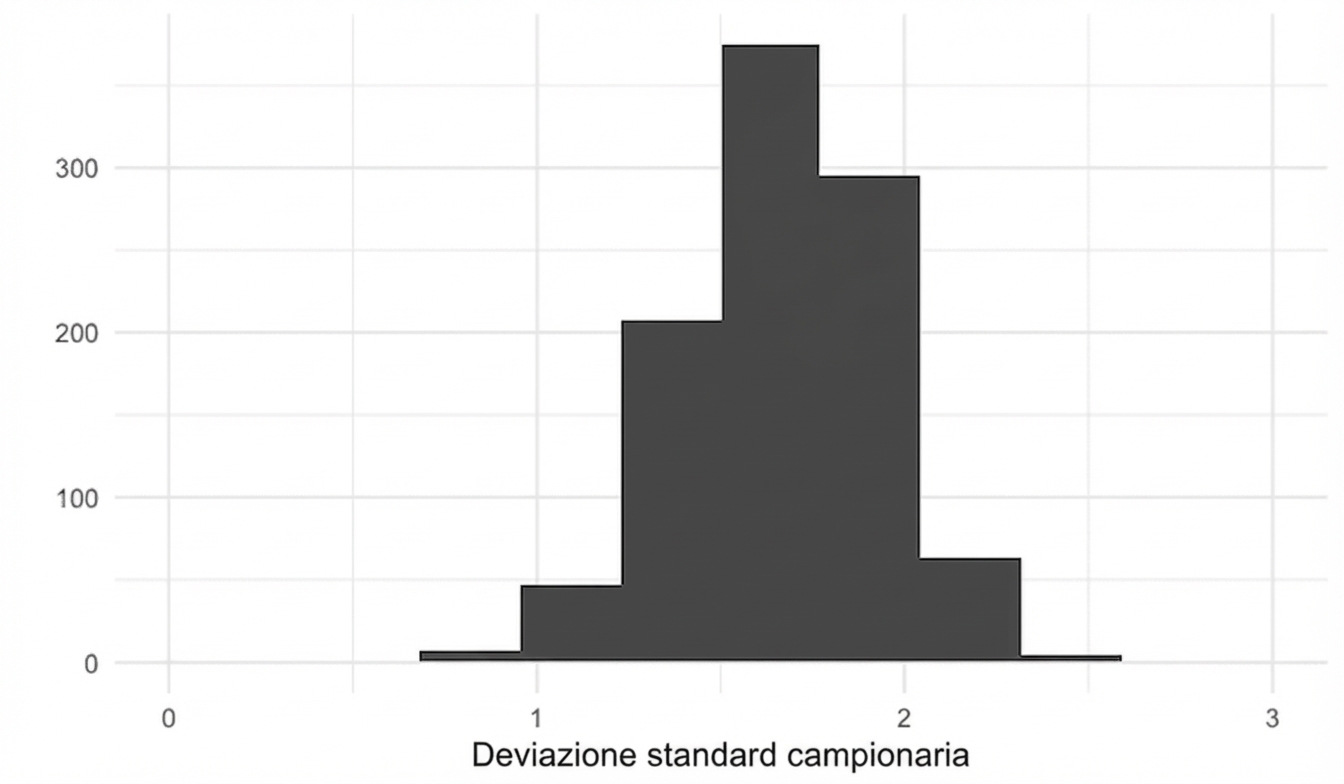
Deviazione standard e TLC
replicate(1000, sample(die, 5, replace = TRUE) %>% sd())
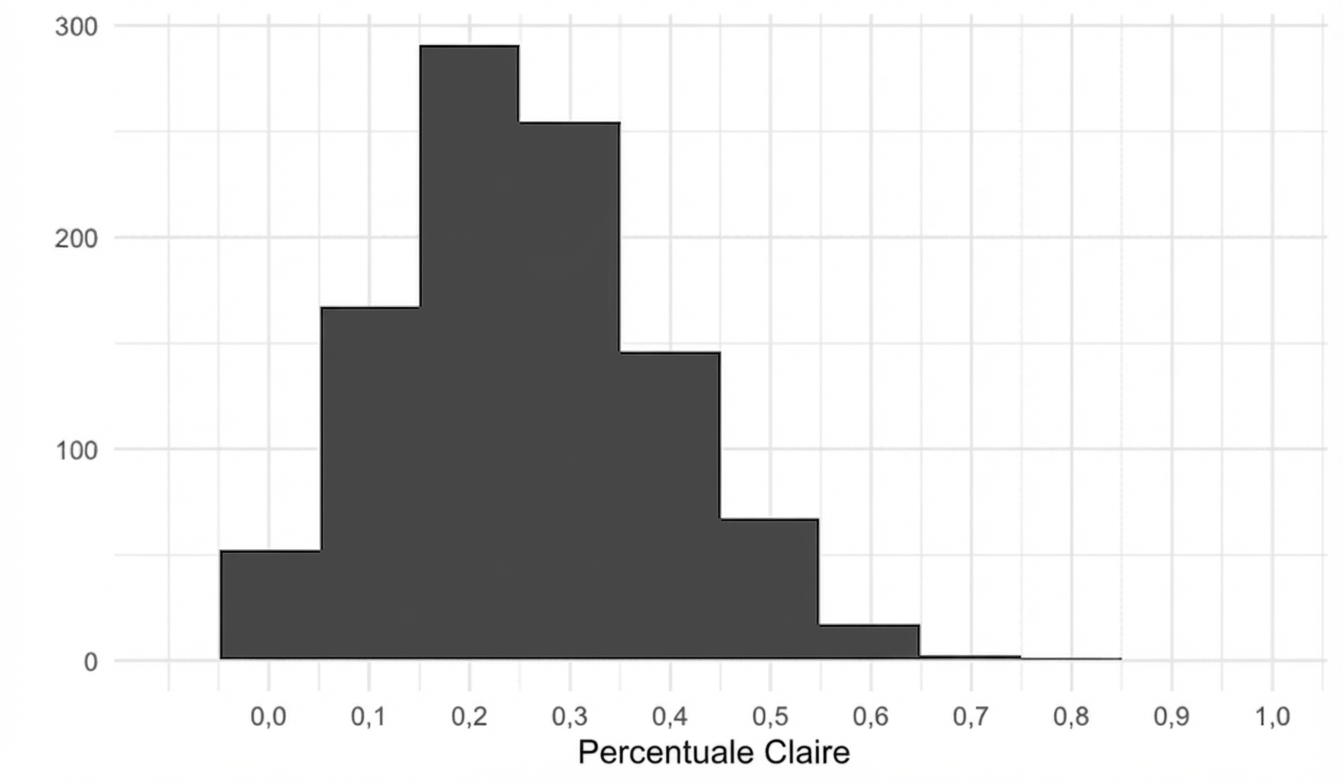
Distribuzione campionaria della proporzione
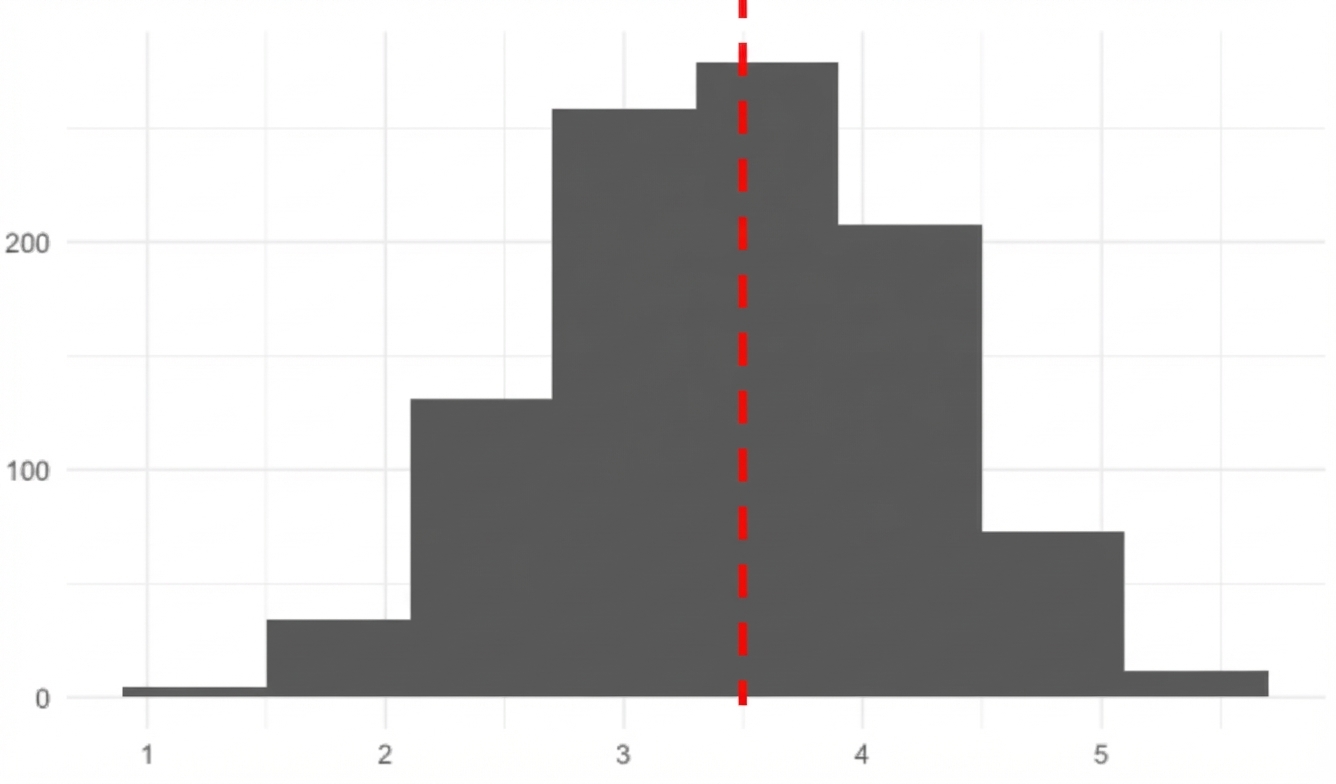
Media della distribuzione campionaria
- Stimare più facilmente caratteristiche di grandi popolazioni

