Grundlagen von Big Data mit PySpark
Upendra Devisetty
Science Analyst, CyVerse
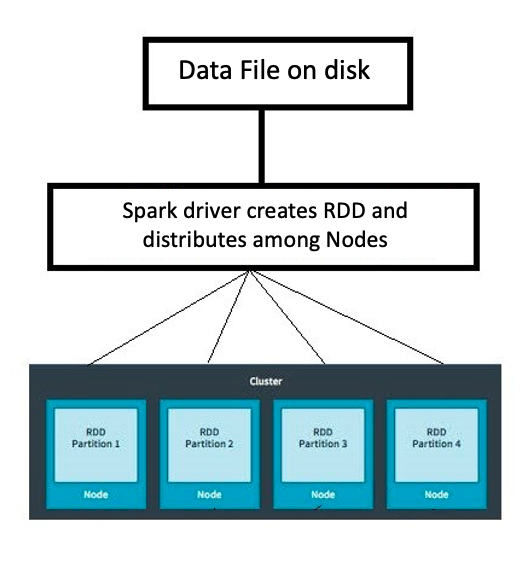
Resilient Distributed Datasets
Resilient: Ausfalltolerant
Distributed: Über mehrere Maschinen verteilt
Datasets: Sammlung partitionierter Daten, z. B. Arrays, Tabellen, Tupel usw.
Parallelisieren einer vorhandenen Objektsammlung
Externe Datasets:
Dateien in HDFS
Objekte in einem Amazon-S3-Bucket
Zeilen in einer Textdatei
Aus bestehenden RDDs
parallelize()
numRDD = sc.parallelize([1,2,3,4])
helloRDD = sc.parallelize("Hello world")
type(helloRDD)
<class 'pyspark.rdd.PipelinedRDD'>
textFile()
fileRDD = sc.textFile("README.md")
type(fileRDD)
Eine Partition ist eine logische Teilung eines großen verteilten Datasets
Methode parallelize()
numRDD = sc.parallelize(range(10), minPartitions = 6)
fileRDD = sc.textFile("README.md", minPartitions = 6)
getNumPartitions()