Einführung in Clustering
Grundlagen von Big Data mit PySpark

Upendra Devisetty
Science Analyst, CyVerse
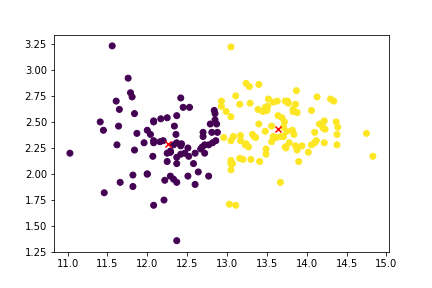
K-means-Clustering
- K-means ist die populärste Clustering-Methode
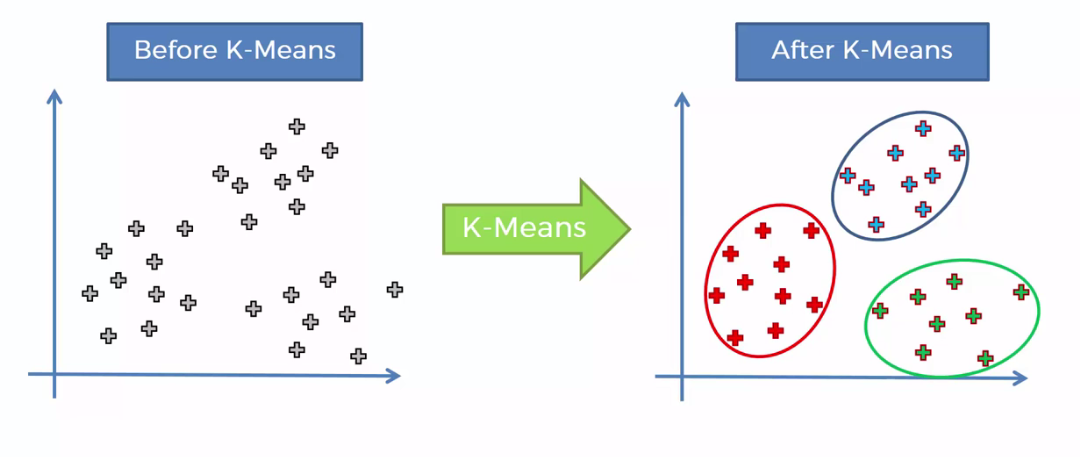
K-means-Cluster visualisieren
Grundlagen von Big Data mit PySpark
Upendra Devisetty
Science Analyst, CyVerse

