RDD-Operationen in PySpark
Grundlagen von Big Data mit PySpark

Upendra Devisetty
Science Analyst, CyVerse
Überblick: PySpark-Operationen

- Transformationen erzeugen neue RDDs
- Aktionen berechnen Ergebnisse auf RDDs
RDD-Transformationen
- Transformationen sind Lazy evaluated

Grundlegende RDD-Transformationen
map(),filter(),flatMap()undunion()
map()-Transformation
- Die map()-Transformation wendet eine Funktion auf alle RDD-Elemente an
![]()
RDD = sc.parallelize([1,2,3,4])
RDD_map = RDD.map(lambda x: x * x)
filter()-Transformation
- Die filter-Transformation gibt ein neues RDD nur mit Elementen zurück, die die Bedingung erfüllen

RDD = sc.parallelize([1,2,3,4])
RDD_filter = RDD.filter(lambda x: x > 2)
flatMap()-Transformation
- Die flatMap()-Transformation liefert mehrere Werte pro Element im ursprünglichen RDD
![]()
RDD = sc.parallelize(["hello world", "how are you"])
RDD_flatmap = RDD.flatMap(lambda x: x.split(" "))
union()-Transformation
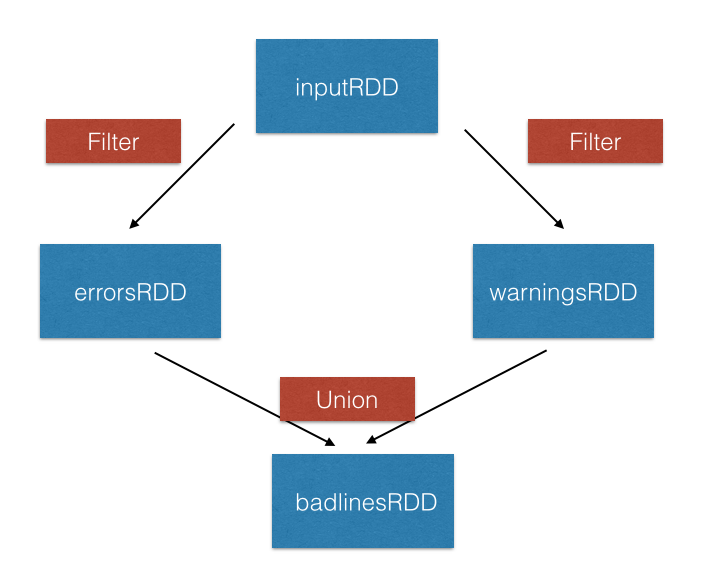
inputRDD = sc.textFile("logs.txt")
errorRDD = inputRDD.filter(lambda x: "error" in x.split())
warningsRDD = inputRDD.filter(lambda x: "warnings" in x.split())
combinedRDD = errorRDD.union(warningsRDD)

