Introduction aux RDD PySpark
Principes fondamentaux des mégadonnées avec PySpark

Upendra Devisetty
Science Analyst, CyVerse
Qu’est-ce qu’un RDD ?
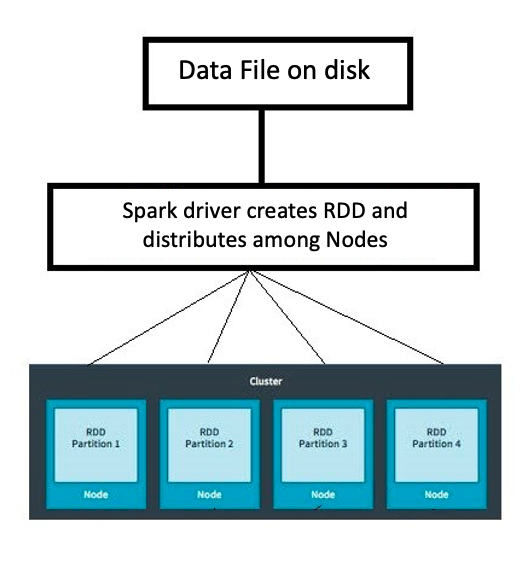
- RDD = Resilient Distributed Datasets
Principes fondamentaux des mégadonnées avec PySpark
Upendra Devisetty
Science Analyst, CyVerse

