Introduction au clustering
Principes fondamentaux des mégadonnées avec PySpark

Upendra Devisetty
Science Analyst, CyVerse
Clustering K-means
- K-means est la méthode de clustering la plus courante
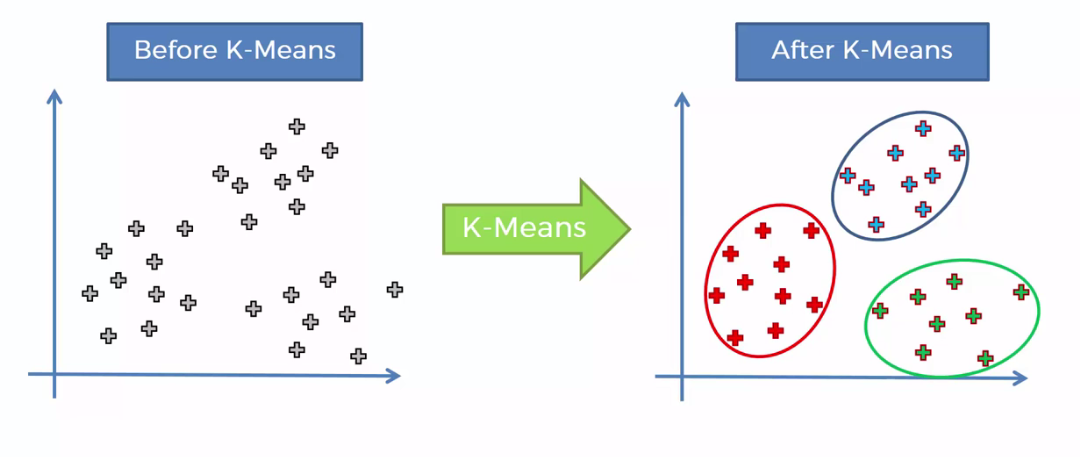
Visualiser les clusters K-means
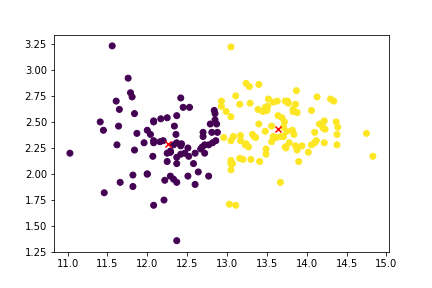
Principes fondamentaux des mégadonnées avec PySpark
Upendra Devisetty
Science Analyst, CyVerse

