Opérations RDD en PySpark
Principes fondamentaux des mégadonnées avec PySpark

Upendra Devisetty
Science Analyst, CyVerse
Aperçu des opérations PySpark

- Les transformations créent de nouveaux RDD
- Les actions exécutent des calculs sur les RDD
Transformations RDD
- Les transformations utilisent l’évaluation paresseuse (Lazy evaluation)

Transformations RDD de base
map(),filter(),flatMap(), etunion()
Transformation map()
- La transformation map() applique une fonction à tous les éléments du RDD
![]()
RDD = sc.parallelize([1,2,3,4])
RDD_map = RDD.map(lambda x: x * x)
Transformation filter()
- La transformation filter retourne un nouveau RDD avec seulement les éléments satisfaisant la condition

RDD = sc.parallelize([1,2,3,4])
RDD_filter = RDD.filter(lambda x: x > 2)
Transformation flatMap()
- La transformation flatMap() renvoie plusieurs valeurs pour chaque élément du RDD d’origine
![]()
RDD = sc.parallelize(["hello world", "how are you"])
RDD_flatmap = RDD.flatMap(lambda x: x.split(" "))
Transformation union()
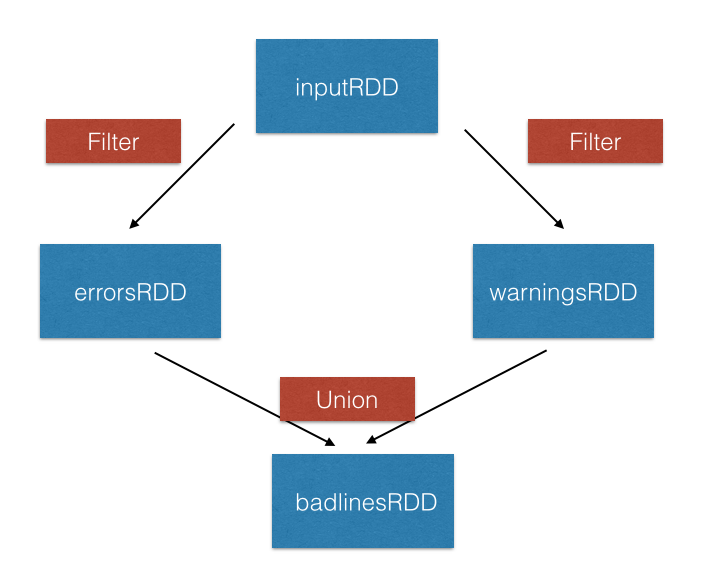
inputRDD = sc.textFile("logs.txt")
errorRDD = inputRDD.filter(lambda x: "error" in x.split())
warningsRDD = inputRDD.filter(lambda x: "warnings" in x.split())
combinedRDD = errorRDD.union(warningsRDD)

