Classification
Principes fondamentaux des mégadonnées avec PySpark

Upendra Devisetty
Science Analyst, CyVerse
Classification avec PySpark MLlib
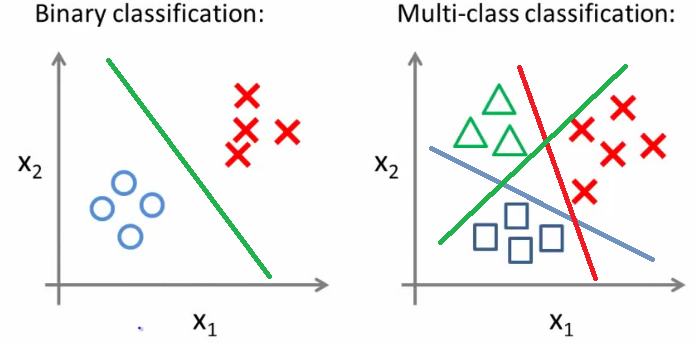
- La classification est un apprentissage supervisé qui classe les données en catégories
Introduction à la régression logistique
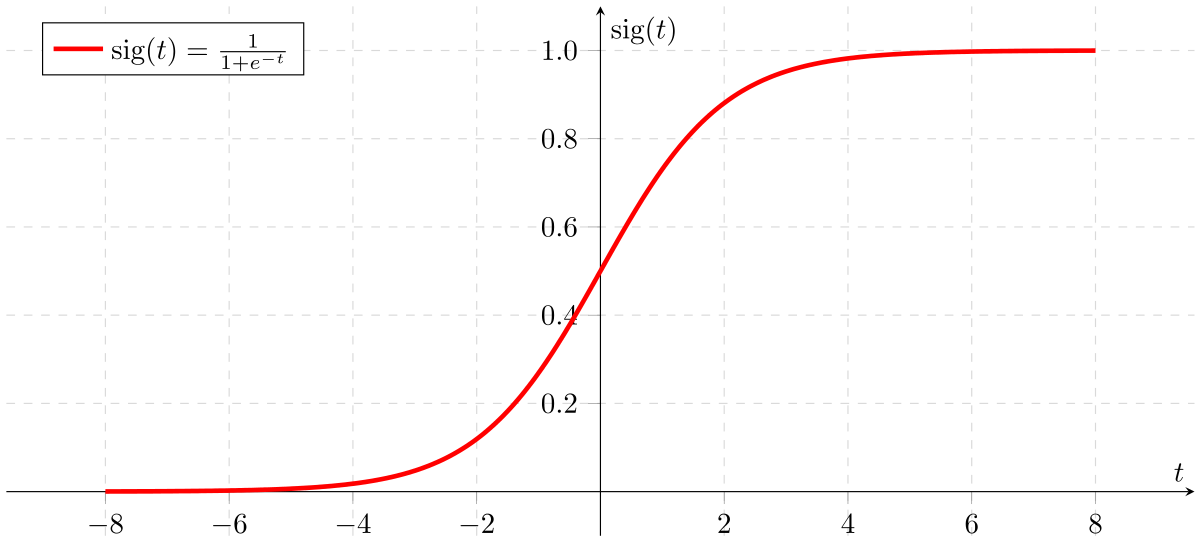
- La régression logistique prédit une réponse binaire à partir de variables explicatives