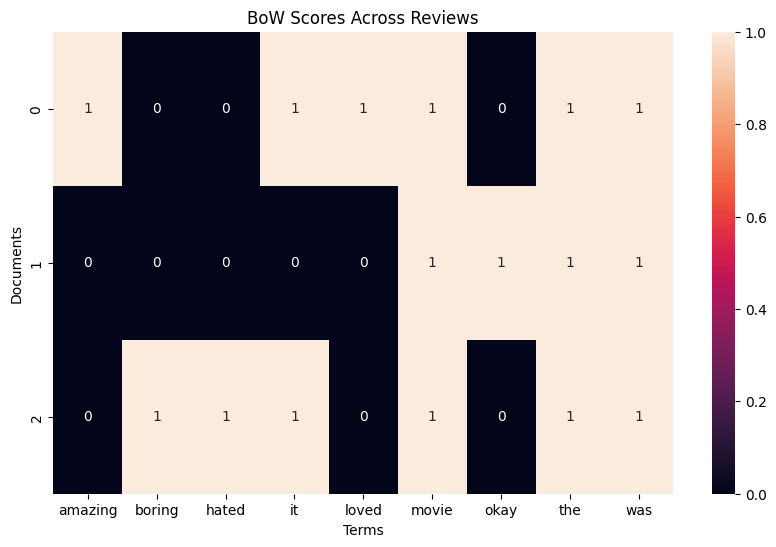
TF-IDF vectorization
Natural Language Processing (NLP) in Python

Fouad Trad
Machine Learning Engineer
From BoW to TF-IDF
- BoW treats all words as equally important
- TF-IDF fixes this by telling:
- how often a word appears in a document
- how meaningful that word is across a collection

TF-IDF

TF-IDF
- TF: Term Frequency
- How many times a word appears in a document
TF-IDF
- TF: Term Frequency
- How many times a word appears in a document
- IDF: Inverse Document Frequency
- How rare that word is across all documents
- Word shows up in one document, not in others → high score
- Word appears in every document → low score
Visualizing scores as heatmap
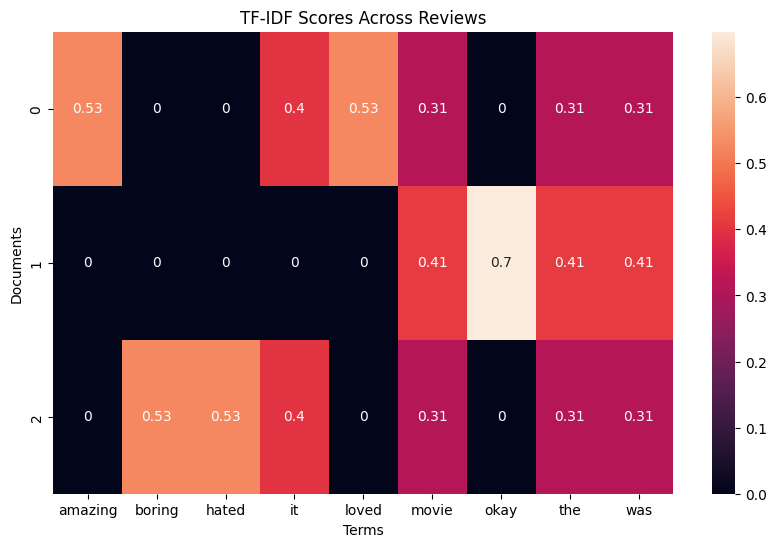
Comparing with BoW