Embeddings
Natural Language Processing (NLP) in Python

Fouad Trad
Machine Learning Engineer
Limitations of BoW and TF-IDF
- Treating similar words as completely unrelated
- Failing to capture meaning of text

Embeddings
- Represent a word with a vector that captures its meaning
Embeddings
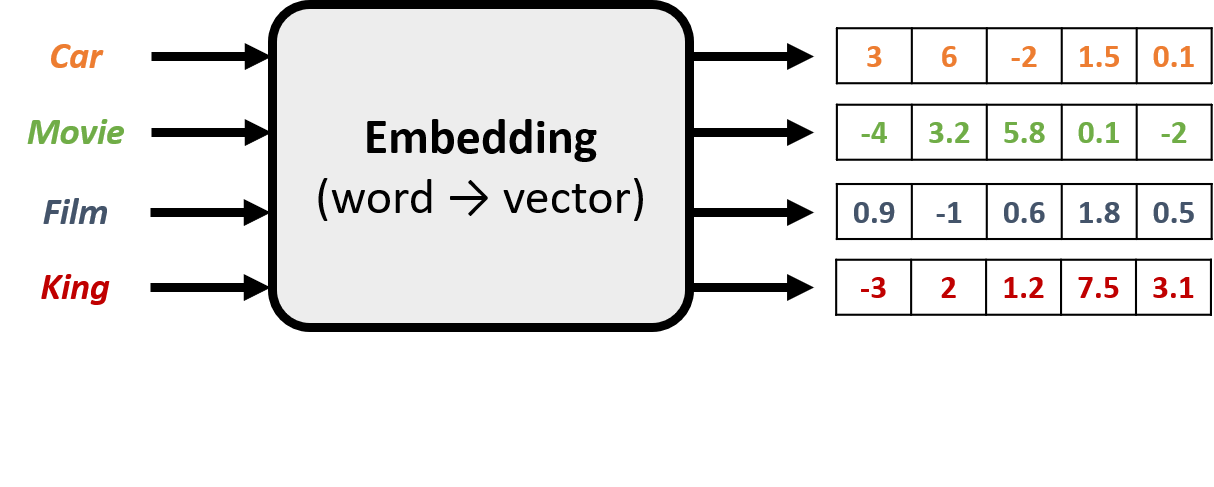
- Represent a word with a vector that captures its meaning
- Assigns random values to each word
Embeddings

- Represent a word with a vector that captures its meaning
- Assigns random values to each word
- Refines values by predicting missing words in sentences
Embeddings
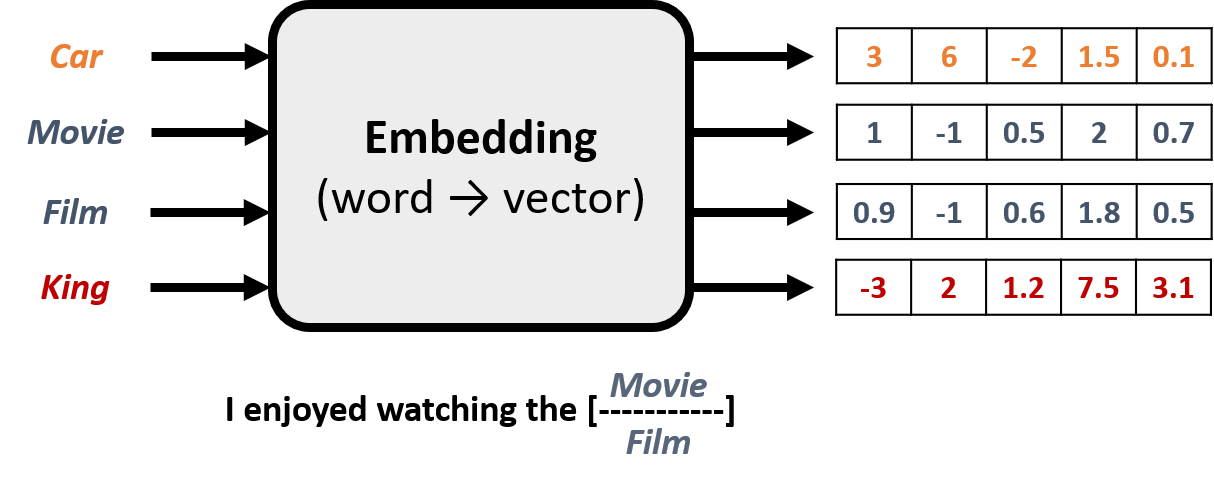
- Represent a word with a vector that captures its meaning
- Assigns random values to each word
- Refines values by predicting missing words in sentences
- Words appearing in similar contexts end up with similar representations
Embeddings as GPS coordinates for words
Gensim
![]()
Visualizing embeddings
- Principal Component Analysis (PCA):
- High-dimensional vectors → 2D or 3D vectors

1 Image generated by DALL-E
Visualizing embeddings with PCA
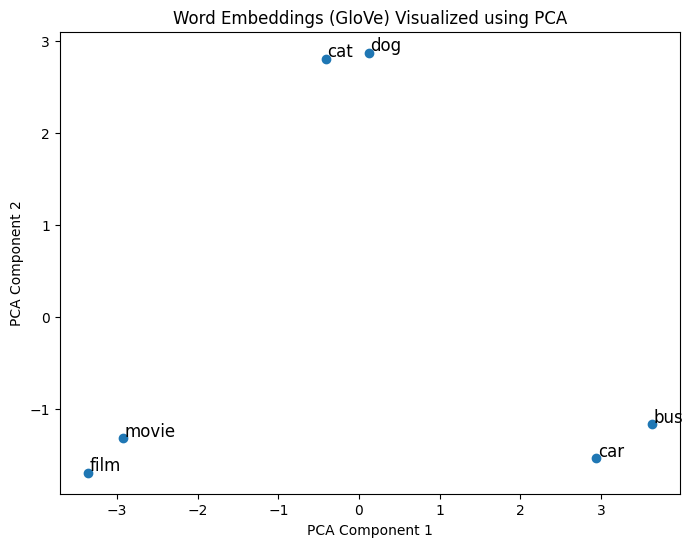
Comparison of embeddings
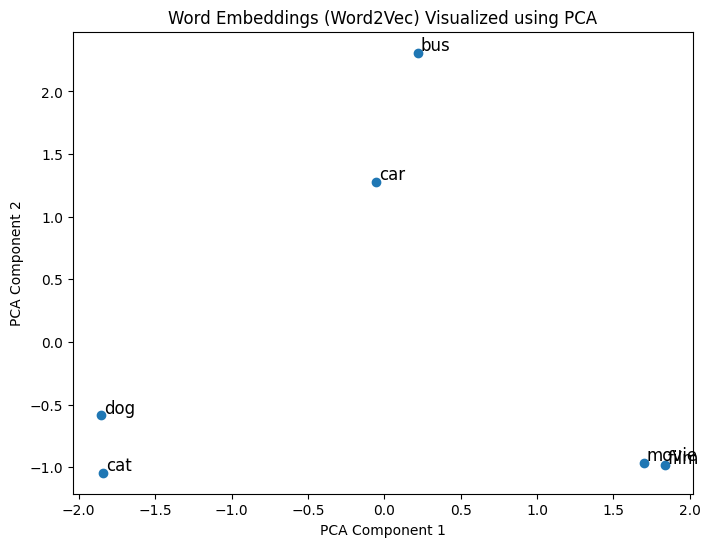
word2vec-google-news-300
glove-wiki-gigaword-50

