Bag-of-Words representation
Natural Language Processing (NLP) in Python

Fouad Trad
Machine Learning Engineer
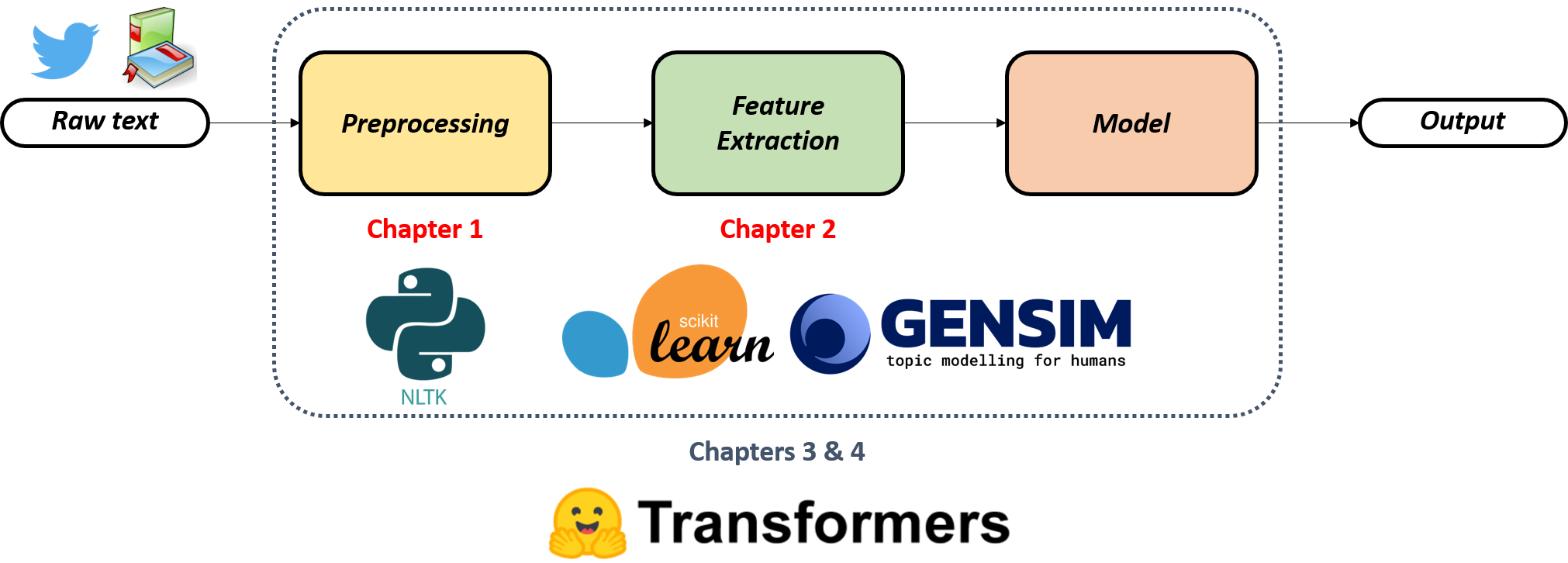
NLP workflow recap
Bag-of-Words (BoW)
- Foundational technique to represent text as numbers
- Represent text by counting how often each word appears
- Throws words in a bag and counts them
- Ignores grammar and order

BoW example

BoW example
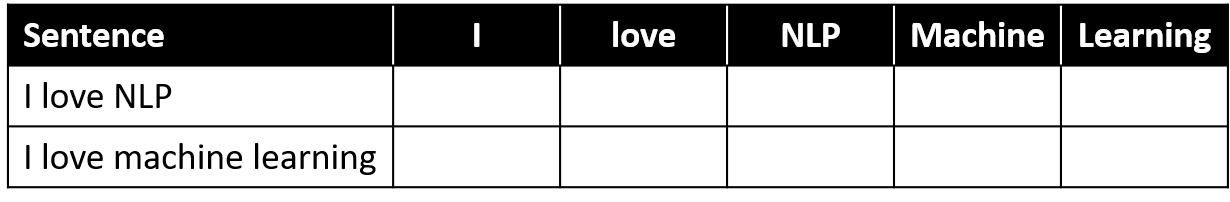
- Build a vocabulary of all unique words
BoW example

- Build a vocabulary of all unique words
- Count how many times each word from the vocabulary appears
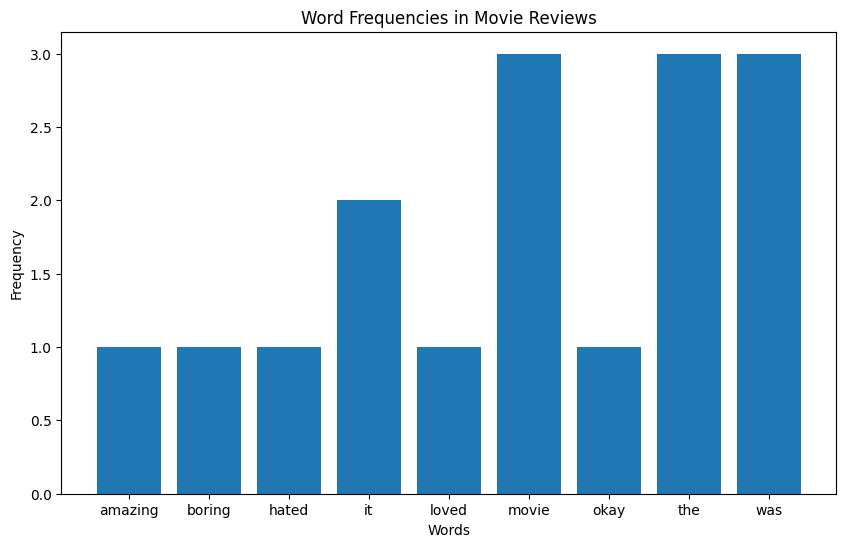
Word frequencies