Case study: S&P500 price simulation
Manipulating Time Series Data in Python

Stefan Jansen
Founder & Lead Data Scientist at Applied Artificial Intelligence
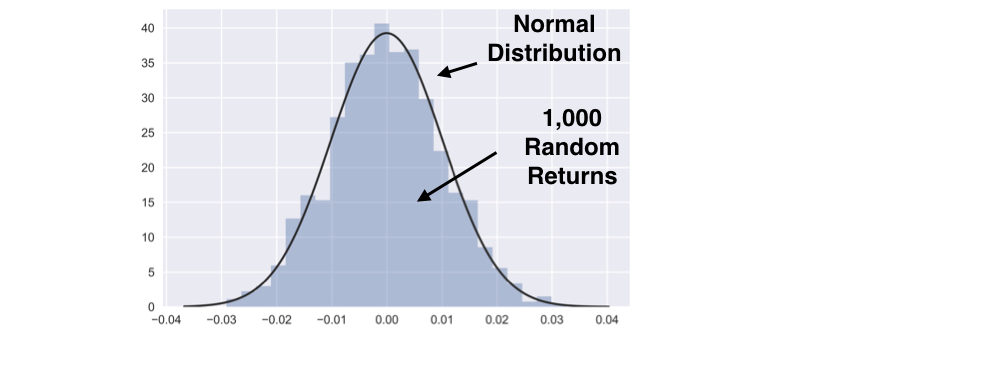
Generate random numbers
from numpy.random import normal, seedfrom scipy.stats import normseed(42)random_returns = normal(loc=0, scale=0.01, size=1000)sns.distplot(random_returns, fit=norm, kde=False)
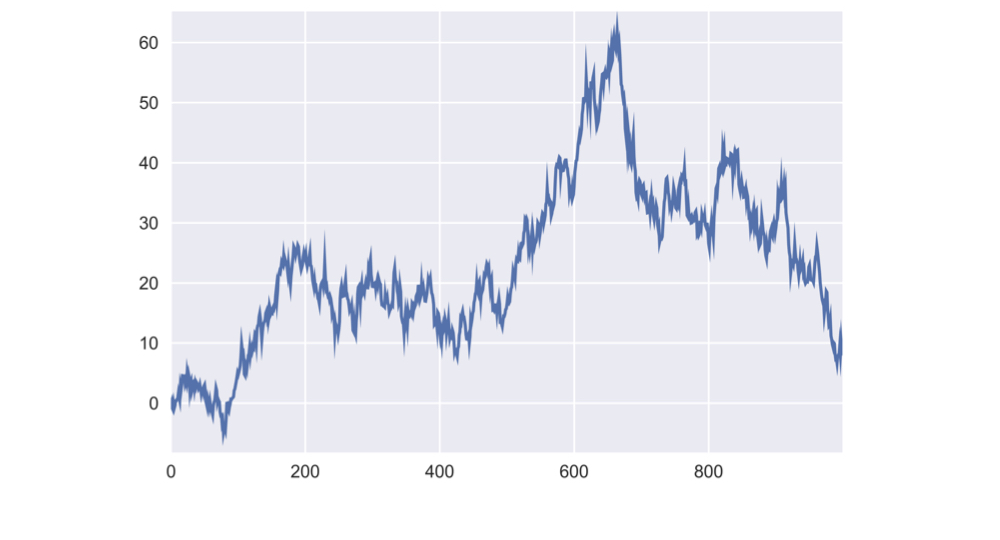
Create a random price path
return_series = pd.Series(random_returns)random_prices = return_series.add(1).cumprod().sub(1)random_prices.mul(100).plot()
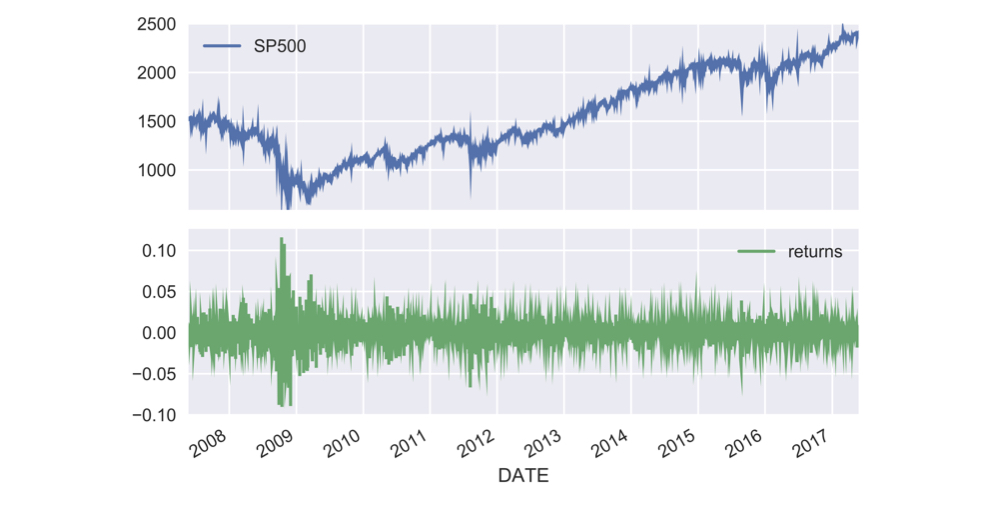
S&P 500 prices & returns
data = pd.read_csv('sp500.csv', parse_dates=['date'], index_col='date')data['returns'] = data.SP500.pct_change()data.plot(subplots=True)
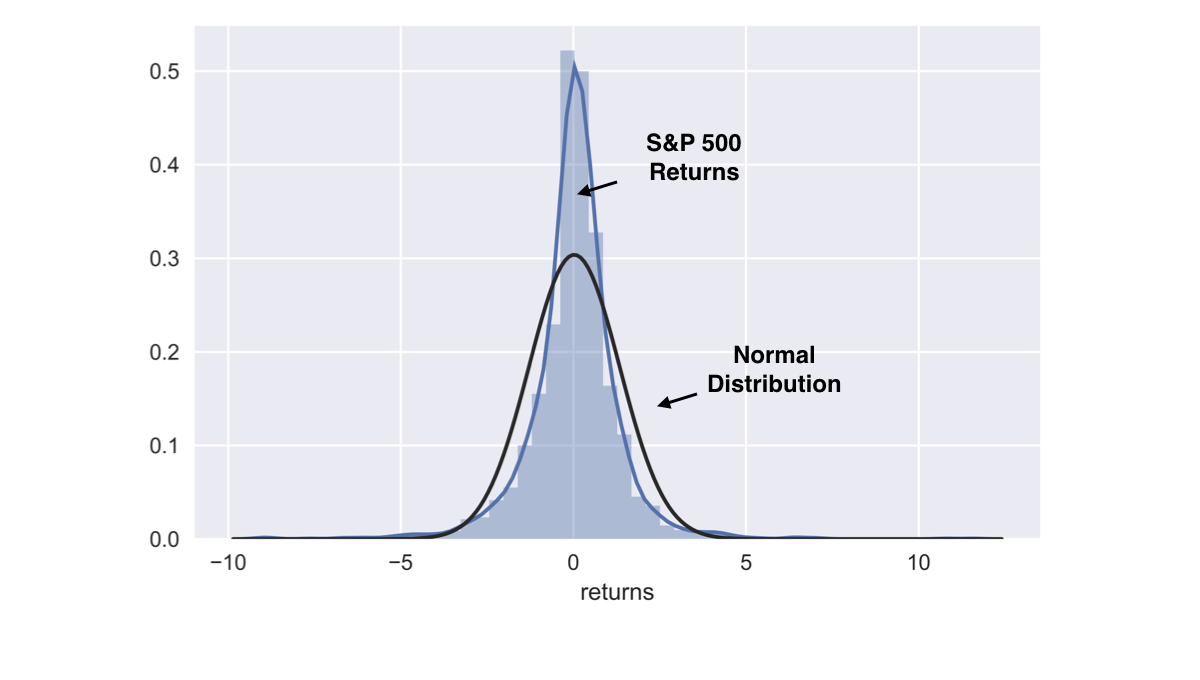
S&P return distribution
sns.distplot(data.returns.dropna().mul(100), fit=norm)
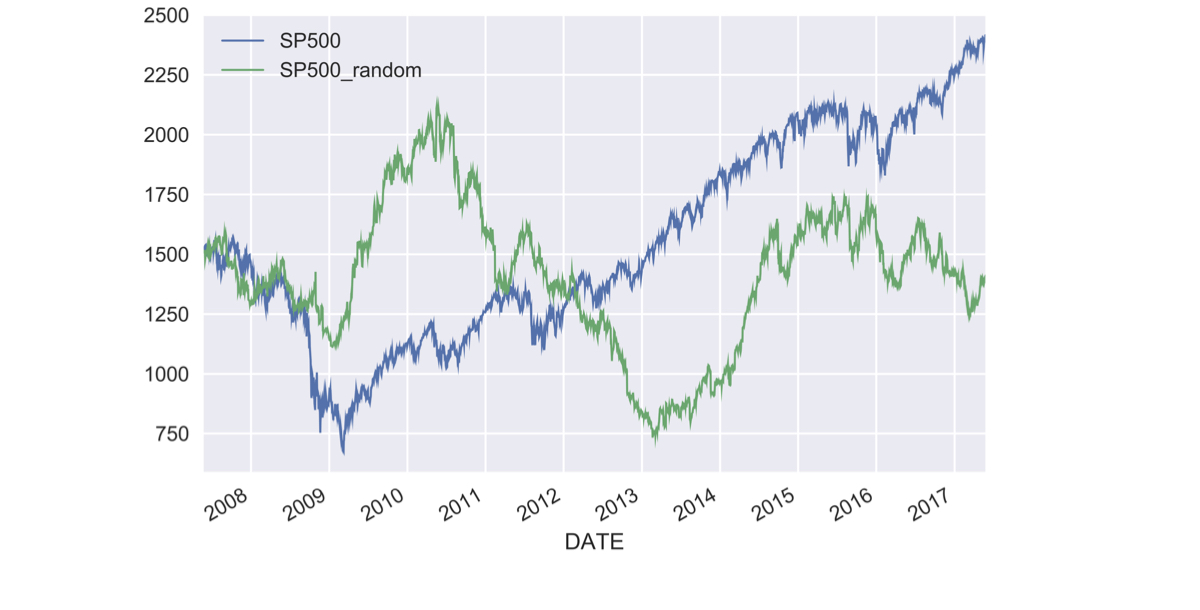
Random S&P 500 prices (2)
data['SP500_random'] = sp500_random.cumprod()data[['SP500', 'SP500_random']].plot()