Upsampling & interpolation with .resample()
Manipulating Time Series Data in Python

Stefan Jansen
Founder & Lead Data Scientist at Applied Artificial Intelligence
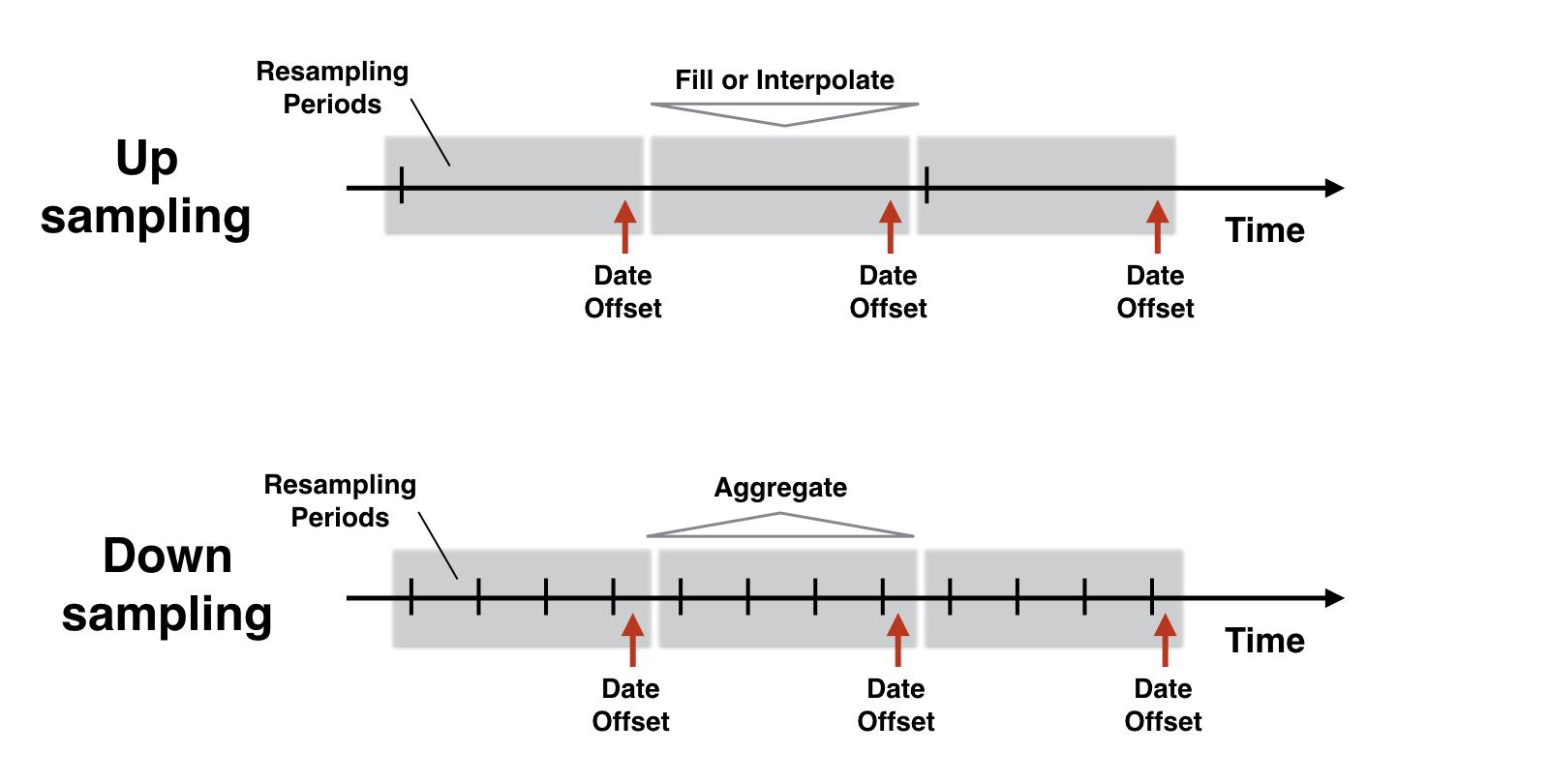
Resampling logic
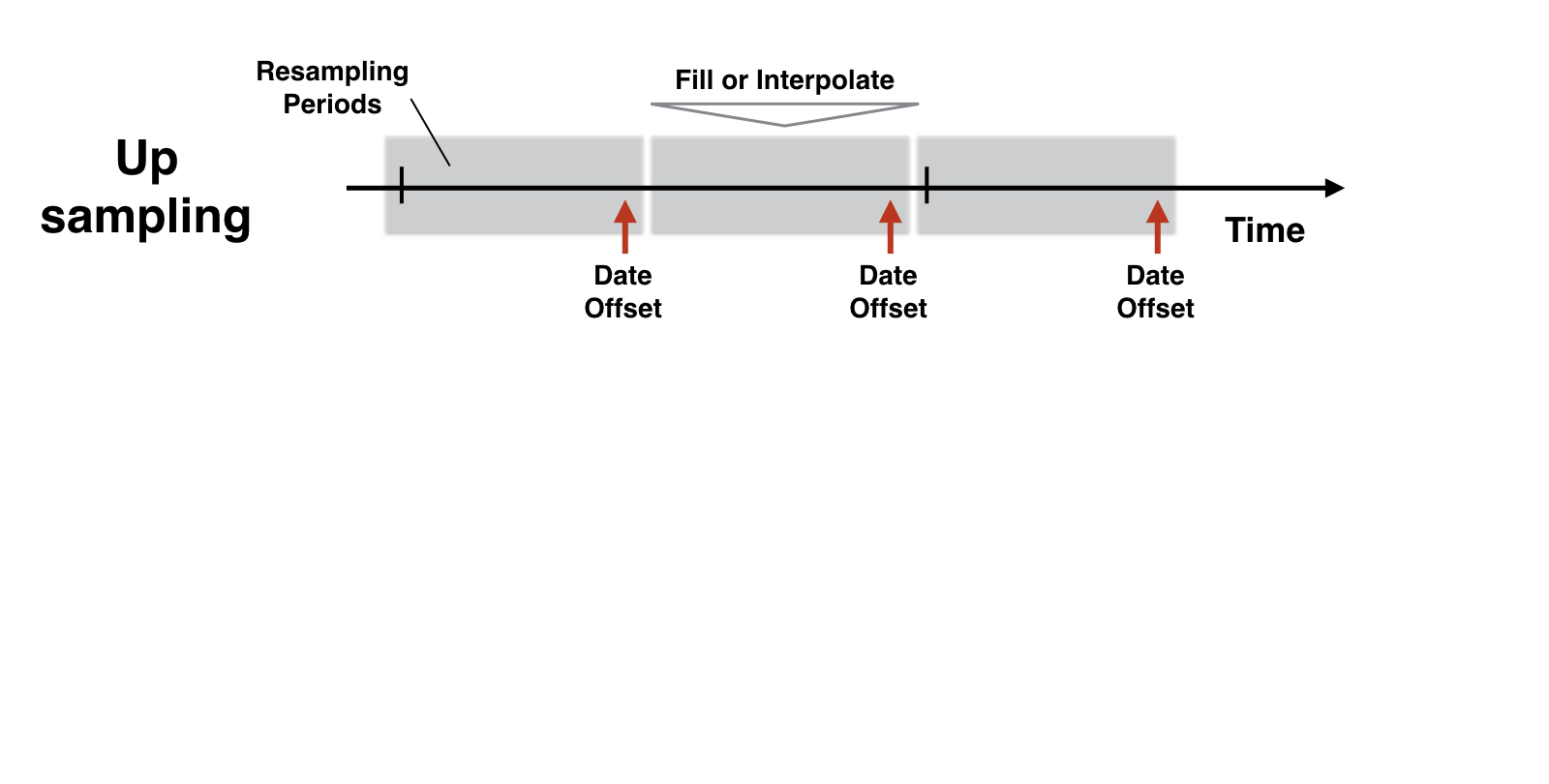
Resampling logic
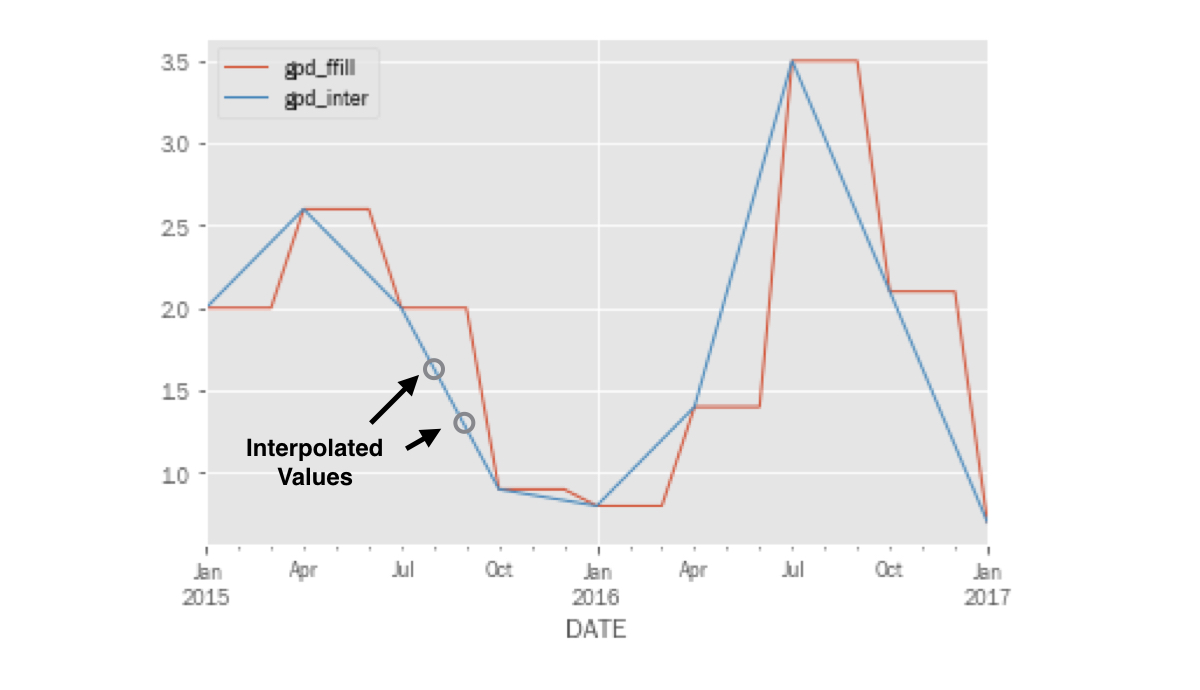
Plot interpolated real GDP growth
pd.concat([gdp_1, gdp_2], axis=1).loc['2015':].plot()
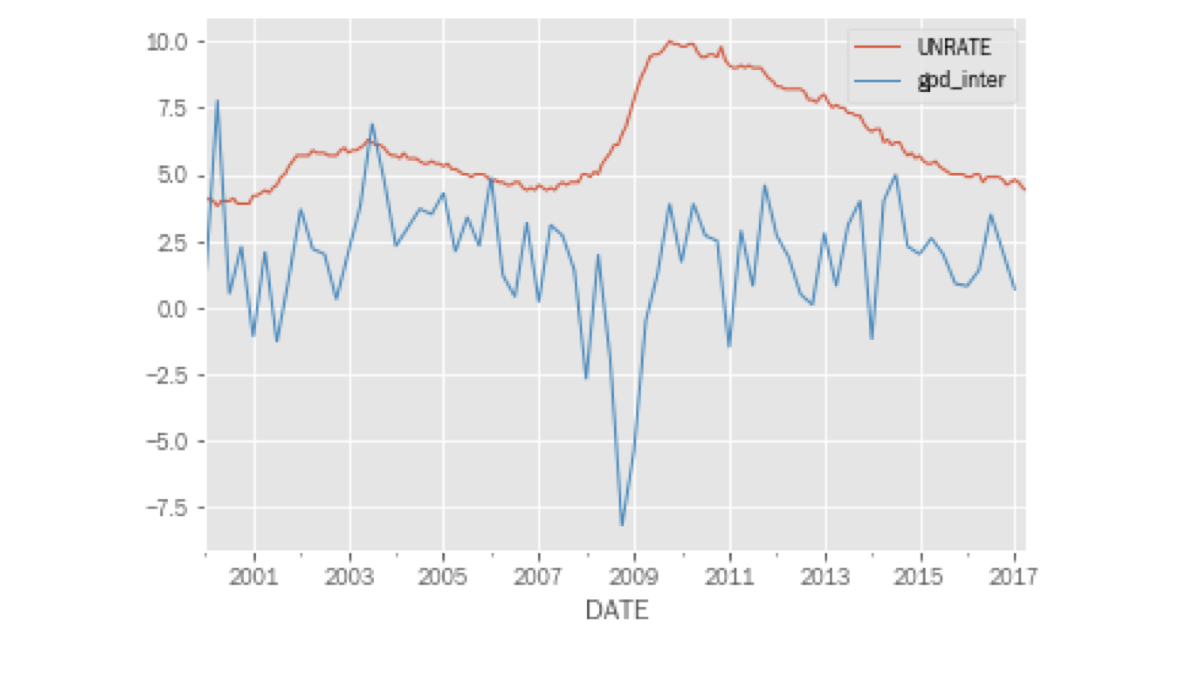
Combine GDP growth & unemployment
pd.concat([unrate, gdp_inter], axis=1).plot();