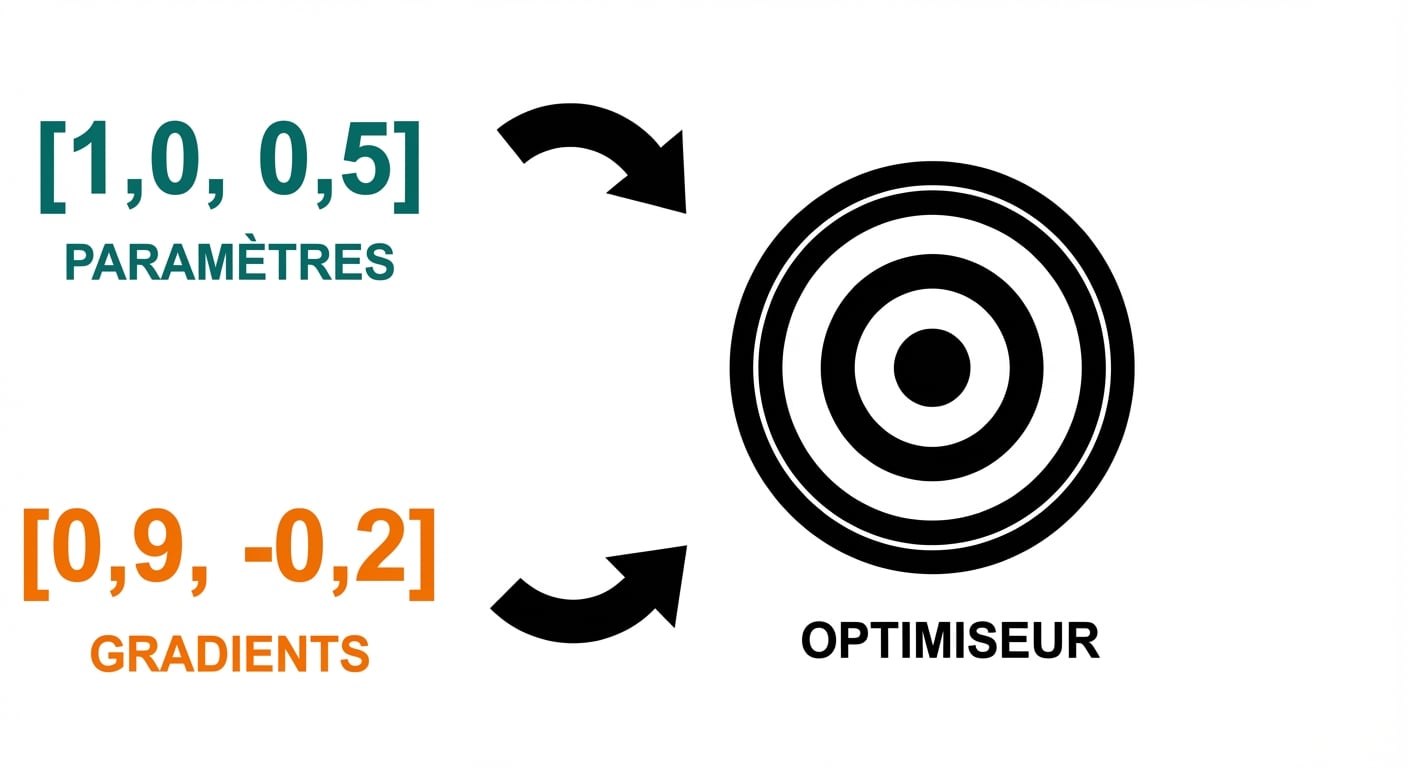
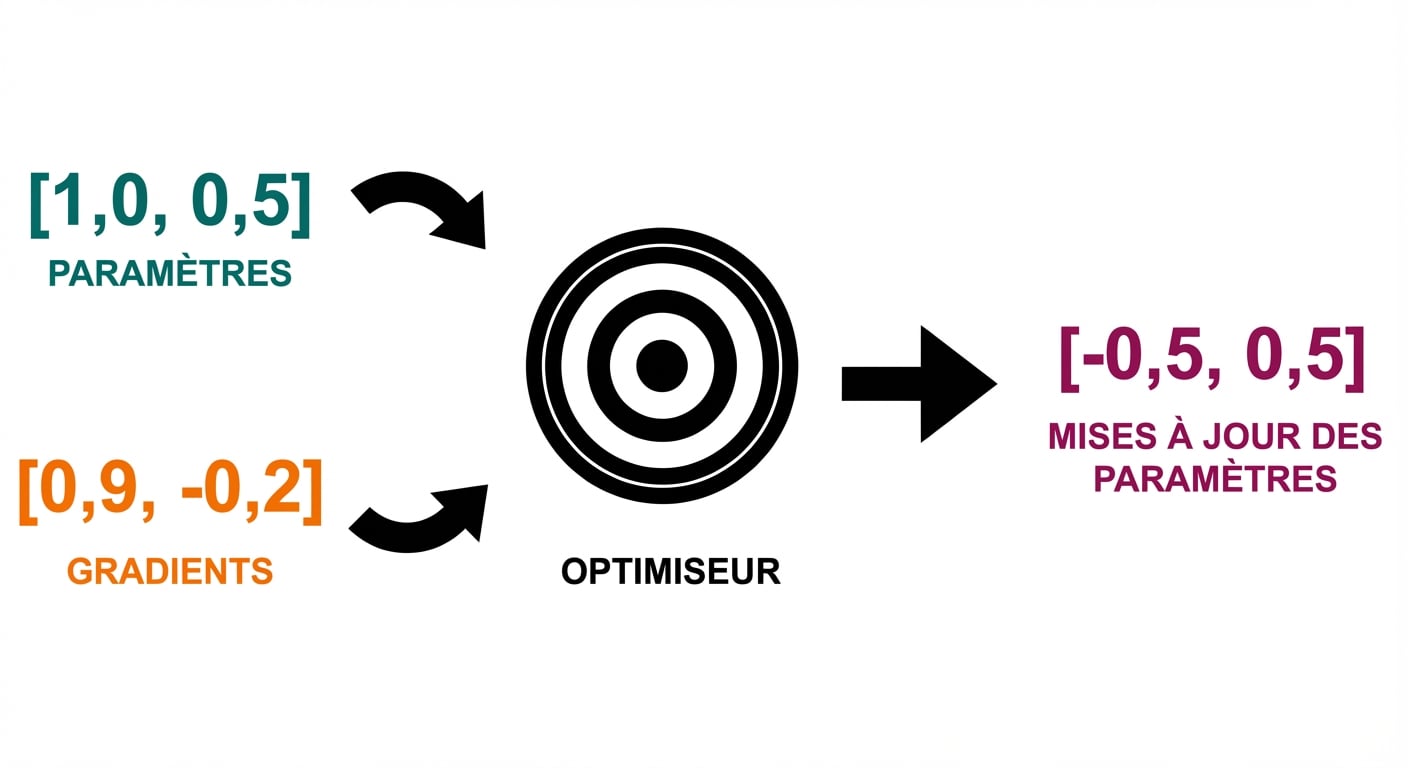
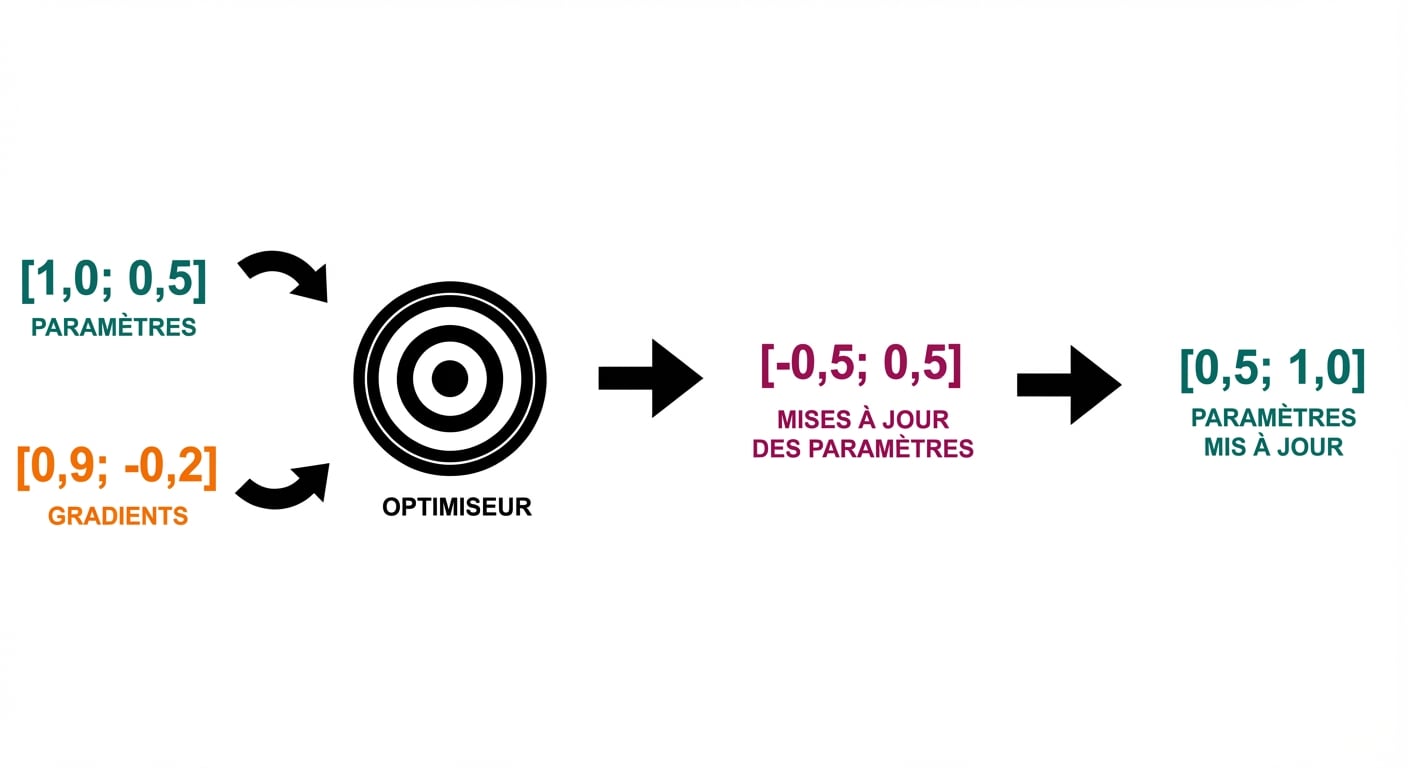
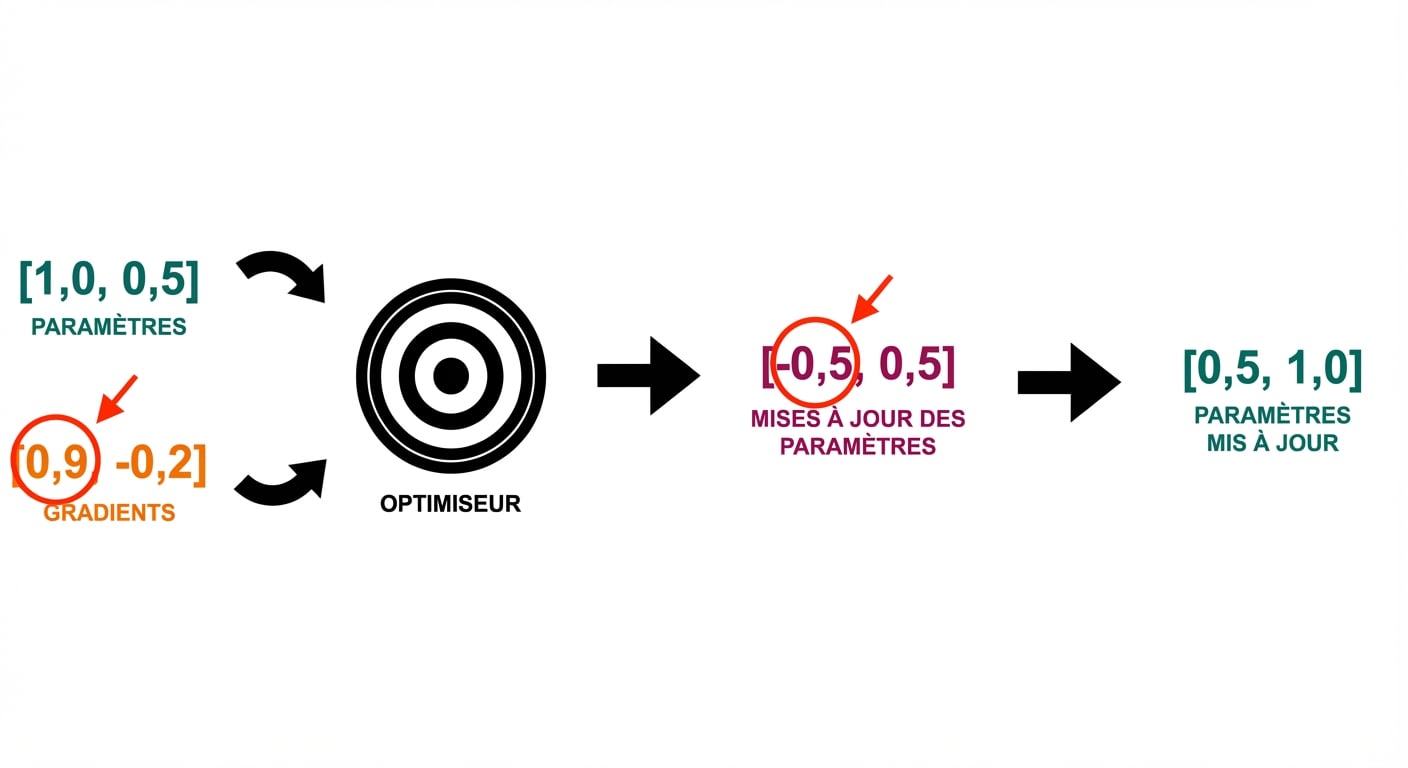
Boucle d’entraînement
import torch.nn as nn
import torch.optim as optim
criterion = nn.BCELoss()
optimizer = optim.SGD(net.parameters(), lr=0.01)
for epoch in range(1000):
for features, labels in dataloader_train:
optimizer.zero_grad()
outputs = net(features)
loss = criterion(
outputs, labels.view(-1, 1)
)
loss.backward()
optimizer.step()
- Définir la fonction de perte et l’optimiseur
BCELoss pour classification binaire- Optimiseur
SGD
- Itérer sur les époques et les lots d’entraînement
- Réinitialiser les gradients
- Passage avant : obtenir les sorties du modèle
- Calculer la perte
- Calculer les gradients
- Pas de l’optimiseur : mise à jour des paramètres